Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
作者: Sonam Gupta, Yatin Nandwani, Asaf Yehudai, Mayank Mishra, Gaurav Pandey, Dinesh Raghu, Sachindra Joshi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-07
备注: 14 pages, 8 figures
💡 一句话要点
提出选择性自复现(SSR)微调方法,提升大语言模型泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调 泛化能力 自复现 选择性学习
📋 核心要点
- 标准监督微调(SFT)虽然能提升特定任务性能,但容易过拟合,导致泛化能力下降。
- 选择性自复现(SSR)利用模型自身生成的正确答案进行微调,减少模型对训练数据的过度特化。
- 实验表明,SSR在保持性能的同时,显著提升了模型在多个基准测试上的泛化能力。
📝 摘要(中文)
本文提出了一种名为选择性自复现(SSR)的微调方法,旨在提高大型语言模型(LLM)的泛化能力,同时保持与标准监督微调(SFT)相当的性能。SSR的核心思想是利用模型对同一查询可能存在多个有效响应的特性,通过利用模型自身的正确响应来减少微调过程中的模型特化。该方法首先部署一个合适的LLM作为裁判,从训练集中识别出正确的模型响应,然后使用这些正确的模型响应以及剩余样本的黄金响应来微调模型。在识别无法回答的查询任务上的实验结果表明,标准SFT可能导致在MMLU和TruthfulQA等多个基准测试中平均性能下降高达16.7%,而SSR的平均性能下降接近2%,表明其具有比标准SFT更好的泛化能力。
🔬 方法详解
问题定义:现有的大型语言模型在特定数据集上进行微调后,虽然在目标任务上表现提升,但往往会过度拟合训练数据,导致模型泛化能力下降。这种过度特化使得模型在面对新的、未见过的数据时表现不佳,限制了其在实际应用中的效果。
核心思路:论文的核心思路是利用大型语言模型对同一问题可能存在多个正确答案的特性,通过让模型学习自己生成的正确答案,来减少模型在微调过程中对特定训练数据的过度依赖,从而提升模型的泛化能力。这样设计的目的是让模型学习更通用的知识,而不是仅仅记住训练数据。
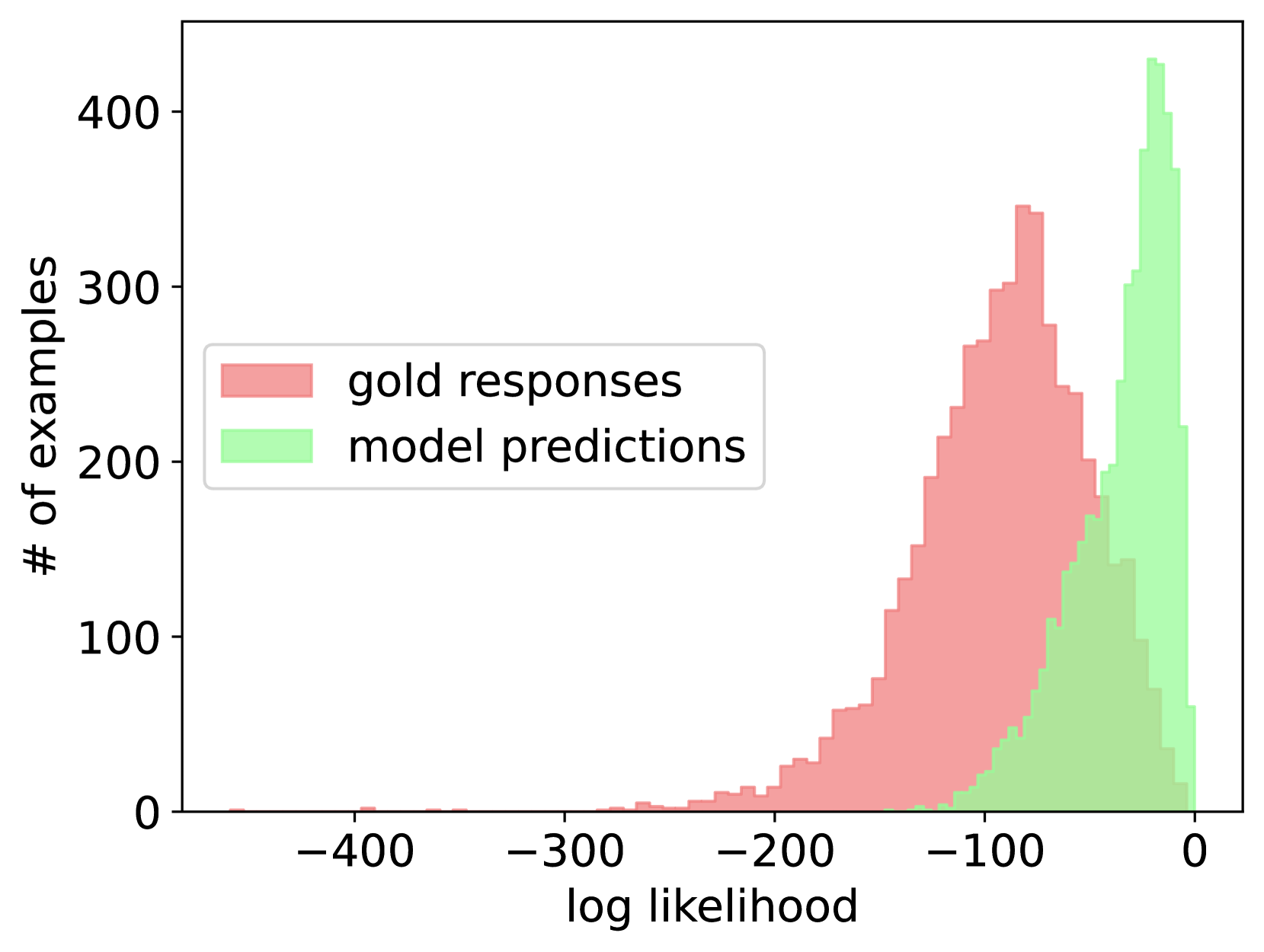
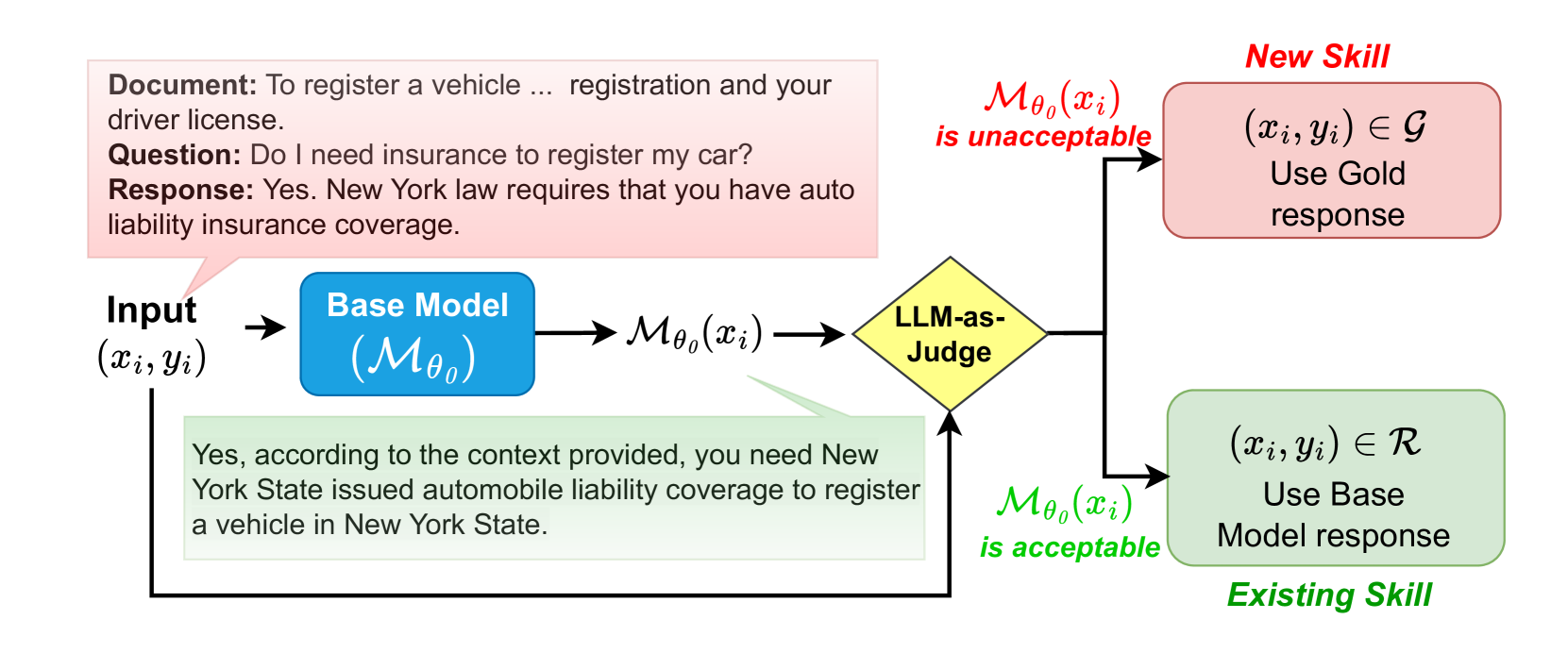
技术框架:SSR方法主要包含两个阶段:1) 正确响应识别阶段:使用一个预训练的LLM作为裁判,对训练数据集中每个问题的模型响应进行评估,判断其是否为正确的响应。2) 选择性微调阶段:对于那些模型能够生成正确响应的问题,使用模型自身的正确响应进行微调;对于其他问题,则使用标准的黄金响应进行微调。
关键创新:SSR的关键创新在于它不是简单地使用人工标注的黄金响应进行微调,而是充分利用了模型自身的能力,让模型学习自己生成的正确答案。这种自学习的方式能够更好地保留模型原有的泛化能力,并减少对特定训练数据的过度拟合。与传统的SFT方法相比,SSR更加注重利用模型自身的知识,而不是仅仅依赖于外部数据。
关键设计:在正确响应识别阶段,需要选择一个合适的LLM作为裁判,并设计合理的评估标准来判断模型响应的正确性。在选择性微调阶段,需要平衡使用模型自身响应和黄金响应的比例,以达到最佳的泛化效果。具体的参数设置和损失函数选择可能需要根据不同的任务和数据集进行调整。论文中可能使用了交叉熵损失函数,并对不同类型的响应设置了不同的权重。
🖼️ 关键图片
📊 实验亮点
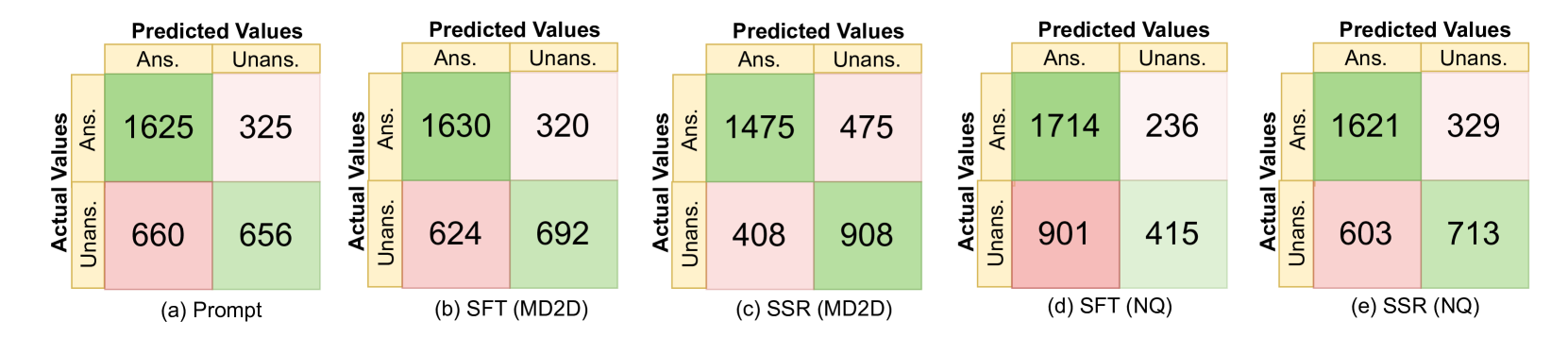
实验结果表明,标准SFT在MMLU和TruthfulQA等多个基准测试中导致平均性能下降高达16.7%,而SSR方法仅导致平均性能下降约2%。这表明SSR在保持性能的同时,显著提升了模型的泛化能力。此外,实验还验证了SSR在识别无法回答的查询任务上的有效性。
🎯 应用场景
该研究成果可广泛应用于需要提升大型语言模型泛化能力的场景,例如问答系统、对话生成、文本摘要等。通过使用SSR方法,可以有效避免模型在特定数据集上的过拟合,使其在面对真实世界的复杂数据时表现更加稳定和可靠。此外,该方法还可以用于提升模型在少样本学习和零样本学习场景下的性能。
📄 摘要(原文)
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.