A Comparative Study on Large Language Models for Log Parsing
作者: Merve Astekin, Max Hort, Leon Moonen
分类: cs.SE, cs.CL
发布日期: 2024-09-04
备注: Accepted for publication in the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM '24)
💡 一句话要点
对比研究大型语言模型在日志解析任务中的性能,发现开源模型可与商业模型媲美。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 日志解析 大型语言模型 开源模型 性能对比 软件运维
📋 核心要点
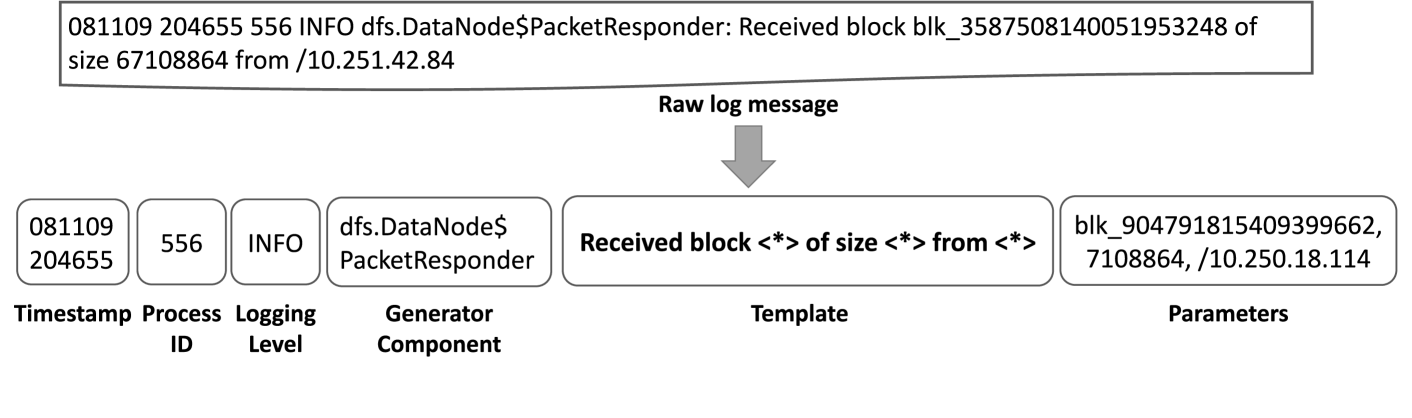
- 现有日志解析方法难以处理非结构化日志信息,需要自动化方法提取参数。
- 研究对比多种LLM在日志解析任务中的性能,探索开源模型替代商业模型的可能性。
- 实验结果表明,开源CodeLlama模型在日志模板提取方面优于商业GPT-3.5模型。
📝 摘要(中文)
背景:日志消息提供了关于软件系统状态的宝贵信息。这些信息以非结构化的方式提供,需要应用自动化方法来提取相关参数。为了简化这个过程,可以使用日志解析,将日志消息转换为结构化的日志模板。语言模型的最新进展促使一些研究将ChatGPT应用于日志解析任务,并取得了可喜的成果。然而,其他最先进的大型语言模型(LLM)在日志解析任务中的性能仍不清楚。目的:在本研究中,我们调查了当前最先进的LLM执行日志解析的能力。方法:我们选择了六个最新的LLM,包括付费专有模型(GPT-3.5、Claude 2.1)和四个免费使用的开源模型,并比较了它们在从一些成熟的开源项目中获得的系统日志上的性能。我们设计了两种不同的提示方法,并将LLM应用于16个不同项目的1354个日志模板。我们评估了它们的有效性,包括正确识别的模板数量,以及生成的模板与真实值之间的句法相似性。结果:我们发现免费使用的模型能够与付费模型竞争,其中CodeLlama正确提取的日志模板比GPT-3.5多10%。此外,我们还提供了关于语言模型可用性的定性见解(例如,使用它们的响应有多容易)。结论:我们的结果表明,与付费的专有竞争对手相比,一些较小的、免费使用的LLM可以显著地协助日志解析,特别是代码专用模型。
🔬 方法详解
问题定义:论文旨在解决如何利用大型语言模型(LLM)自动且高效地将非结构化的日志消息转换为结构化的日志模板的问题。现有方法,特别是依赖于传统算法的日志解析工具,在处理复杂和多样化的日志格式时表现不佳,需要大量的人工干预和规则定义。此外,商业LLM的成本较高,限制了其在日志解析领域的广泛应用。
核心思路:论文的核心思路是探索和评估不同类型的LLM(包括付费的商业模型和免费的开源模型)在日志解析任务中的性能。通过设计不同的提示策略,引导LLM理解日志消息的语义,并生成相应的结构化模板。核心在于比较不同模型的优劣,找出在性能、成本和易用性方面更具优势的解决方案。
技术框架:该研究的技术框架主要包括以下几个步骤:1)选择代表性的LLM,包括GPT-3.5、Claude 2.1以及CodeLlama等开源模型;2)收集来自多个开源项目的真实系统日志数据;3)设计两种不同的提示方法,用于指导LLM进行日志解析;4)使用LLM生成日志模板;5)评估生成的模板的准确性和句法相似性,并进行定性分析。
关键创新:该研究的关键创新在于对多种LLM在日志解析任务中的性能进行了全面的对比分析,特别强调了开源模型与商业模型的竞争能力。研究结果表明,一些专门针对代码的开源LLM在日志解析任务中可以超越商业模型,这为降低日志解析的成本和提高效率提供了新的思路。
关键设计:研究中采用了两种不同的提示方法,具体细节未知。评估指标包括正确识别的模板数量和生成的模板与真实值之间的句法相似性。此外,研究还进行了定性分析,评估了不同LLM的易用性,例如,模型响应的可理解性和可操作性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,开源的CodeLlama模型在日志模板提取的准确率上超过了商业的GPT-3.5模型约10%。这表明,在特定任务上,经过专门训练的开源模型可以与甚至超越大型商业模型,为企业提供了更经济高效的解决方案。
🎯 应用场景
该研究成果可应用于软件运维、系统监控、安全分析等领域。通过自动化的日志解析,可以快速提取关键信息,帮助运维人员诊断问题、监控系统状态、检测安全威胁。开源LLM的应用可以降低成本,提高日志分析的效率和智能化水平,具有广阔的应用前景。
📄 摘要(原文)
Background: Log messages provide valuable information about the status of software systems. This information is provided in an unstructured fashion and automated approaches are applied to extract relevant parameters. To ease this process, log parsing can be applied, which transforms log messages into structured log templates. Recent advances in language models have led to several studies that apply ChatGPT to the task of log parsing with promising results. However, the performance of other state-of-the-art large language models (LLMs) on the log parsing task remains unclear. Aims: In this study, we investigate the current capability of state-of-the-art LLMs to perform log parsing. Method: We select six recent LLMs, including both paid proprietary (GPT-3.5, Claude 2.1) and four free-to-use open models, and compare their performance on system logs obtained from a selection of mature open-source projects. We design two different prompting approaches and apply the LLMs on 1, 354 log templates across 16 different projects. We evaluate their effectiveness, in the number of correctly identified templates, and the syntactic similarity between the generated templates and the ground truth. Results: We found that free-to-use models are able to compete with paid models, with CodeLlama extracting 10% more log templates correctly than GPT-3.5. Moreover, we provide qualitative insights into the usability of language models (e.g., how easy it is to use their responses). Conclusions: Our results reveal that some of the smaller, free-to-use LLMs can considerably assist log parsing compared to their paid proprietary competitors, especially code-specialized models.