CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
作者: Wentao Liu, Qianjun Pan, Yi Zhang, Zhuo Liu, Ji Wu, Jie Zhou, Aimin Zhou, Qin Chen, Bo Jiang, Liang He
分类: cs.CL
发布日期: 2024-09-04 (更新: 2024-11-01)
💡 一句话要点
发布中文多模态数学数据集CMM-Math,用于评估和提升大模型数学推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数学推理 大型语言模型 中文数据集 教育应用
📋 核心要点
- 现有文本数学推理数据集无法充分评估LMMs,而现有的英文多模态数据集对中文LMMs支持不足。
- 提出CMM-Math数据集,包含丰富的中文多模态数学题型,覆盖小学到高中,并提供详细解答。
- 提出Math-LMM模型,通过多阶段训练,有效提升了LMMs在多模态数学推理任务上的性能。
📝 摘要(中文)
本文发布了一个中文多模态数学数据集(CMM-Math),包含基准测试和训练两部分,旨在评估和提升大型多模态模型(LMMs)的数学推理能力。CMM-Math包含超过28,000个高质量样本,涵盖小学到高中的12个年级,包含多种问题类型(如选择题、填空题等),并提供详细的解答。该数据集的特点在于问题或选项中可能存在视觉上下文,这增加了数据集的挑战性。通过全面的分析,我们发现当前最先进的LMMs在CMM-Math数据集上面临挑战,这突出了进一步改进LMM开发的必要性。我们还提出了一个多模态数学LMM(Math-LMM)来处理混合了多个图像和文本片段的问题。我们使用三个阶段训练我们的模型,包括基础预训练、基础微调和数学微调。大量的实验表明,通过与三个多模态数学数据集上的SOTA LMM进行比较,我们的模型有效地提高了数学推理性能。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在中文多模态数学推理方面的不足。现有方法主要集中在文本数学推理,或者使用英文多模态数据集,无法有效评估和提升中文LMMs的数学能力。痛点在于缺乏高质量的中文多模态数学数据集,以及针对此类数据的有效模型。
核心思路:论文的核心思路是构建一个高质量的中文多模态数学数据集CMM-Math,并在此基础上训练一个专门的LMM模型Math-LMM。通过多阶段训练,使模型能够更好地理解和推理包含图像和文本信息的数学问题。这样设计的目的是为了弥补现有数据集和模型的不足,提升LMMs在中文多模态数学推理方面的性能。
技术框架:整体框架包括数据集构建和模型训练两个部分。数据集构建方面,收集并整理了小学到高中的中文数学题,并添加了视觉信息。模型训练方面,Math-LMM采用三阶段训练策略:1) 基础预训练,使用大规模通用数据进行预训练;2) 基础微调,使用通用多模态数据进行微调;3) 数学微调,使用CMM-Math数据集进行微调。
关键创新:论文的关键创新在于构建了CMM-Math数据集,这是一个大规模、高质量的中文多模态数学数据集,包含了多种题型和详细解答。此外,提出的Math-LMM模型针对多模态数学推理进行了优化,通过多阶段训练,有效提升了模型的性能。与现有方法相比,该方法更专注于中文多模态数学推理,并提供了相应的资源和模型。
关键设计:Math-LMM模型的具体结构未知,但根据描述,其训练过程包含三个阶段。关键设计可能包括:针对数学推理任务设计的损失函数,用于融合图像和文本信息的跨模态注意力机制,以及针对不同阶段训练数据的采样策略。具体的网络结构和参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
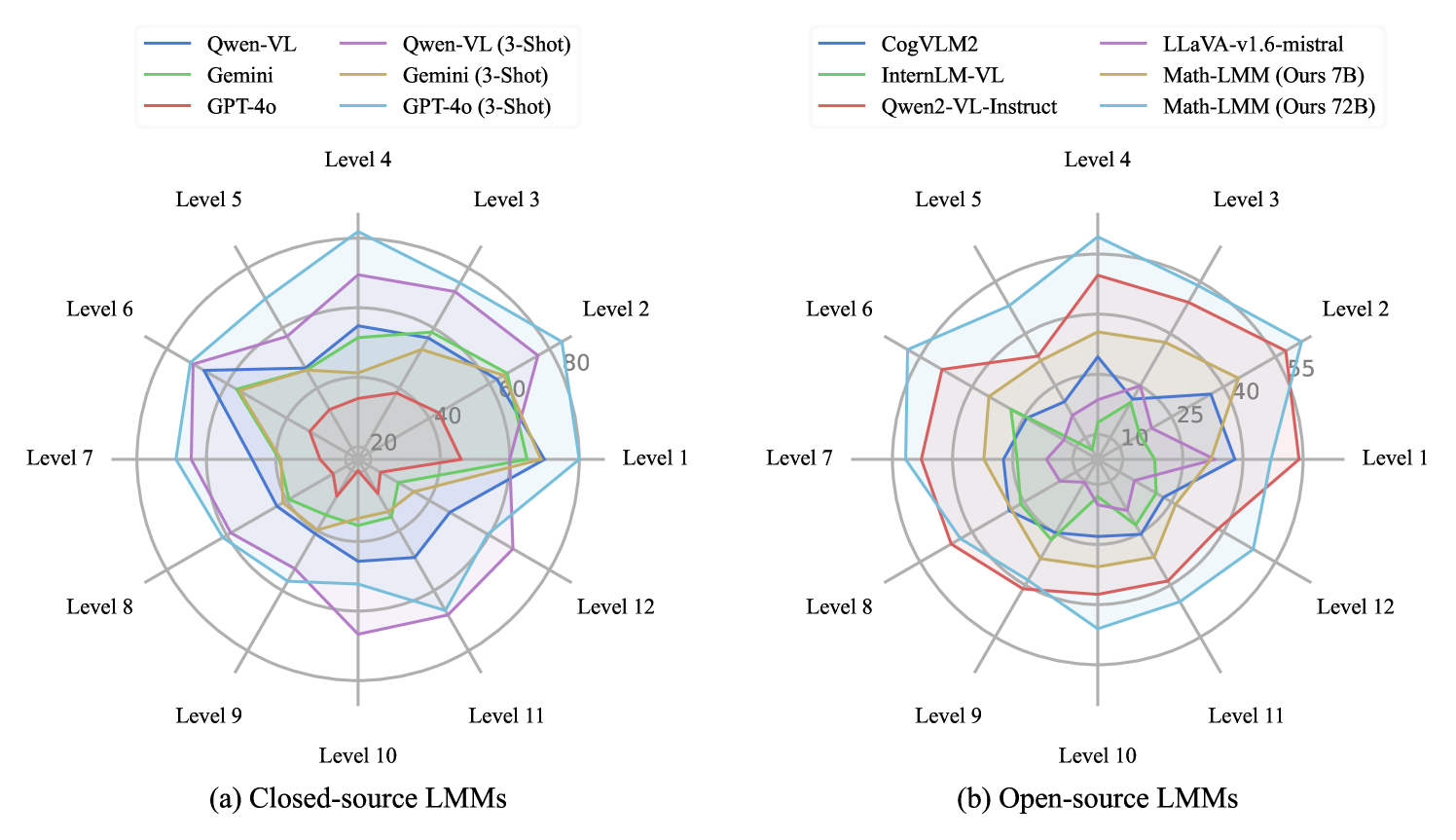


📊 实验亮点
实验结果表明,提出的Math-LMM模型在三个多模态数学数据集上,相较于SOTA LMMs,有效提升了数学推理性能。具体的性能数据和提升幅度在摘要中未给出,需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能教育领域,例如开发智能辅导系统,帮助学生解决数学难题。CMM-Math数据集可以作为评估和改进LMMs数学推理能力的基准。未来,该研究可以扩展到其他学科,构建更全面的多模态教育资源,促进人工智能在教育领域的应用。
📄 摘要(原文)
Large language models (LLMs) have obtained promising results in mathematical reasoning, which is a foundational skill for human intelligence. Most previous studies focus on improving and measuring the performance of LLMs based on textual math reasoning datasets (e.g., MATH, GSM8K). Recently, a few researchers have released English multimodal math datasets (e.g., MATHVISTA and MATH-V) to evaluate the effectiveness of large multimodal models (LMMs). In this paper, we release a Chinese multimodal math (CMM-Math) dataset, including benchmark and training parts, to evaluate and enhance the mathematical reasoning of LMMs. CMM-Math contains over 28,000 high-quality samples, featuring a variety of problem types (e.g., multiple-choice, fill-in-the-blank, and so on) with detailed solutions across 12 grade levels from elementary to high school in China. Specifically, the visual context may be present in the questions or opinions, which makes this dataset more challenging. Through comprehensive analysis, we discover that state-of-the-art LMMs on the CMM-Math dataset face challenges, emphasizing the necessity for further improvements in LMM development. We also propose a Multimodal Mathematical LMM (Math-LMM) to handle the problems with mixed input of multiple images and text segments. We train our model using three stages, including foundational pre-training, foundational fine-tuning, and mathematical fine-tuning. The extensive experiments indicate that our model effectively improves math reasoning performance by comparing it with the SOTA LMMs over three multimodal mathematical datasets.