Customizing Large Language Model Generation Style using Parameter-Efficient Finetuning
作者: Xinyue Liu, Harshita Diddee, Daphne Ippolito
分类: cs.CL
发布日期: 2024-09-06
💡 一句话要点
利用参数高效微调定制大语言模型的生成风格
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 风格迁移 低秩适应 LLaMA-2
📋 核心要点
- 现有的大型语言模型风格单一,难以满足不同用户的个性化写作需求,限制了其作为写作助手的应用。
- 论文提出利用参数高效微调(PEFT)方法,特别是低秩适应(LoRA),来定制LLM的生成风格,使其更贴近特定用户的写作习惯。
- 实验结果表明,该方法能够使LLM生成的文本在词汇、句法和表面特征上与目标作者对齐,证明了PEFT在风格定制方面的有效性。
📝 摘要(中文)
大型语言模型(LLM)正日益普及,用于辅助人们的写作。然而,这些模型训练形成的写作风格可能并不适合所有用户或用例。如果LLM的个人风格能够定制以匹配每个用户,那么它们作为写作助手将更有用。本文探讨了使用低秩适应(LoRA)的参数高效微调(PEFT)是否能有效地引导LLM的生成风格。我们使用这种方法将LLaMA-2定制为十位不同作者的风格,并表明生成的文本在词汇、句法和表面特征上与目标作者对齐,但在内容记忆方面存在困难。我们的研究结果突出了PEFT在支持LLM高效、用户级别定制方面的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成风格的个性化定制问题。现有LLM的生成风格通常是通用的,无法满足不同用户的特定写作风格需求。这限制了LLM在写作辅助等场景中的应用,用户需要花费大量精力修改LLM的输出以符合自己的风格。
核心思路:论文的核心思路是利用参数高效微调(PEFT)技术,特别是低秩适应(LoRA),来在预训练LLM的基础上进行风格迁移。通过在少量数据上微调LLM,使其生成风格向目标作者的风格靠拢。这种方法避免了对整个LLM进行微调,从而降低了计算成本和存储需求。
技术框架:整体流程包括以下几个步骤:1)收集目标作者的写作样本;2)使用LoRA对预训练的LLaMA-2模型进行微调,使其适应目标作者的写作风格;3)使用微调后的LLM生成文本;4)评估生成文本与目标作者风格的相似度。主要模块包括数据收集模块、LoRA微调模块和评估模块。
关键创新:论文的关键创新在于将参数高效微调(PEFT)技术应用于LLM的风格定制。与传统的全参数微调相比,PEFT只需要微调少量参数,从而大大降低了计算成本和存储需求。此外,论文还探索了LoRA在风格定制方面的有效性,并验证了其在词汇、句法和表面特征对齐方面的能力。
关键设计:论文使用了LLaMA-2作为预训练模型,并采用LoRA进行微调。LoRA通过在预训练模型的权重矩阵旁添加低秩矩阵来实现参数高效微调。具体来说,LoRA将原始权重矩阵分解为两个低秩矩阵的乘积,并在微调过程中只更新这两个低秩矩阵。论文没有详细说明具体的损失函数,但推测使用了常见的语言模型损失函数,例如交叉熵损失。
🖼️ 关键图片
📊 实验亮点
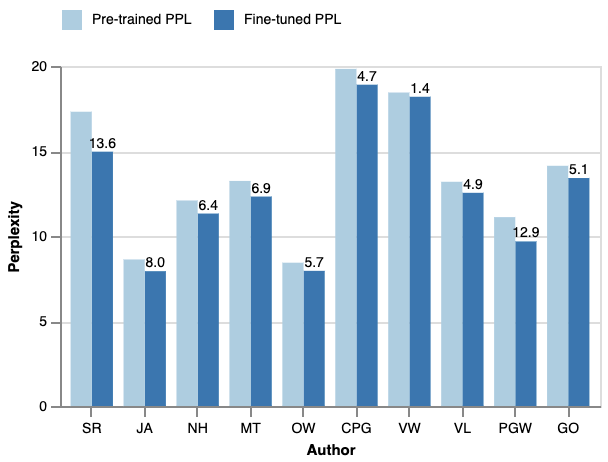
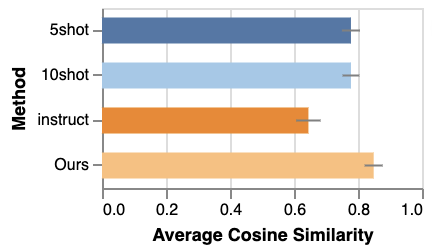
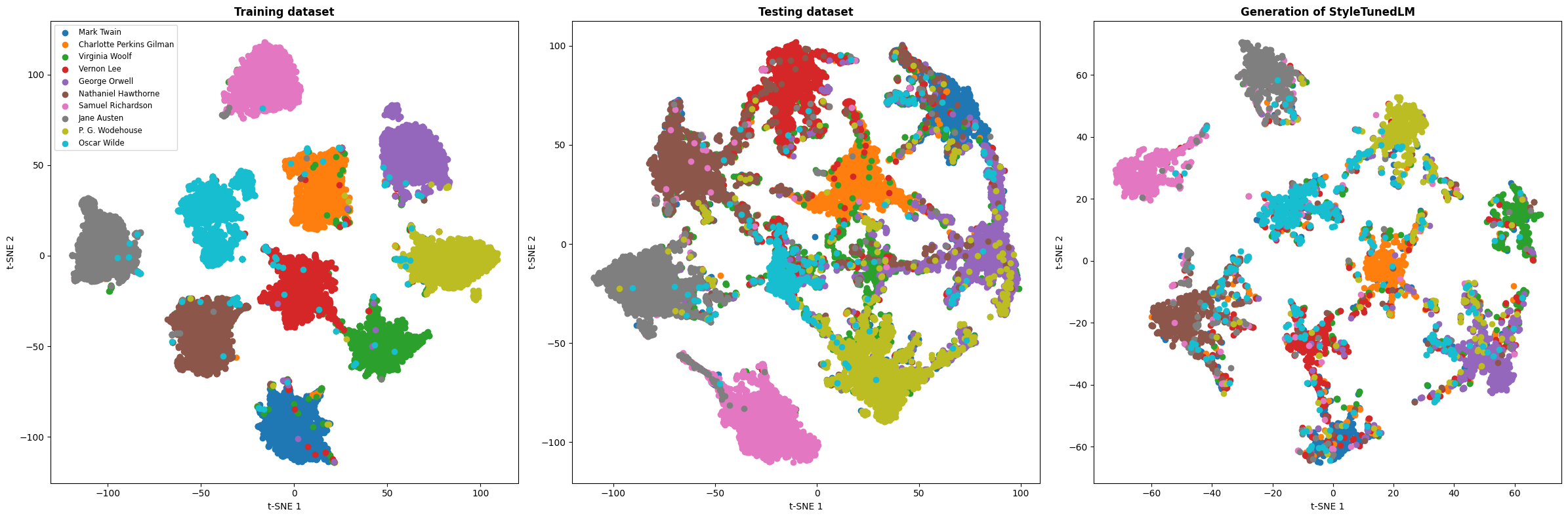
实验结果表明,使用PEFT方法微调后的LLaMA-2模型能够生成在词汇、句法和表面特征上与目标作者对齐的文本。虽然模型在内容记忆方面存在困难,但风格迁移的效果显著。这验证了PEFT在LLM风格定制方面的有效性,并为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于个性化写作辅助、内容生成、风格迁移等领域。例如,用户可以使用该方法定制LLM的写作风格,使其更符合自己的写作习惯,从而提高写作效率。此外,该方法还可以用于生成特定风格的文章、小说等内容,满足不同用户的需求。未来,该技术有望应用于更广泛的领域,例如教育、娱乐等。
📄 摘要(原文)
One-size-fits-all large language models (LLMs) are increasingly being used to help people with their writing. However, the style these models are trained to write in may not suit all users or use cases. LLMs would be more useful as writing assistants if their idiolect could be customized to match each user. In this paper, we explore whether parameter-efficient finetuning (PEFT) with Low-Rank Adaptation can effectively guide the style of LLM generations. We use this method to customize LLaMA-2 to ten different authors and show that the generated text has lexical, syntactic, and surface alignment with the target author but struggles with content memorization. Our findings highlight the potential of PEFT to support efficient, user-level customization of LLMs.