Attention Heads of Large Language Models: A Survey
作者: Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, Zhiyu Li
分类: cs.CL
发布日期: 2024-09-05 (更新: 2024-12-23)
备注: 33 pages, 11 figures, 7 tables, 7 equations
💡 一句话要点
综述大型语言模型注意力头的角色与机制,揭示LLM内部推理过程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 注意力机制 可解释性 推理过程 知识回忆 上下文识别 潜在推理 表达准备
📋 核心要点
- 大型语言模型虽然能力强大,但其内部运作机制如同黑盒,理解其推理瓶颈至关重要。
- 该论文提出一个四阶段框架(知识回忆、上下文识别、潜在推理、表达准备)来分析注意力头的功能。
- 论文系统性地回顾了现有研究,并对注意力头的实验方法和评估基准进行了分类总结。
📝 摘要(中文)
自从ChatGPT问世以来,大型语言模型(LLMs)在各种任务中表现出色,但仍然是黑盒系统。理解LLMs的推理瓶颈已成为一个关键挑战,因为这些限制与它们的内部架构密切相关。其中,注意力头已成为研究LLMs底层机制的焦点。在本综述中,我们旨在通过系统地探索注意力头的角色和机制来揭示LLMs的内部推理过程。我们首先提出了一个受人类思维过程启发的四阶段框架:知识回忆、上下文识别、潜在推理和表达准备。使用此框架,我们全面回顾了现有研究,以识别和分类特定注意力头的功能。此外,我们分析了用于发现这些特殊头的实验方法,将其分为两类:无建模方法和需要建模方法。我们进一步总结了相关的评估方法和基准。最后,我们讨论了当前研究的局限性,并提出了几个潜在的未来方向。
🔬 方法详解
问题定义:大型语言模型(LLMs)虽然在各种任务中表现出色,但其内部运作机制仍然像一个黑盒。理解LLMs的推理瓶颈,特别是注意力头在其中的作用,是一个重要的研究问题。现有方法缺乏一个系统性的框架来分析和理解不同注意力头的功能,以及它们在LLM推理过程中的具体作用。
核心思路:该论文的核心思路是借鉴人类的思维过程,提出了一个四阶段的框架,包括知识回忆、上下文识别、潜在推理和表达准备。通过这个框架,可以将LLM的推理过程分解为更小的、更易于理解的步骤,从而更好地分析注意力头在每个阶段的作用。
技术框架:该论文提出了一个四阶段框架,用于分析LLM中注意力头的功能: 1. 知识回忆:注意力头负责从模型记忆中检索相关知识。 2. 上下文识别:注意力头识别输入文本中的关键信息和上下文关系。 3. 潜在推理:注意力头执行逻辑推理、关系推断等复杂操作。 4. 表达准备:注意力头准备最终的输出表达。
此外,论文还将现有的实验方法分为两类: 1. 无建模方法:直接分析注意力头的权重和激活,无需额外的模型训练。 2. 需要建模方法:需要训练额外的模型来预测注意力头的行为或功能。
关键创新:该论文的关键创新在于提出了一个受人类思维过程启发的四阶段框架,用于系统地分析和理解LLM中注意力头的功能。这个框架提供了一个新的视角,可以帮助研究人员更好地理解LLM的内部运作机制。
关键设计:论文没有提出新的模型或算法,而是一个分析框架。关键在于如何将现有的研究工作映射到这个框架中,并总结出不同类型的注意力头在不同阶段的作用。此外,论文还对现有的实验方法进行了分类,并总结了相关的评估方法和基准。
🖼️ 关键图片
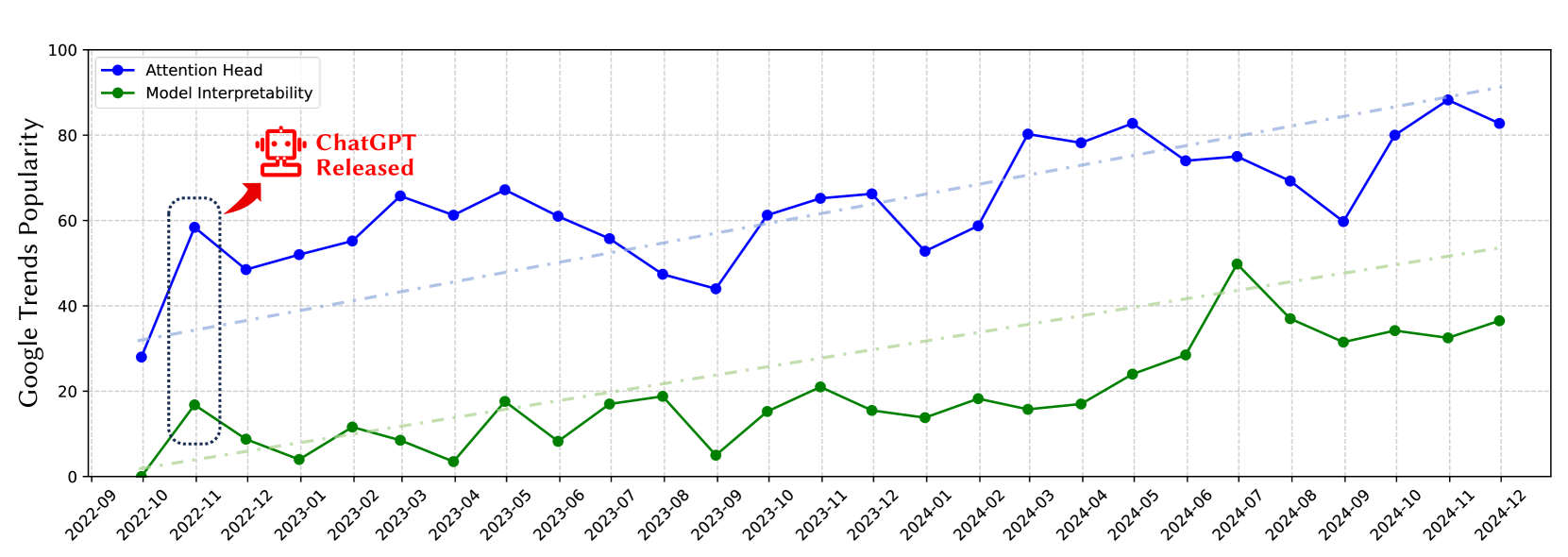

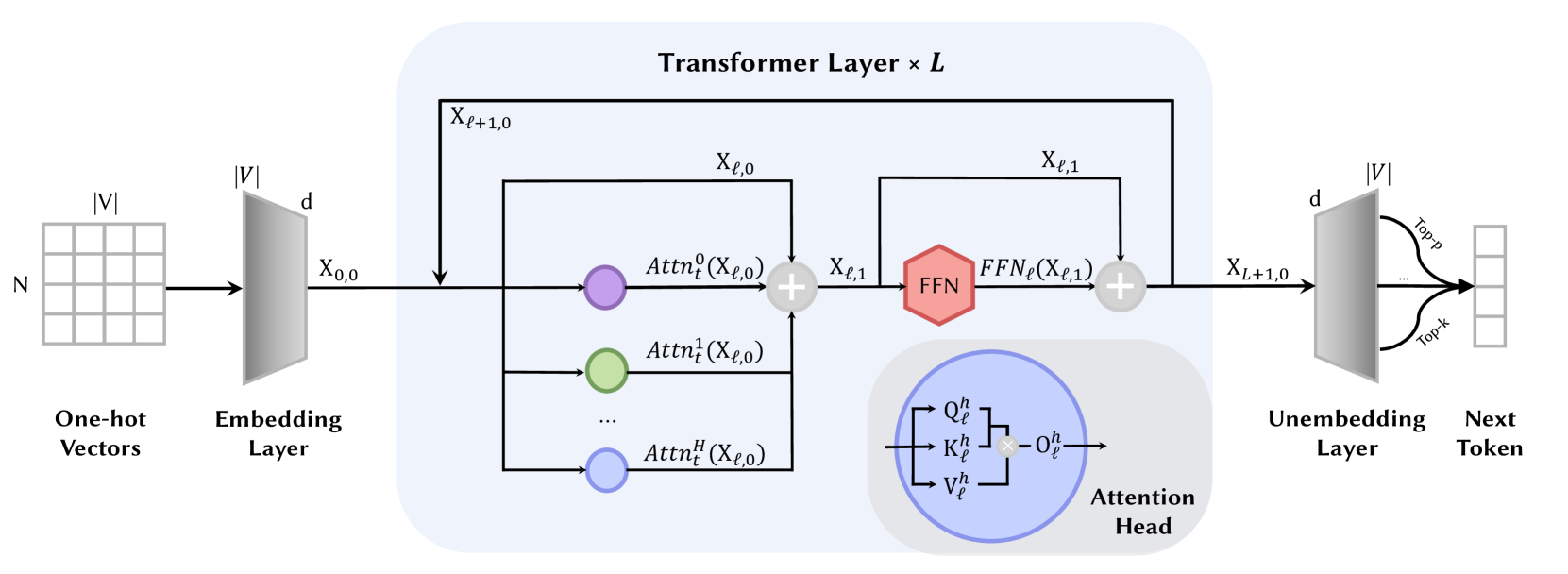
📊 实验亮点
该综述论文系统性地整理了关于大型语言模型注意力头的研究,提出了一个新颖的四阶段分析框架,并对现有的实验方法和评估基准进行了分类总结。该论文为研究人员提供了一个全面的视角,可以帮助他们更好地理解LLM的内部运作机制,并指导未来的研究方向。
🎯 应用场景
该研究成果可以应用于提升大型语言模型的可解释性,并指导模型的设计和优化。通过理解不同注意力头的功能,可以更好地控制模型的行为,并提高模型在特定任务上的性能。此外,该研究还可以帮助开发更安全、更可靠的LLM,减少模型产生有害或不准确信息的风险。
📄 摘要(原文)
Since the advent of ChatGPT, Large Language Models (LLMs) have excelled in various tasks but remain as black-box systems. Understanding the reasoning bottlenecks of LLMs has become a critical challenge, as these limitations are deeply tied to their internal architecture. Among these, attention heads have emerged as a focal point for investigating the underlying mechanics of LLMs. In this survey, we aim to demystify the internal reasoning processes of LLMs by systematically exploring the roles and mechanisms of attention heads. We first introduce a novel four-stage framework inspired by the human thought process: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. Using this framework, we comprehensively review existing research to identify and categorize the functions of specific attention heads. Additionally, we analyze the experimental methodologies used to discover these special heads, dividing them into two categories: Modeling-Free and Modeling-Required methods. We further summarize relevant evaluation methods and benchmarks. Finally, we discuss the limitations of current research and propose several potential future directions.