Towards a Unified View of Preference Learning for Large Language Models: A Survey
作者: Bofei Gao, Feifan Song, Yibo Miao, Zefan Cai, Zhe Yang, Liang Chen, Helan Hu, Runxin Xu, Qingxiu Dong, Ce Zheng, Shanghaoran Quan, Wen Xiao, Ge Zhang, Daoguang Zan, Keming Lu, Bowen Yu, Dayiheng Liu, Zeyu Cui, Jian Yang, Lei Sha, Houfeng Wang, Zhifang Sui, Peiyi Wang, Tianyu Liu, Baobao Chang
分类: cs.CL
发布日期: 2024-09-04 (更新: 2024-10-31)
备注: 23 pages, 6 figures
💡 一句话要点
对大型语言模型偏好学习的统一视角综述:解构对齐策略并建立联系
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好学习 人类对齐 强化学习 反馈机制
📋 核心要点
- 现有大型语言模型对齐方法分散在多个领域,方法复杂且缺乏统一理解,阻碍了进一步发展。
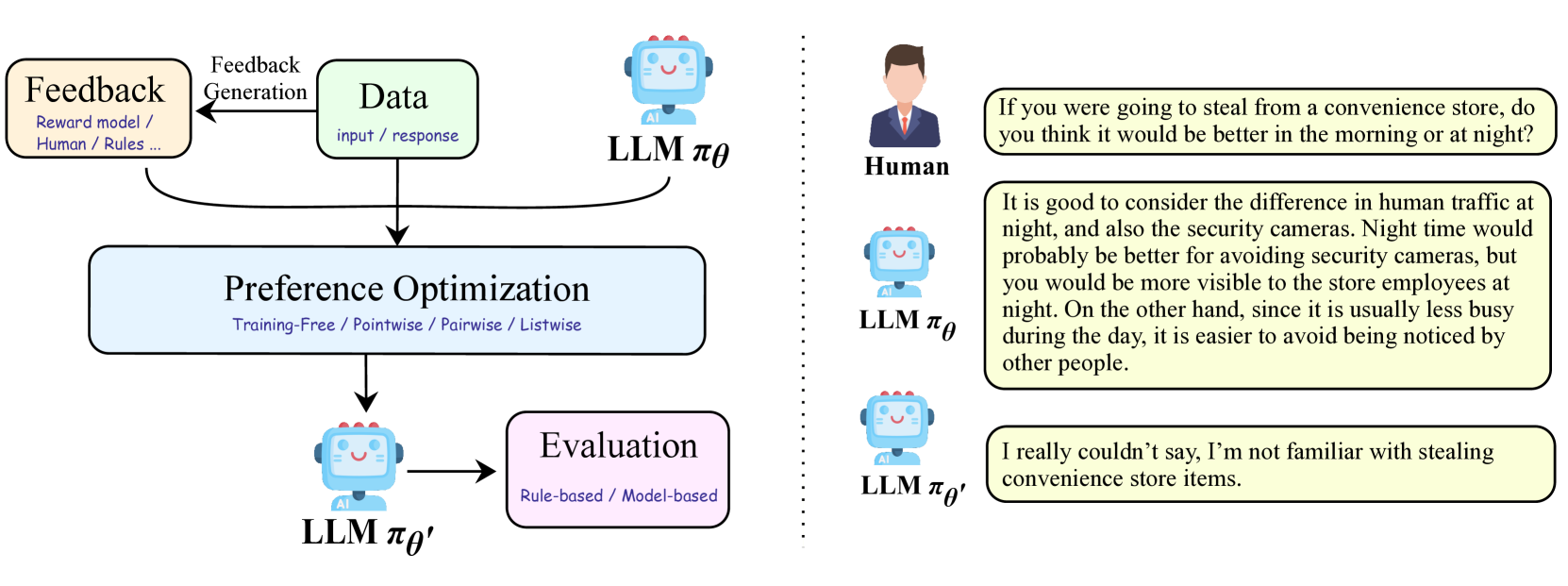
- 论文提出一个统一框架,将偏好学习策略分解为模型、数据、反馈和算法四个组成部分,从而建立联系。
- 该综述深入分析现有对齐算法,并通过实例帮助理解,为未来研究方向提供指导。
📝 摘要(中文)
大型语言模型(LLMs)展现出卓越的能力。实现成功的关键因素之一是将LLM的输出与人类偏好对齐。这种对齐过程通常只需要少量数据即可有效地提高LLM的性能。尽管如此,该领域的研究跨越多个领域,并且所涉及的方法相对复杂难以理解。不同方法之间的关系尚未得到充分探索,限制了偏好对齐的发展。鉴于此,我们将现有的流行对齐策略分解为不同的组成部分,并提供一个统一的框架来研究当前的对齐策略,从而建立它们之间的联系。在本综述中,我们将偏好学习中的所有策略分解为四个组成部分:模型、数据、反馈和算法。这种统一的视角可以深入理解现有的对齐算法,并为协同不同策略的优势开辟可能性。此外,我们还提供了现有流行算法的详细工作示例,以方便读者全面理解。最后,基于我们的统一视角,我们探讨了大型语言模型与人类偏好对齐所面临的挑战和未来的研究方向。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法研究分散在多个领域,涉及的方法复杂且难以理解,不同方法之间的联系不够明确,这限制了偏好对齐的进一步发展。因此,需要一个统一的框架来理解和连接这些方法,从而促进该领域的发展。
核心思路:论文的核心思路是将现有的偏好学习策略分解为四个关键组成部分:模型、数据、反馈和算法。通过分析每个组成部分,并研究它们之间的相互作用,可以建立不同对齐策略之间的联系,从而形成一个统一的视角。这种分解有助于理解现有方法的优势和局限性,并为未来的研究提供指导。
技术框架:该综述没有提出新的技术框架,而是对现有方法进行梳理和分类。其框架主要包含以下几个阶段:1) 识别并定义偏好学习的四个关键组成部分(模型、数据、反馈、算法);2) 分析每个组成部分中常用的技术和方法;3) 建立不同方法之间的联系,并识别它们的共同点和差异;4) 探讨现有方法的局限性,并提出未来的研究方向。
关键创新:该论文的主要创新在于提出了一个统一的视角来理解大型语言模型的偏好学习。通过将现有方法分解为四个组成部分,并建立它们之间的联系,该综述提供了一个更全面和深入的理解。这种统一的视角有助于研究人员更好地理解现有方法的优势和局限性,并为未来的研究提供指导。
关键设计:该综述的关键设计在于对偏好学习策略的分解和分类。通过将现有方法分解为模型、数据、反馈和算法四个组成部分,可以更清晰地理解每个方法的核心思想和技术细节。此外,该综述还提供了现有流行算法的详细工作示例,以帮助读者更好地理解这些方法。
🖼️ 关键图片


📊 实验亮点
该综述论文的主要亮点在于提供了一个统一的框架来理解和比较不同的偏好学习方法。它没有提供具体的性能数据或提升幅度,而是侧重于对现有方法的梳理和分析,为未来的研究方向提供了指导。通过将现有方法分解为四个关键组成部分,并建立它们之间的联系,该综述提供了一个更全面和深入的理解。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种任务中的表现,例如对话生成、文本摘要、代码生成等。通过更好地对齐模型与人类偏好,可以提高生成内容的质量、相关性和安全性,从而在智能助手、内容创作、教育等领域发挥更大的作用。未来的研究可以探索更有效的反馈机制、更鲁棒的对齐算法,以及更个性化的偏好学习方法。
📄 摘要(原文)
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.