GALLa: Graph Aligned Large Language Models for Improved Source Code Understanding
作者: Ziyin Zhang, Hang Yu, Shijie Li, Peng Di, Jianguo Li, Rui Wang
分类: cs.CL, cs.AI
发布日期: 2024-09-06 (更新: 2025-09-23)
备注: ACL 2025
💡 一句话要点
GALLa:图对齐大语言模型,提升源代码理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码理解 大语言模型 图神经网络 跨模态对齐 源代码分析 代码表示学习 辅助任务
📋 核心要点
- 现有代码语言模型忽略了源代码的结构信息,而编码结构信息的模型又难以扩展规模并与预训练LLM兼容。
- GALLa利用图神经网络和跨模态对齐技术,在微调阶段将代码的结构信息注入到LLM中,作为辅助任务。
- 实验结果表明,GALLa在多个代码任务和不同规模的LLM上均能稳定提升性能,包括LLaMA3和Qwen2.5-Coder。
📝 摘要(中文)
编程语言蕴含丰富语义信息,例如数据流,这些信息以图的形式表示,而源代码的表面形式无法直接获取。现有的代码语言模型虽然扩展到数十亿参数,但仅将源代码视为文本token,忽略了其他结构信息。另一方面,能够编码代码结构信息的模型通常需要修改Transformer架构,限制了其规模和与预训练LLM的兼容性。本文提出了GALLa(Graph Aligned Large Language Models),结合了两者的优点。GALLa利用图神经网络和跨模态对齐技术,在微调期间将代码的结构信息作为辅助任务注入到LLM中。该框架具有模型无关性和任务无关性,可以应用于任何代码LLM,用于任何代码下游任务,并且仅在训练时需要来自与微调数据无关的语料库的结构图数据,在推理时不会增加任何成本。在五个代码任务上,使用七个不同的基线LLM(规模从350M到14B)进行的实验验证了GALLa的有效性,证明了相对于基线的持续改进,即使对于像LLaMA3和Qwen2.5-Coder这样强大的模型也是如此。
🔬 方法详解
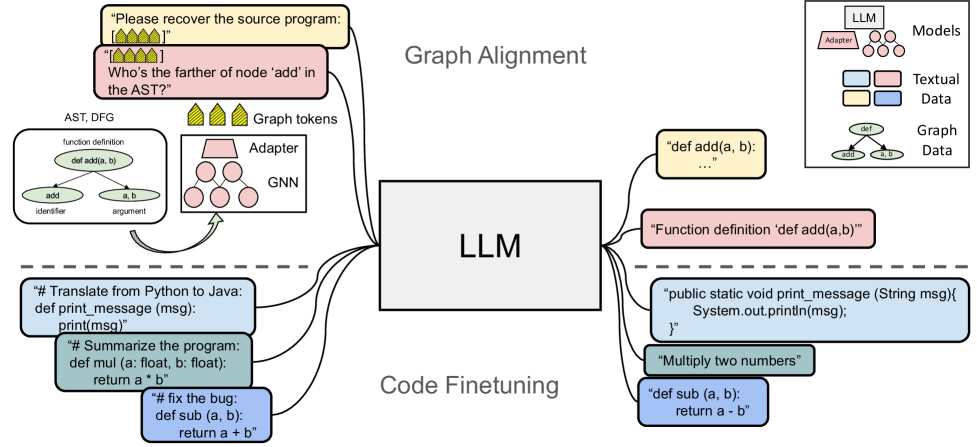
问题定义:现有代码语言模型主要将代码视为纯文本序列,忽略了代码中蕴含的丰富的结构化信息,例如数据流、控制流等。这些结构化信息通常以图的形式表示,对于代码理解至关重要。另一方面,一些尝试将结构信息融入模型的方案,往往需要修改Transformer架构,导致模型难以扩展到更大的规模,并且难以直接利用已有的预训练大语言模型。
核心思路:GALLa的核心思路是在不修改现有LLM架构的前提下,通过图神经网络(GNN)提取代码的结构化信息,并利用跨模态对齐技术,将这些结构化信息注入到LLM中。具体来说,GALLa将GNN提取的图表示与LLM的文本表示对齐,使得LLM能够学习到代码的结构信息,从而提升代码理解能力。这种方法的优势在于,可以充分利用预训练LLM的强大能力,同时又能融入代码的结构信息。
技术框架:GALLa的技术框架主要包含两个模块:图神经网络(GNN)模块和跨模态对齐模块。首先,GNN模块负责从源代码的抽象语法树(AST)或其他图表示中提取结构化信息,生成图嵌入。然后,跨模态对齐模块将GNN生成的图嵌入与LLM的文本嵌入进行对齐。对齐过程通常通过一个辅助任务来实现,例如预测图中的节点之间的关系。在微调阶段,LLM和GNN共同训练,使得LLM能够学习到代码的结构信息。在推理阶段,只需要使用微调后的LLM即可,无需GNN模块,因此不会增加推理成本。
关键创新:GALLa的关键创新在于提出了一种模型无关且任务无关的框架,可以将代码的结构信息注入到任何代码LLM中,用于任何代码下游任务。与现有方法相比,GALLa不需要修改LLM的架构,因此可以充分利用预训练LLM的强大能力。此外,GALLa的训练过程只需要结构图数据,而不需要与下游任务相关的数据,因此具有很强的灵活性。
关键设计:GALLa的关键设计包括GNN的选择、跨模态对齐方法和辅助任务的设计。GNN可以选择不同的图神经网络架构,例如GCN、GAT等。跨模态对齐方法可以选择不同的对齐损失函数,例如对比学习损失、交叉熵损失等。辅助任务的设计需要能够有效地将图信息传递给LLM,例如预测图中节点之间的关系、预测节点的属性等。论文中没有明确给出具体参数设置,损失函数和网络结构,这些细节可能根据具体的实验设置进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GALLa在五个代码任务上,使用七个不同的基线LLM(规模从350M到14B)均取得了显著的性能提升。即使对于像LLaMA3和Qwen2.5-Coder这样强大的模型,GALLa也能带来持续的改进。例如,在某些任务上,GALLa可以将性能提升几个百分点,证明了其有效性。
🎯 应用场景
GALLa具有广泛的应用前景,可以应用于代码生成、代码补全、代码搜索、代码缺陷检测等多个领域。通过提升代码理解能力,GALLa可以帮助开发者更高效地编写代码、更准确地定位代码缺陷,从而提高软件开发的效率和质量。未来,GALLa可以进一步扩展到其他编程语言和代码表示形式,并与其他代码分析工具相结合,为软件开发提供更强大的支持。
📄 摘要(原文)
Programming languages possess rich semantic information - such as data flow - that is represented by graphs and not available from the surface form of source code. Recent code language models have scaled to billions of parameters, but model source code solely as text tokens while ignoring any other structural information. Conversely, models that do encode structural information of code make modifications to the Transformer architecture, limiting their scale and compatibility with pretrained LLMs. In this work, we take the best of both worlds with GALLa - Graph Aligned Large Language Models. GALLa utilizes graph neural networks and cross-modal alignment technologies to inject the structural information of code into LLMs as an auxiliary task during finetuning. This framework is both model-agnostic and task-agnostic, as it can be applied to any code LLM for any code downstream task, and requires the structural graph data only at training time from a corpus unrelated to the finetuning data, while incurring no cost at inference time over the baseline LLM. Experiments on five code tasks with seven different baseline LLMs ranging in size from 350M to 14B validate the effectiveness of GALLa, demonstrating consistent improvement over the baseline, even for powerful models such as LLaMA3 and Qwen2.5-Coder.