LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via a Hybrid Architecture
作者: Xidong Wang, Dingjie Song, Shunian Chen, Junyin Chen, Zhenyang Cai, Chen Zhang, Lichao Sun, Benyou Wang
分类: cs.CL, cs.AI, cs.CV, cs.MM
发布日期: 2024-09-04 (更新: 2025-09-22)
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
LongLLaVA:通过混合架构高效扩展多模态LLM至处理千张图像
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 长上下文学习 混合架构 Mamba Transformer 视频理解 高分辨率图像分析
📋 核心要点
- 现有MLLM在处理大量图像时面临性能下降和计算成本过高的挑战,限制了其在视频理解和高分辨率图像分析中的应用。
- LongLLaVA采用混合架构,结合Mamba和Transformer的优势,并设计数据构建方法以捕捉时空依赖关系,实现高效的长上下文处理。
- LongLLaVA在多个基准测试中表现出色,能够在单GPU上处理近千张图像,证明了其在效率和性能上的平衡。
📝 摘要(中文)
扩展多模态大型语言模型(MLLM)的长上下文能力对于推进视频理解和高分辨率图像分析至关重要。这需要在模型架构、数据构建和训练策略方面进行系统性改进,特别是要解决图像数量增加时性能下降和高计算成本等挑战。本文提出了一种混合架构,集成了Mamba和Transformer模块,引入了捕获时间和空间依赖关系的数据构建方法,并采用了渐进式训练策略。我们发布的模型LongLLaVA(长上下文大型语言和视觉助手)展示了效率和性能之间的有效平衡。LongLLaVA在各种基准测试中取得了有竞争力的结果,同时保持了高吞吐量和低内存消耗。值得注意的是,它可以在单个A100 80GB GPU上处理近千张图像,突显了其在各种多模态应用中的潜力。
🔬 方法详解
问题定义:现有MLLM在处理长序列多模态数据(例如大量图像)时,面临着两个主要问题:一是随着图像数量的增加,模型性能显著下降;二是计算成本非常高昂,难以在有限的资源下进行训练和推理。现有方法通常基于Transformer架构,其自注意力机制的计算复杂度随序列长度呈平方增长,因此难以扩展到长上下文。
核心思路:LongLLaVA的核心思路是采用一种混合架构,将Mamba和Transformer模块结合起来,以实现效率和性能的平衡。Mamba架构具有线性复杂度,可以高效地处理长序列,而Transformer架构则擅长捕捉全局依赖关系。通过将两者结合,LongLLaVA可以在保持高性能的同时,显著降低计算成本。
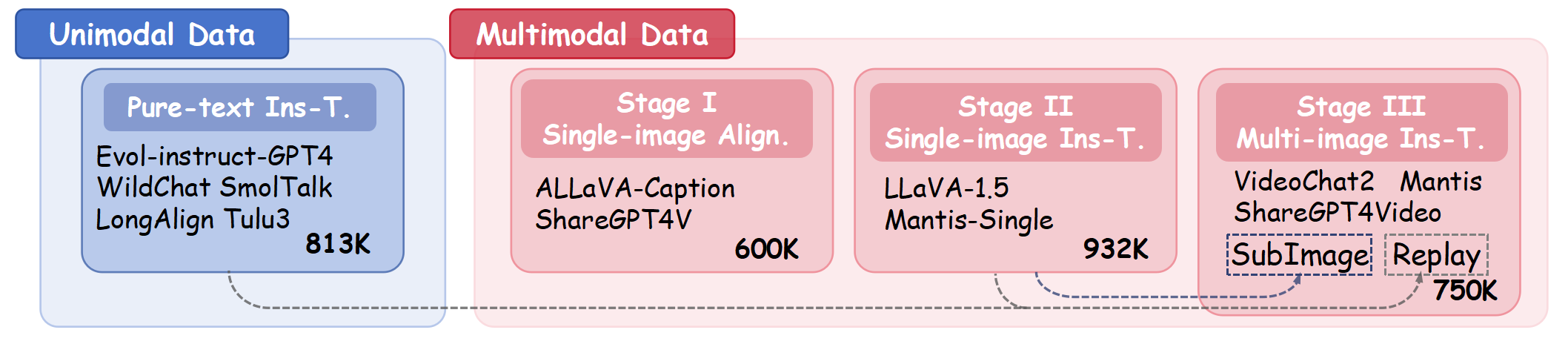
技术框架:LongLLaVA的整体架构包含以下几个主要模块:1) 图像编码器:用于将输入图像转换为视觉特征表示。2) 混合视觉编码器:由Mamba和Transformer块交替组成,用于处理视觉特征序列,捕捉时空依赖关系。3) 语言模型:用于生成文本输出,例如图像描述或问题回答。4) 渐进式训练策略:逐步增加训练数据的序列长度,以提高模型处理长上下文的能力。
关键创新:LongLLaVA的关键创新在于其混合架构,它有效地结合了Mamba和Transformer的优势。Mamba模块负责高效地处理长序列,而Transformer模块则负责捕捉全局依赖关系。此外,LongLLaVA还提出了数据构建方法,用于生成包含时间和空间依赖关系的训练数据,以及渐进式训练策略,用于提高模型处理长上下文的能力。
关键设计:LongLLaVA的关键设计包括:1) Mamba和Transformer块的比例和配置:需要根据具体任务进行调整,以实现最佳的性能和效率。2) 数据构建方法:需要确保训练数据包含足够的时间和空间依赖关系,以便模型能够学习到有效的长上下文表示。3) 渐进式训练策略:需要逐步增加训练数据的序列长度,以避免模型在训练初期就面临过大的挑战。具体的参数设置和损失函数等细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
LongLLaVA在多个基准测试中取得了有竞争力的结果,例如在视频问答和图像描述任务中,LongLLaVA的性能与现有最先进的模型相当。更重要的是,LongLLaVA能够在单个A100 80GB GPU上处理近千张图像,而现有模型通常只能处理几十张图像。这表明LongLLaVA在效率方面具有显著的优势。
🎯 应用场景
LongLLaVA具有广泛的应用前景,包括视频理解、高分辨率图像分析、医学影像诊断、遥感图像分析等领域。它可以用于处理包含大量图像或视频帧的数据,例如分析监控视频中的异常行为、诊断医学影像中的病灶、识别遥感图像中的地物等。LongLLaVA的低计算成本和高吞吐量使其能够部署在资源受限的设备上,例如移动设备或嵌入式系统。
📄 摘要(原文)
Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is critical for advancing video understanding and high-resolution image analysis. Achieving this requires systematic improvements in model architecture, data construction, and training strategies, particularly to address challenges such as performance degradation with increasing image counts and high computational costs. In this paper, we propose a hybrid architecture that integrates Mamba and Transformer blocks, introduce data construction methods that capture both temporal and spatial dependencies, and employ a progressive training strategy. Our released model, LongLLaVA (\textbf{Long}-Context \textbf{L}arge \textbf{L}anguage \textbf{a}nd \textbf{V}ision \textbf{A}ssistant), demonstrates an effective balance between efficiency and performance. LongLLaVA achieves competitive results across various benchmarks while maintaining high throughput and low memory consumption. Notably, it can process nearly one thousand images on a single A100 80GB GPU, underscoring its potential for a wide range of multi-modal applications.