PUB: Plot Understanding Benchmark and Dataset for Evaluating Large Language Models on Synthetic Visual Data Interpretation
作者: Aneta Pawelec, Victoria Sara Wesołowska, Zuzanna Bączek, Piotr Sankowski
分类: cs.CL
发布日期: 2024-09-04
💡 一句话要点
提出PUB:用于评估大语言模型在合成视觉数据理解能力上的基准数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据可视化 基准数据集 视觉理解 多模态学习
📋 核心要点
- 现有LLM在数据可视化理解方面能力不足,限制了其在数据分析和决策制定中的应用。
- 提出PUB数据集,通过控制参数生成各类图表,并设计多模态提示,以评估LLM的视觉数据理解能力。
- 通过对多个先进LLM进行基准测试,揭示了它们在不同类型视觉数据解释方面的优缺点,为未来改进提供方向。
📝 摘要(中文)
本文提出了一种新的合成数据集,旨在评估大型语言模型(LLM)在解释各种形式的数据可视化方面的能力,包括时间序列、直方图、小提琴图、箱线图和聚类图等。该数据集使用受控参数生成,以确保全面覆盖潜在的真实场景。我们采用多模态文本提示,包含与图像中视觉数据相关的问题,来对ChatGPT或Gemini等多个最先进的模型进行基准测试,评估它们的理解和解释准确性。为了确保数据完整性,我们的基准数据集是自动生成的,完全是新的,并且模型在测试之前没有接触过。这种策略使我们能够评估模型真正解释和理解数据的能力,消除预先学习的响应的可能性,并允许对模型的能力进行公正的评估。我们还引入了定量指标来评估模型的性能,提供了一个强大而全面的评估工具。使用此数据集对多个最先进的LLM进行基准测试,揭示了不同程度的成功,突出了在解释各种类型的视觉数据方面的具体优势和劣势。结果为LLM的当前能力提供了宝贵的见解,并确定了需要改进的关键领域。这项工作为未来的研究和开发奠定了基础,旨在增强语言模型的视觉解释能力。未来,改进后的LLM具有强大的视觉解释能力,可以显著帮助自动化数据分析、科学研究、教育工具和商业智能应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在理解和解释数据可视化图表方面的能力不足的问题。现有方法主要依赖于真实世界的数据集,这些数据集可能存在偏差、标注不准确或数据泄露等问题,导致对LLM的评估结果不准确。此外,现有方法缺乏对LLM在不同类型图表上的理解能力的细粒度评估。
核心思路:论文的核心思路是构建一个完全合成的、参数可控的数据集,用于评估LLM在理解各种数据可视化图表方面的能力。通过控制数据集的生成过程,可以确保数据集的质量和多样性,并避免数据泄露等问题。同时,通过设计多模态文本提示,可以引导LLM理解图表中的信息,并评估其解释准确性。
技术框架:该研究的技术框架主要包括以下几个模块:1) 数据集生成模块:该模块使用受控参数生成各种类型的数据可视化图表,包括时间序列、直方图、小提琴图、箱线图和聚类图等。2) 提示生成模块:该模块根据图表内容生成多模态文本提示,包括与图表相关的自然语言问题。3) 模型评估模块:该模块使用生成的数据集和提示对LLM进行评估,并使用定量指标评估模型的性能。
关键创新:该论文的关键创新在于提出了一个完全合成的、参数可控的数据集(PUB),用于评估LLM在理解数据可视化图表方面的能力。与现有方法相比,PUB数据集具有以下优势:1) 数据质量高:数据集是自动生成的,避免了人工标注的错误和偏差。2) 数据多样性强:数据集包含各种类型的图表,覆盖了潜在的真实场景。3) 数据无泄露:数据集是全新的,模型在测试之前没有接触过。4) 评估细粒度:可以对LLM在不同类型图表上的理解能力进行细粒度评估。
关键设计:在数据集生成方面,论文使用了多种参数来控制图表的形状、分布和噪声水平。在提示生成方面,论文设计了多种类型的提示,包括描述性提示、比较性提示和推理性提示。在模型评估方面,论文使用了准确率、召回率和F1值等指标来评估模型的性能。具体参数设置和损失函数细节未知。
🖼️ 关键图片
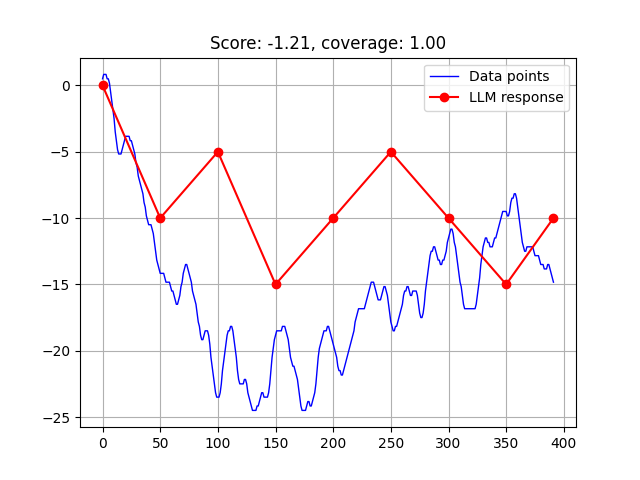
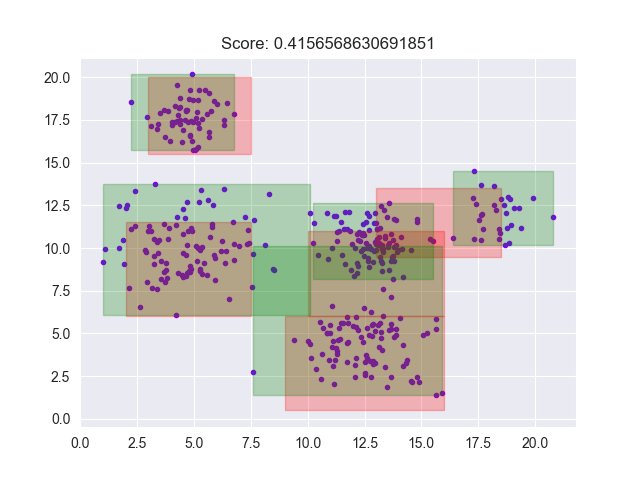

📊 实验亮点
通过在PUB数据集上对多个先进LLM进行基准测试,研究发现不同模型在解释不同类型视觉数据时表现出不同的优势和劣势。例如,某些模型在时间序列分析方面表现出色,而另一些模型则更擅长处理直方图。这些结果为进一步改进LLM的视觉理解能力提供了宝贵的见解,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可广泛应用于自动化数据分析、科学研究、教育工具和商业智能等领域。通过提升LLM对数据可视化的理解能力,可以实现更智能的数据分析和决策支持,例如自动生成数据报告、辅助科学研究人员分析实验数据、为学生提供个性化的学习辅导以及帮助企业进行商业决策。
📄 摘要(原文)
The ability of large language models (LLMs) to interpret visual representations of data is crucial for advancing their application in data analysis and decision-making processes. This paper presents a novel synthetic dataset designed to evaluate the proficiency of LLMs in interpreting various forms of data visualizations, including plots like time series, histograms, violins, boxplots, and clusters. Our dataset is generated using controlled parameters to ensure comprehensive coverage of potential real-world scenarios. We employ multimodal text prompts with questions related to visual data in images to benchmark several state-of-the-art models like ChatGPT or Gemini, assessing their understanding and interpretative accuracy. To ensure data integrity, our benchmark dataset is generated automatically, making it entirely new and free from prior exposure to the models being tested. This strategy allows us to evaluate the models' ability to truly interpret and understand the data, eliminating possibility of pre-learned responses, and allowing for an unbiased evaluation of the models' capabilities. We also introduce quantitative metrics to assess the performance of the models, providing a robust and comprehensive evaluation tool. Benchmarking several state-of-the-art LLMs with this dataset reveals varying degrees of success, highlighting specific strengths and weaknesses in interpreting diverse types of visual data. The results provide valuable insights into the current capabilities of LLMs and identify key areas for improvement. This work establishes a foundational benchmark for future research and development aimed at enhancing the visual interpretative abilities of language models. In the future, improved LLMs with robust visual interpretation skills can significantly aid in automated data analysis, scientific research, educational tools, and business intelligence applications.