Understanding LLM Development Through Longitudinal Study: Insights from the Open Ko-LLM Leaderboard
作者: Chanjun Park, Hyeonwoo Kim
分类: cs.CL, cs.AI
发布日期: 2024-09-05 (更新: 2025-03-04)
备注: Accepted to NAACL 2025 Industry
💡 一句话要点
通过长期研究理解LLM发展:来自Open Ko-LLM排行榜的洞见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 纵向研究 韩国LLM Open Ko-LLM排行榜 模型评估
📋 核心要点
- 现有研究对Open Ko-LLM排行榜的分析周期短,仅为5个月,难以全面反映LLM的长期发展趋势。
- 本研究通过长达11个月的纵向分析,深入挖掘韩国LLM在不同任务上的性能提升挑战与模型规模的影响。
- 通过分析1769个模型,揭示了Open Ko-LLM排行榜上排名模式随时间的变化,以及评估框架的演变。
📝 摘要(中文)
本文针对Open Ko-LLM排行榜进行了为期11个月的纵向研究,旨在弥补先前研究的局限性,因为之前的研究仅依赖于5个月的有限观察期内的经验研究。通过延长分析时间,我们力求更全面地理解韩国大型语言模型(LLM)的发展进程。我们的研究由三个主要研究问题驱动:(1)随着时间的推移,在Open Ko-LLM排行榜上改进LLM在不同任务上的性能,具体挑战是什么?(2)模型大小如何影响各种基准测试中任务性能的相关性?(3)随着时间的推移,Open Ko-LLM排行榜上的排名模式发生了怎样的变化?通过分析这段时间内1769个模型,我们的研究对LLM的持续进步和评估框架的演变性质进行了全面的考察。
🔬 方法详解
问题定义:现有研究对Open Ko-LLM排行榜的分析周期较短,通常仅为5个月,这限制了对韩国LLM发展趋势的全面理解。此外,缺乏对模型规模与任务性能之间关系的深入分析,以及对排行榜排名变化模式的长期跟踪。
核心思路:本研究的核心思路是通过延长观察周期,进行纵向分析,从而更全面地了解韩国LLM的发展。通过分析大量模型在不同任务上的表现,揭示性能提升的挑战、模型规模的影响以及排行榜排名的变化模式。
技术框架:本研究的技术框架主要包括以下几个阶段:数据收集与整理,从Open Ko-LLM排行榜收集1769个模型的性能数据;数据分析,对收集到的数据进行统计分析,包括性能随时间的变化、模型规模与性能的相关性、排名变化模式等;结果可视化与解释,将分析结果以图表等形式展示,并进行深入的解释和讨论。
关键创新:本研究的关键创新在于其纵向研究的设计,通过长达11个月的观察周期,弥补了先前研究的不足,提供了更全面的视角。此外,研究还深入探讨了模型规模与任务性能之间的关系,以及排行榜排名变化模式,为理解LLM的发展提供了新的洞见。
关键设计:研究中关键的设计包括选择Open Ko-LLM排行榜作为研究对象,该排行榜提供了丰富的模型性能数据;采用统计分析方法,对数据进行深入挖掘;以及通过可视化手段,清晰地展示研究结果。
🖼️ 关键图片
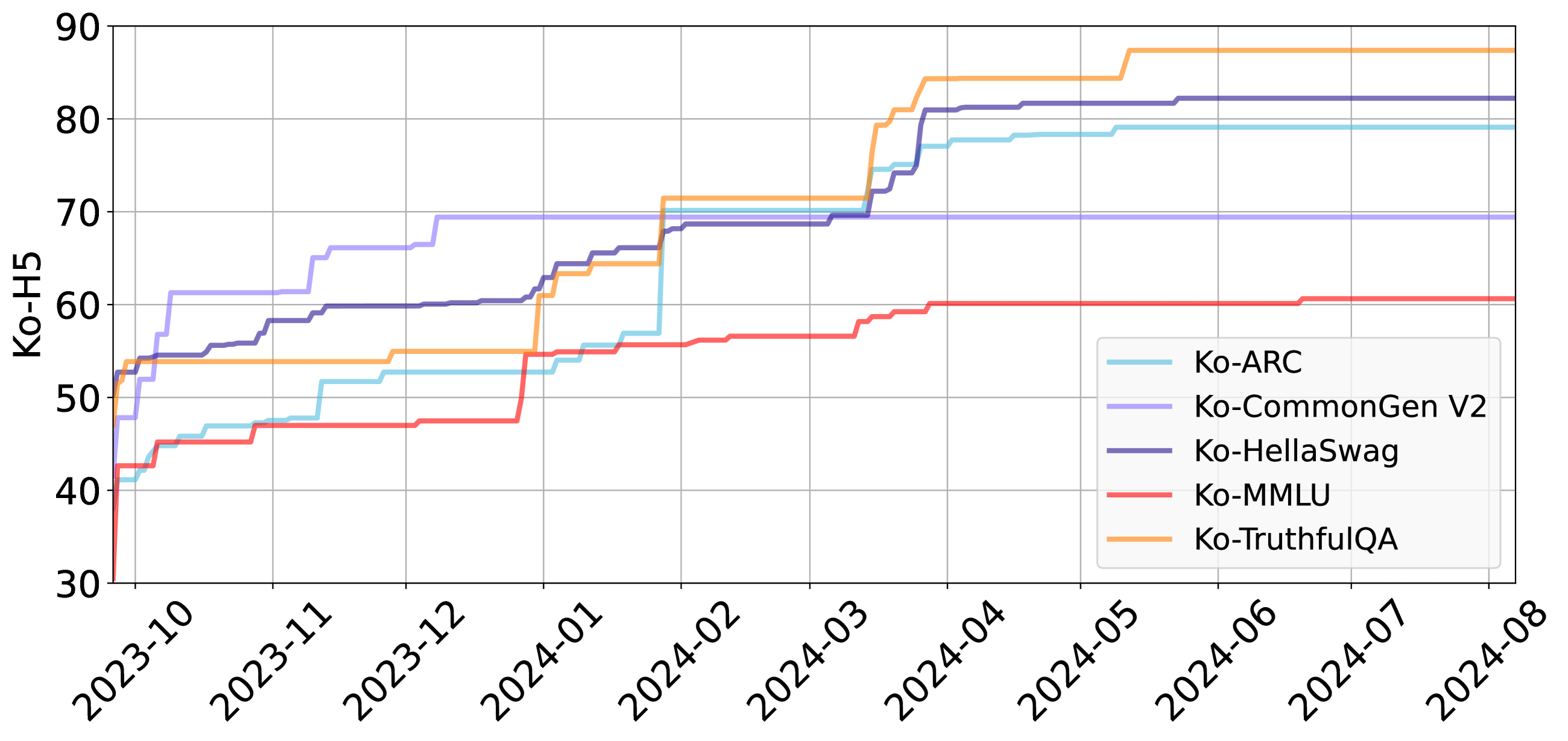
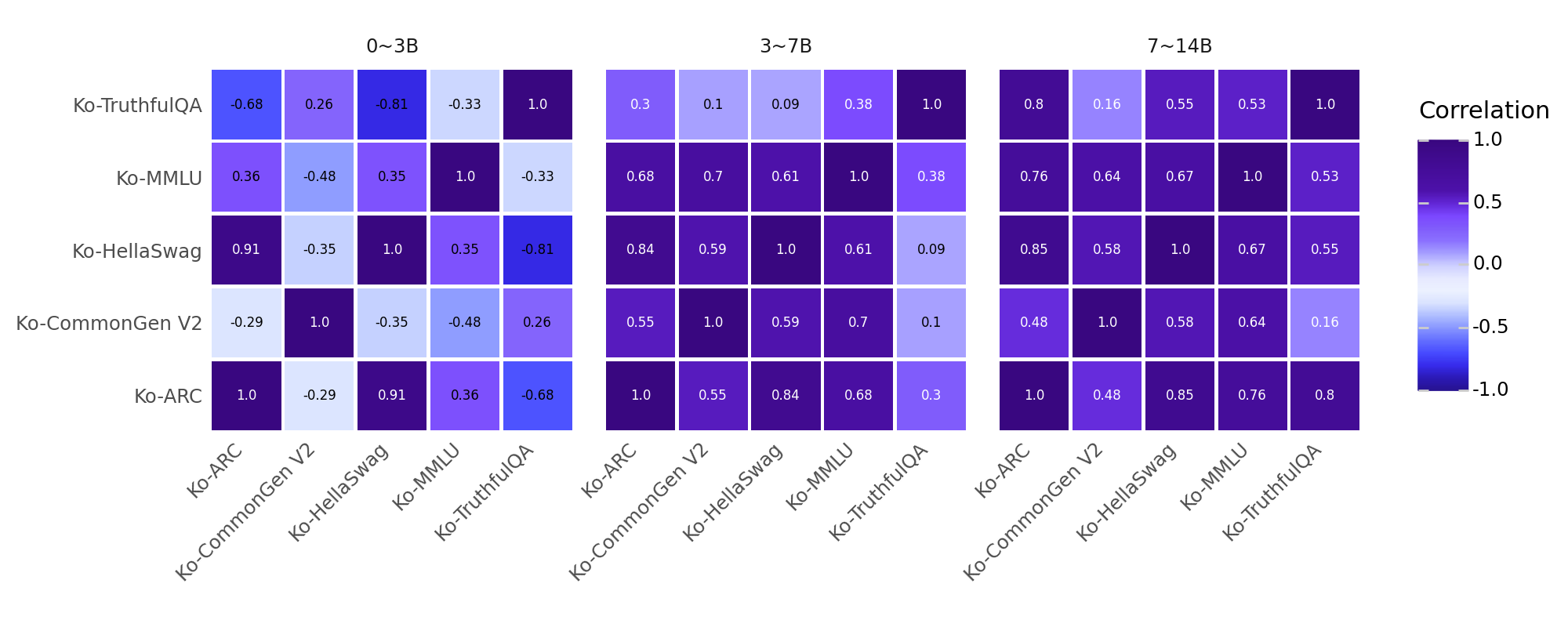
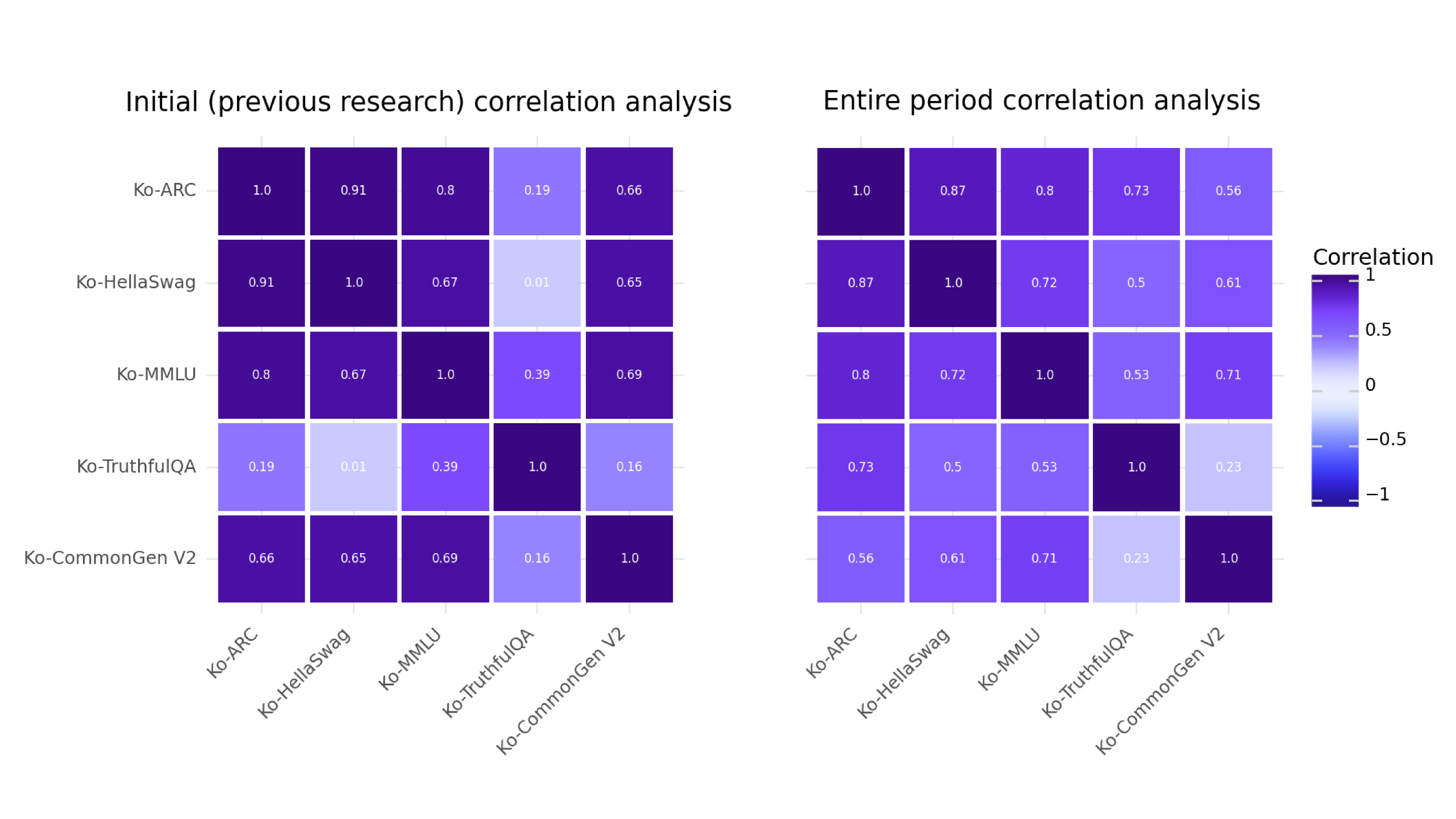
📊 实验亮点
研究分析了1769个模型在Open Ko-LLM排行榜上11个月的表现,揭示了LLM在不同任务上的性能提升挑战。研究发现模型规模与任务性能之间存在一定的相关性,但并非线性关系。此外,研究还观察到排行榜排名模式随时间的变化,反映了LLM技术的快速发展。
🎯 应用场景
该研究成果可应用于指导韩国LLM的研发方向,帮助开发者了解当前模型的优势与不足,并针对性地进行改进。此外,研究结果还可以为评估框架的设计提供参考,促进LLM评估的标准化和客观化。该研究对于推动韩国乃至全球LLM技术的发展具有重要意义。
📄 摘要(原文)
This paper conducts a longitudinal study over eleven months to address the limitations of prior research on the Open Ko-LLM Leaderboard, which have relied on empirical studies with restricted observation periods of only five months. By extending the analysis duration, we aim to provide a more comprehensive understanding of the progression in developing Korean large language models (LLMs). Our study is guided by three primary research questions: (1) What are the specific challenges in improving LLM performance across diverse tasks on the Open Ko-LLM Leaderboard over time? (2) How does model size impact task performance correlations across various benchmarks? (3) How have the patterns in leaderboard rankings shifted over time on the Open Ko-LLM Leaderboard?. By analyzing 1,769 models over this period, our research offers a comprehensive examination of the ongoing advancements in LLMs and the evolving nature of evaluation frameworks.