GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
作者: Yukun Cao, Shuo Han, Zengyi Gao, Zezhong Ding, Xike Xie, S. Kevin Zhou
分类: cs.CL
发布日期: 2024-09-05 (更新: 2024-12-16)
💡 一句话要点
GraphInsight:提升大语言模型对图结构理解能力,解决图规模增大时的位置偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图结构理解 大语言模型 位置偏见 检索增强生成 知识图谱
📋 核心要点
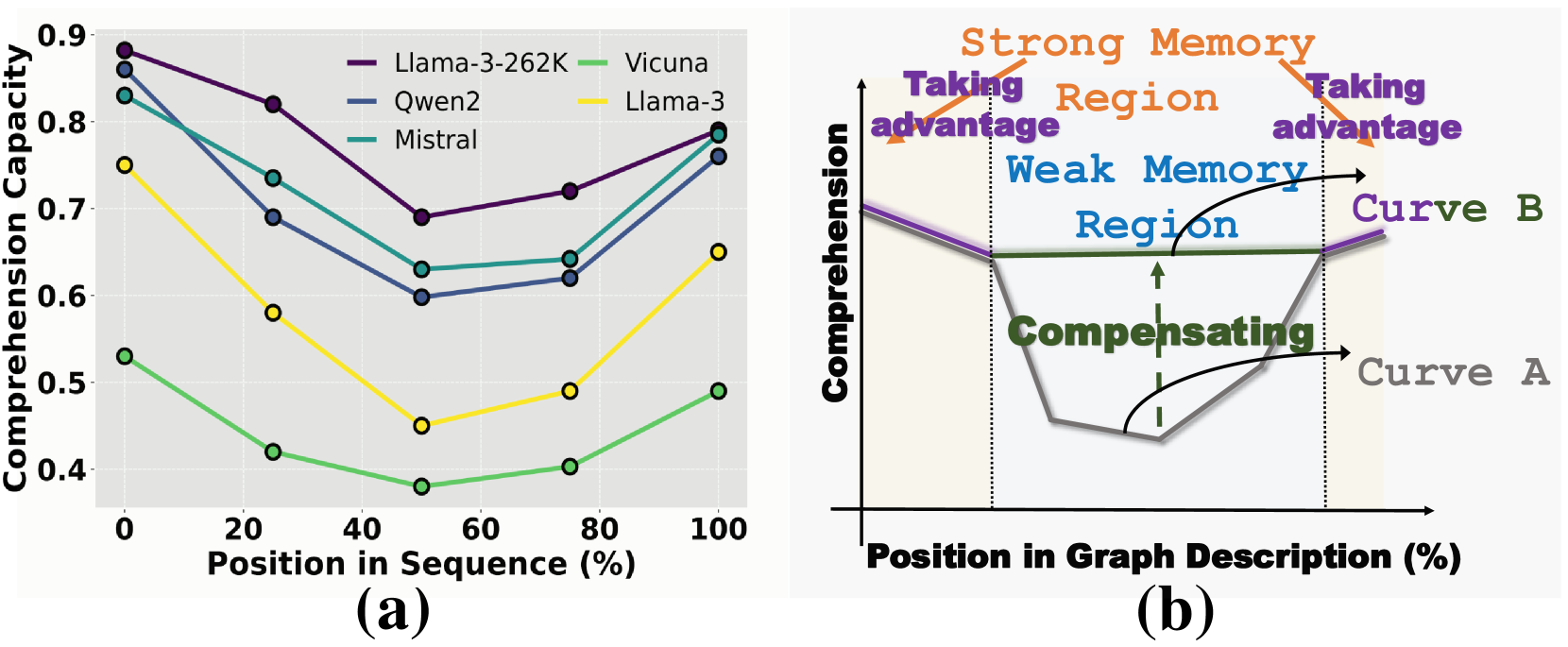
- 大语言模型在处理图结构时,受限于图描述序列的位置偏见,导致图规模增大时理解能力下降。
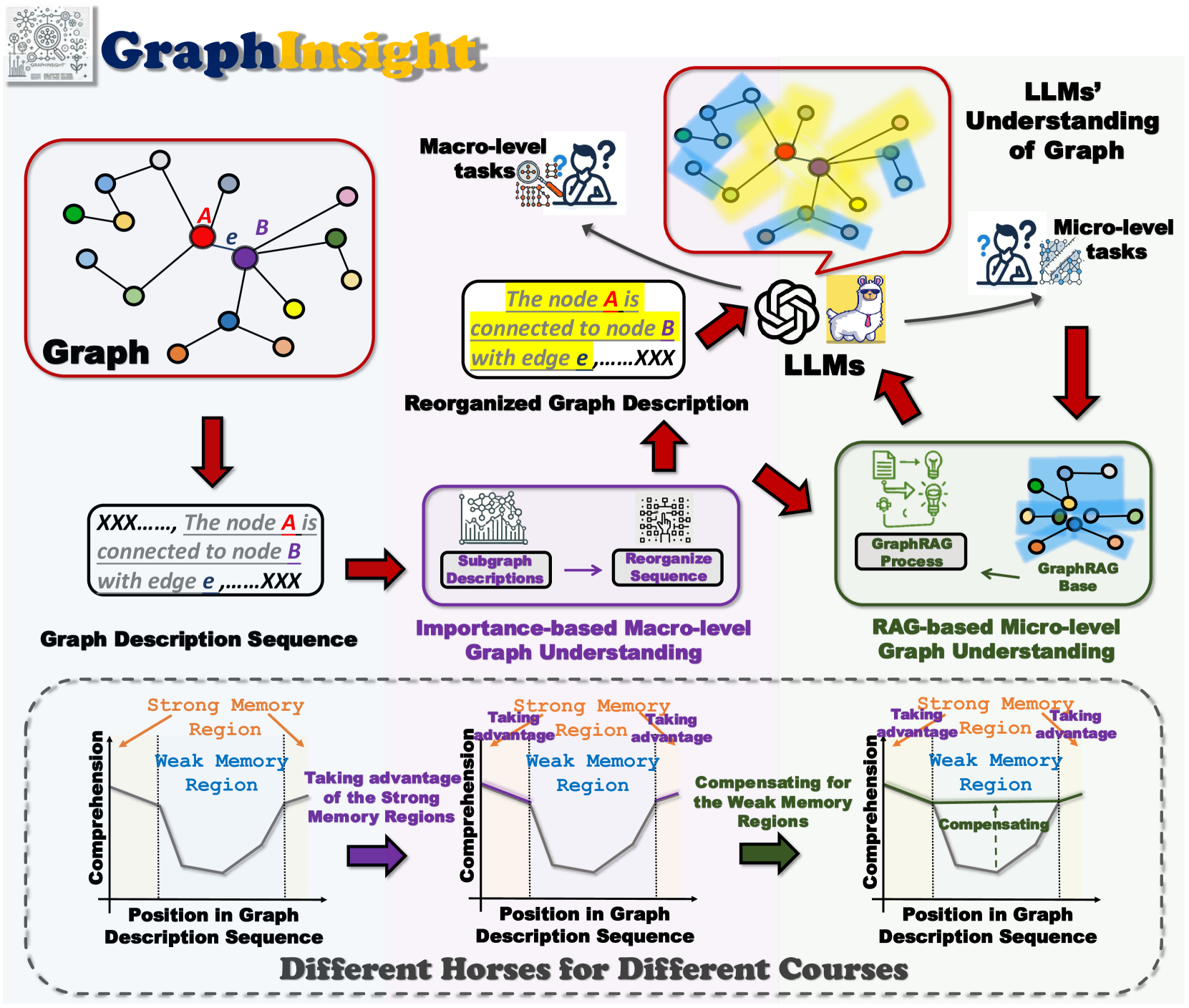
- GraphInsight通过将关键信息置于LLM记忆优势位置,并结合外部知识库,提升图信息理解。
- 实验表明,GraphInsight在理解不同大小的图结构方面,显著优于其他图描述方法。
📝 摘要(中文)
大语言模型(LLMs)在处理图结构方面展现出潜力,但它们在通过图描述序列提示来理解图结构信息时面临挑战,尤其是在图规模增大时。我们认为,这是由于LLMs在图描述序列中不同位置的记忆性能不均,即“位置偏见”。为了解决这个问题,我们提出了GraphInsight,这是一个旨在提高LLMs对宏观和微观图信息理解的新框架。GraphInsight基于两个关键策略:1)将关键图信息放置在LLMs表现出更强记忆性能的位置;2)借鉴检索增强生成(RAG),为记忆性能较弱的区域探索轻量级外部知识库。此外,GraphInsight还探索将这两种策略集成到LLM Agent流程中,以用于需要多步骤推理的复合图任务。在各种评估任务的基准测试中进行的大量实证研究表明,在理解不同大小的图结构方面,GraphInsight显著优于所有其他图描述方法(例如,提示技术和重排序策略)。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在处理大规模图数据时,由于“位置偏见”而导致的图结构理解能力下降的问题。现有方法,如直接使用图描述序列作为提示,在大图场景下效果不佳,因为LLM对序列不同位置的信息记忆能力存在差异,导致关键信息丢失或被忽略。
核心思路:GraphInsight的核心思路是缓解LLM的“位置偏见”,通过两种策略来提升其图结构理解能力。一是将关键的图信息放置在LLM记忆性能较好的位置,二是对于记忆性能较弱的位置,引入轻量级的外部知识库,类似于检索增强生成(RAG)的思想。
技术框架:GraphInsight框架主要包含两个阶段:信息放置和知识增强。信息放置阶段旨在确定哪些图信息是关键的,并将它们放置在LLM记忆性能较好的位置(具体位置的选择可能需要实验确定)。知识增强阶段则针对LLM记忆性能较弱的位置,构建并查询轻量级的外部知识库,以补充缺失的信息。此外,对于需要多步骤推理的复合图任务,GraphInsight将这两个阶段集成到LLM Agent流程中。
关键创新:GraphInsight的关键创新在于其针对LLM“位置偏见”的解决方案。它没有试图改变LLM本身的记忆特性,而是通过巧妙地组织和补充输入信息,来提升LLM对图结构的理解能力。这种方法具有通用性,可以应用于不同的LLM和图任务。与现有方法相比,GraphInsight更关注于如何有效地利用LLM的现有能力,而不是试图从根本上改变LLM的结构或训练方式。
关键设计:论文中可能涉及的关键设计包括:1) 如何确定哪些图信息是“关键的”,例如节点度、中心性等;2) 如何选择LLM记忆性能较好的位置,可能需要通过实验分析LLM在不同位置的记忆能力;3) 如何构建轻量级的外部知识库,例如使用图嵌入技术将图结构信息编码到向量空间中,并使用近似最近邻搜索来快速检索相关信息;4) 如何将信息放置和知识增强策略集成到LLM Agent流程中,可能需要设计合适的提示模板和推理策略。
🖼️ 关键图片
📊 实验亮点
论文通过在多个图结构理解基准测试上进行实验,证明了GraphInsight的有效性。实验结果表明,GraphInsight显著优于其他图描述方法,包括各种提示技术和重排序策略。具体的性能提升幅度未知,但摘要中强调了“显著优于”,表明GraphInsight在图结构理解方面取得了实质性的进展。
🎯 应用场景
GraphInsight具有广泛的应用前景,例如在社交网络分析、知识图谱推理、生物信息学等领域。它可以帮助LLM更好地理解复杂图结构,从而实现更准确的节点分类、链接预测、图生成等任务。此外,GraphInsight还可以应用于智能推荐、欺诈检测等实际场景,提升系统的性能和可靠性。未来,该研究可以进一步扩展到其他类型的结构化数据,例如树、序列等。
📄 摘要(原文)
Although Large Language Models (LLMs) have demonstrated potential in processing graphs, they struggle with comprehending graphical structure information through prompts of graph description sequences, especially as the graph size increases. We attribute this challenge to the uneven memory performance of LLMs across different positions in graph description sequences, known as ''positional biases''. To address this, we propose GraphInsight, a novel framework aimed at improving LLMs' comprehension of both macro- and micro-level graphical information. GraphInsight is grounded in two key strategies: 1) placing critical graphical information in positions where LLMs exhibit stronger memory performance, and 2) investigating a lightweight external knowledge base for regions with weaker memory performance, inspired by retrieval-augmented generation (RAG). Moreover, GraphInsight explores integrating these two strategies into LLM agent processes for composite graph tasks that require multi-step reasoning. Extensive empirical studies on benchmarks with a wide range of evaluation tasks show that GraphInsight significantly outperforms all other graph description methods (e.g., prompting techniques and reordering strategies) in understanding graph structures of varying sizes.