Shaping the Future of Endangered and Low-Resource Languages -- Our Role in the Age of LLMs: A Keynote at ECIR 2024
作者: Josiane Mothe
分类: cs.CL, cs.IR
发布日期: 2024-09-05
期刊: Sigir Forum, 2024, 58 (1), pp.1-13
💡 一句话要点
探讨LLM时代保护濒危语言的机遇与挑战,以奥克语为例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 濒危语言保护 大型语言模型 语言多样性 文化传承 人机协作
📋 核心要点
- 濒危语言面临数字化资源不足和自动化工具匮乏的挑战,这阻碍了其保护和传承。
- 论文核心在于探讨如何利用LLM技术,在内容生成和翻译方面赋能濒危语言的保护工作。
- 以奥克语为例,研究探讨了人类专家与AI协作,在伦理框架下保护语言多样性的可行方案。
📝 摘要(中文)
这篇论文基于作者在第46届欧洲信息检索会议(ECIR 2024)上的主题演讲。演讲稿探讨了大型语言模型(LLM)技术在保护和复兴濒危语言方面的双重作用。一方面,LLM为翻译和生成内容提供了前所未有的可能性,这对于语言的保存至关重要。另一方面,LLM也带来了同质化、文化过度简化以及进一步边缘化弱势语言的风险。演讲以奥克语为例,探讨了技术与传统之间潜在的合作路径,以及如何利用人类专业知识和人工智能共同保护全球特别是欧洲的语言多样性,同时应对使用这些强大技术所带来的伦理和实践挑战。演讲的视频版本也可在线观看。
🔬 方法详解
问题定义:论文旨在探讨如何利用大型语言模型(LLM)来保护和复兴濒危语言。现有方法在处理濒危语言时面临数据稀缺、资源不足以及文化背景理解不足等问题,导致翻译质量不高,内容生成缺乏针对性,甚至可能加剧语言的同质化风险。
核心思路:论文的核心思路是结合人类语言学家的专业知识和LLM的强大能力,构建一个协作框架,以实现对濒危语言更有效、更负责任的保护。强调在利用技术的同时,必须充分考虑语言的文化背景和社会价值,避免过度简化和同质化。
技术框架:论文并未提出一个具体的、可复现的技术框架,而更多的是一种理念和方向性的指导。其核心在于构建一个以人为本的LLM应用模式,包括以下几个关键阶段:1) 语言学家的知识注入:将语言的语法、词汇、文化背景等信息融入LLM;2) 数据增强:利用LLM生成更多样化的训练数据,弥补濒危语言数据稀缺的问题;3) 人工校对与反馈:由语言专家对LLM生成的内容进行校对和反馈,确保其准确性和文化敏感性;4) 持续学习与优化:根据反馈不断优化LLM,提高其对濒危语言的理解和生成能力。
关键创新:论文的创新之处在于强调了人类专家在LLM应用于濒危语言保护中的关键作用,并提出了一个以人为中心的协作框架。与以往单纯依赖机器翻译和自动生成的方法不同,该方法更加注重语言的文化背景和社会价值,力求在技术进步的同时,保护语言的多样性。
关键设计:由于该论文是基于主题演讲,因此没有提供具体的参数设置、损失函数或网络结构等技术细节。未来的研究可以探索如何将语言学家的知识有效地编码到LLM中,例如通过知识图谱、规则引擎等方式。此外,还可以研究如何设计更有效的损失函数,以鼓励LLM生成更符合濒危语言文化背景的内容。
🖼️ 关键图片
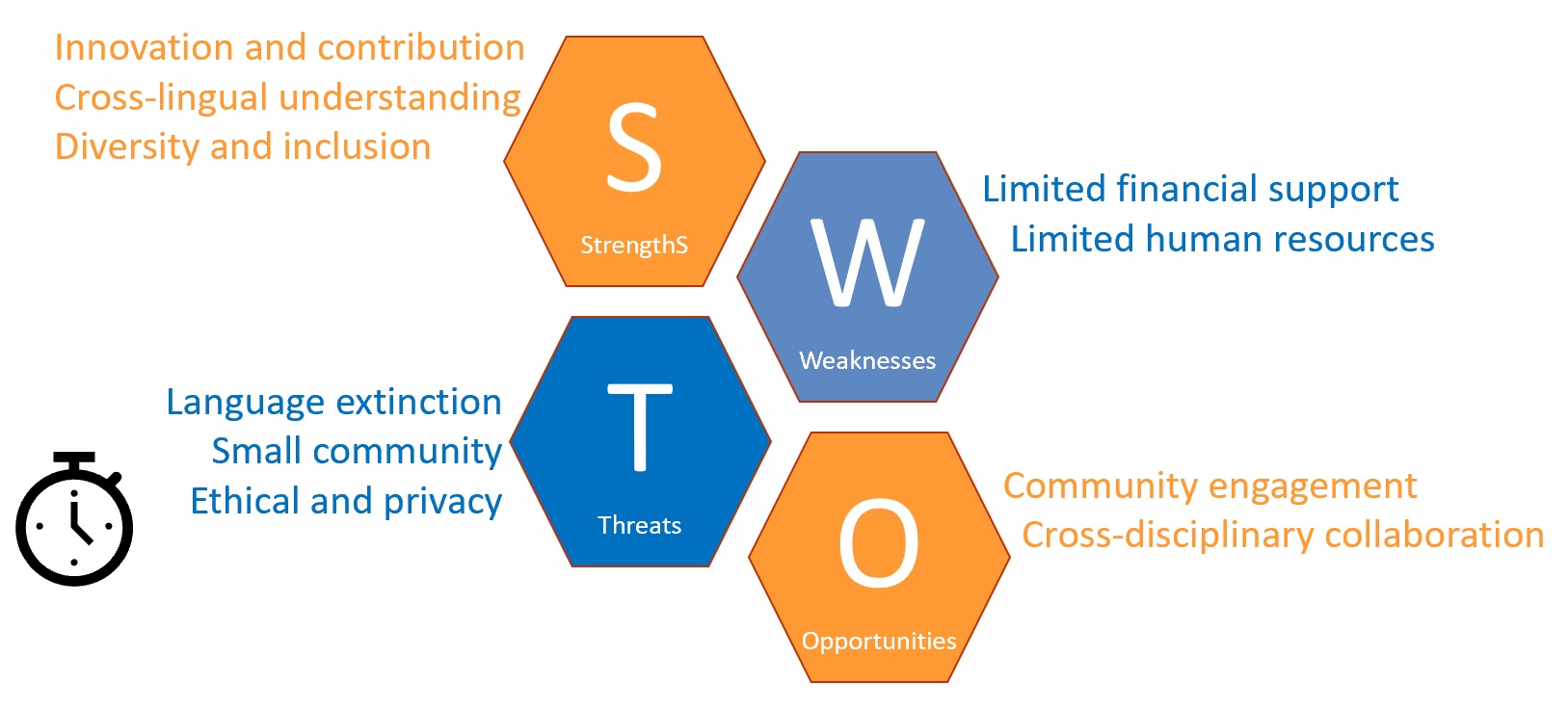

📊 实验亮点
该论文是主题演讲,主要在于提出观点和方向,没有具体的实验数据。其亮点在于强调了LLM在保护濒危语言方面的潜力,同时也指出了其可能带来的风险,并呼吁在技术应用中注重伦理和社会责任。以奥克语为例,为其他濒危语言的保护提供了参考。
🎯 应用场景
该研究成果可应用于濒危语言的数字化保护、教育资源的开发、文化传承以及促进语言多样性。通过结合LLM技术和语言学家的专业知识,可以为濒危语言创造更多的数字内容,提高其在数字世界的可见性,并促进其在社区中的使用和传承。此外,该研究也为其他文化遗产的保护提供了借鉴。
📄 摘要(原文)
Isidore of Seville is credited with the adage that it is language that gives birth to a people, and not the other way around , underlining the profound role played by language in the formation of cultural and social identity. Today, of the more than 7100 languages listed, a significant number are endangered. Since the 1970s, linguists, information seekers and enthusiasts have helped develop digital resources and automatic tools to support a wide range of languages, including endangered ones. The advent of Large Language Model (LLM) technologies holds both promise and peril. They offer unprecedented possibilities for the translation and generation of content and resources, key elements in the preservation and revitalisation of languages. They also present threat of homogenisation, cultural oversimplification and the further marginalisation of already vulnerable languages. The talk this paper is based on has proposed an initiatory journey, exploring the potential paths and partnerships between technology and tradition, with a particular focus on the Occitan language. Occitan is a language from Southern France, parts of Spain and Italy that played a major cultural and economic role, particularly in the Middle Ages. It is now endangered according to UNESCO. The talk critically has examined how human expertise and artificial intelligence can work together to offer hope for preserving the linguistic diversity that forms the foundation of our global and especially our European heritage while addressing some of the ethical and practical challenges that accompany the use of these powerful technologies. This paper is based on the keynote I gave at the 46th European Conference on Information Retrieval (ECIR 2024). As an alternative to reading this paper, a video talk is available online. 1 Date: 26 March 2024.