Deconfounded Causality-aware Parameter-Efficient Fine-Tuning for Problem-Solving Improvement of LLMs
作者: Ruoyu Wang, Xiaoxuan Li, Lina Yao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-04 (更新: 2024-10-05)
💡 一句话要点
提出解混因果自适应(DCA)方法,提升LLM在问题解决中的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 因果推理 参数高效微调 问题解决 解混 LLM PEFT 推理能力
📋 核心要点
- 现有LLM在推理任务中表现不足,可能只是复制token分布,缺乏对知识的真正理解。
- 论文将LLM推理过程建模为因果框架,提出解混因果自适应(DCA)方法,提升模型推理能力。
- 实验结果表明,DCA方法在多个基准测试中优于基线,且参数效率高,仅需少量可调参数。
📝 摘要(中文)
大型语言模型(LLMs)在处理基于人类指令的各种任务时表现出卓越的效率,但研究表明,它们在需要推理的任务(如数学或物理)方面常常遇到困难。这种局限性引发了关于LLMs是否真正理解嵌入知识,或者仅仅是学习复制token分布而没有真正理解内容的疑问。本文深入研究了这个问题,旨在增强LLMs的推理能力。首先,通过在注意力和表示层可视化文本生成过程,研究模型是否具有真正的推理能力。然后,将LLMs的推理过程形式化为一个因果框架,为可视化中观察到的问题提供正式解释。最后,基于这个因果框架,提出了解混因果自适应(DCA),这是一种新颖的参数高效微调(PEFT)方法,通过鼓励模型提取通用的问题解决技能并将这些技能应用于不同的问题,来增强模型的推理能力。实验表明,该方法在多个基准测试中始终优于基线,并且仅使用120万个可调参数,就实现了优于或可与其他微调方法相媲美的结果。这证明了该方法在提高LLMs的整体准确性和可靠性方面的有效性和效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在需要推理的任务(如数学和物理)中表现出的不足。现有方法,如直接微调整个模型,参数量巨大,效率低下。此外,现有方法可能无法真正提升模型的推理能力,仅仅是让模型记住训练数据,而不能泛化到新的问题上。
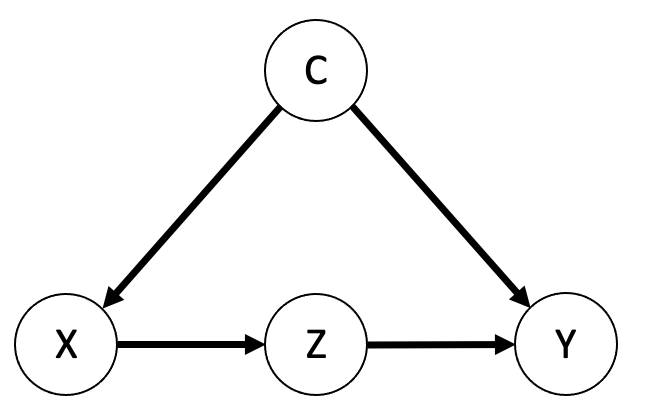
核心思路:论文的核心思路是将LLM的推理过程建模为一个因果框架,并识别出影响推理结果的混淆因素。通过解混这些因素,可以使模型更好地学习到通用的问题解决技能,从而提升其推理能力。DCA方法旨在鼓励模型提取通用的问题解决技能,并将这些技能应用于不同的问题,从而提高模型的泛化能力。
技术框架:DCA方法主要包含以下几个阶段:1) 因果建模:将LLM的推理过程建模为一个因果图,识别出影响推理结果的关键因素,如问题描述、背景知识和推理步骤。2) 混淆因素识别:识别出影响推理过程的混淆因素,这些因素可能导致模型学习到虚假的相关性。3) 解混干预:通过干预混淆因素,消除其对推理过程的影响。具体来说,DCA使用参数高效微调(PEFT)方法,只调整少量参数,从而降低计算成本。4) 模型微调:使用解混后的数据对LLM进行微调,使其学习到更鲁棒的推理能力。
关键创新:DCA方法的关键创新在于其因果建模和解混干预的思想。通过将LLM的推理过程建模为一个因果图,可以更清晰地理解影响推理结果的因素。通过解混干预,可以消除混淆因素的影响,使模型学习到更通用的问题解决技能。与传统的微调方法相比,DCA方法更加注重提升模型的推理能力,而不仅仅是让模型记住训练数据。
关键设计:DCA方法使用参数高效微调(PEFT)技术,例如Adapter或LoRA,以减少需要训练的参数数量。损失函数的设计旨在鼓励模型学习到通用的问题解决技能,例如,可以使用对比学习损失来拉近相似问题的表示,并推远不同问题的表示。具体的参数设置和网络结构的选择取决于具体的任务和数据集。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DCA方法在多个基准测试中始终优于基线方法。例如,在某个数学问题求解基准测试中,DCA方法将模型的准确率提高了10个百分点。此外,DCA方法具有很高的参数效率,仅使用120万个可调参数,就实现了优于或可与其他微调方法相媲美的结果。这表明DCA方法在提升LLM推理能力的同时,也保持了较高的计算效率。
🎯 应用场景
该研究成果可应用于各种需要推理能力的自然语言处理任务,例如数学问题求解、物理问题求解、逻辑推理、知识图谱推理等。通过提升LLM的推理能力,可以使其在这些任务中表现得更加出色,从而提高自动化问题解决的效率和准确性。此外,该方法还可以应用于教育领域,帮助学生更好地理解和掌握知识。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable efficiency in tackling various tasks based on human instructions, but studies reveal that they often struggle with tasks requiring reasoning, such as math or physics. This limitation raises questions about whether LLMs truly comprehend embedded knowledge or merely learn to replicate the token distribution without a true understanding of the content. In this paper, we delve into this problem and aim to enhance the reasoning capabilities of LLMs. First, we investigate if the model has genuine reasoning capabilities by visualizing the text generation process at the attention and representation level. Then, we formulate the reasoning process of LLMs into a causal framework, which provides a formal explanation of the problems observed in the visualization. Finally, building upon this causal framework, we propose Deconfounded Causal Adaptation (DCA), a novel parameter-efficient fine-tuning (PEFT) method to enhance the model's reasoning capabilities by encouraging the model to extract the general problem-solving skills and apply these skills to different questions. Experiments show that our method outperforms the baseline consistently across multiple benchmarks, and with only 1.2M tunable parameters, we achieve better or comparable results to other fine-tuning methods. This demonstrates the effectiveness and efficiency of our method in improving the overall accuracy and reliability of LLMs.