DetectiveQA: Evaluating Long-Context Reasoning on Detective Novels
作者: Zhe Xu, Jiasheng Ye, Xiaoran Liu, Xiangyang Liu, Tianxiang Sun, Zhigeng Liu, Qipeng Guo, Linlin Li, Qun Liu, Xuanjing Huang, Xipeng Qiu
分类: cs.CL
发布日期: 2024-09-04 (更新: 2025-03-14)
💡 一句话要点
提出DetectiveQA数据集,用于评估LLM在侦探小说长文本推理中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 大型语言模型 侦探小说 数据集 叙事推理
📋 核心要点
- 现有大型语言模型(LLM)在长文本推理方面仍面临挑战,缺乏专门的数据集进行有效评估。
- DetectiveQA数据集利用侦探小说构建,包含人工标注的问题和推理步骤,用于评估LLM的长文本推理能力。
- 实验结果表明,主流LLM在DetectiveQA数据集上表现出长文本推理和证据检索方面的不足,为后续研究提供了方向。
📝 摘要(中文)
本文提出了DetectiveQA,一个专门为长文本叙事推理设计的数据集。该数据集利用平均超过10万tokens的侦探小说,包含1200个中英文人工标注的问题,每个问题都配有相应的参考推理步骤。此外,本文还引入了一种逐步推理指标,以增强对LLM推理过程的评估。通过验证该方法并评估包括GPT-4、Claude和LLaMA在内的主流LLM,揭示了它们在长文本推理方面持续存在的挑战,并展示了它们在证据检索方面的不足。研究结果为长文本推理的研究提供了有价值的见解,并为更严格的评估奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在长文本推理方面的评估问题。现有方法缺乏专门针对长文本叙事推理的数据集,难以有效评估LLM在复杂情境下的推理能力。现有数据集通常长度较短,无法充分测试LLM处理长距离依赖关系和整合多方面信息的能力。
核心思路:论文的核心思路是构建一个基于侦探小说的数据集,利用侦探小说篇幅较长、情节复杂、包含大量线索的特点,来测试LLM在长文本中进行推理和证据检索的能力。通过人工标注问题和推理步骤,为评估LLM的推理过程提供参考标准。
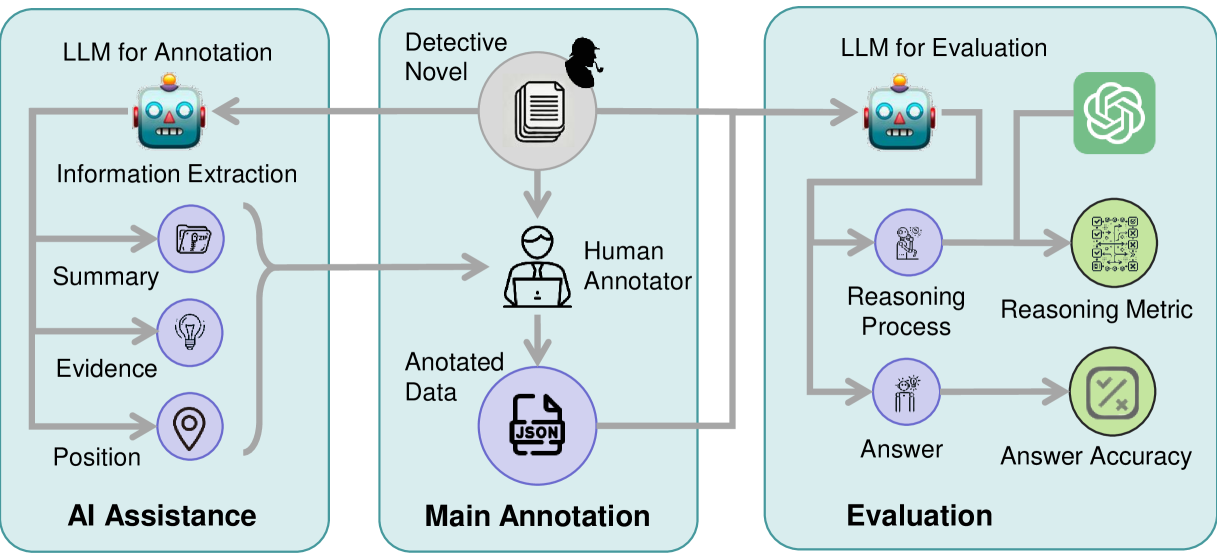
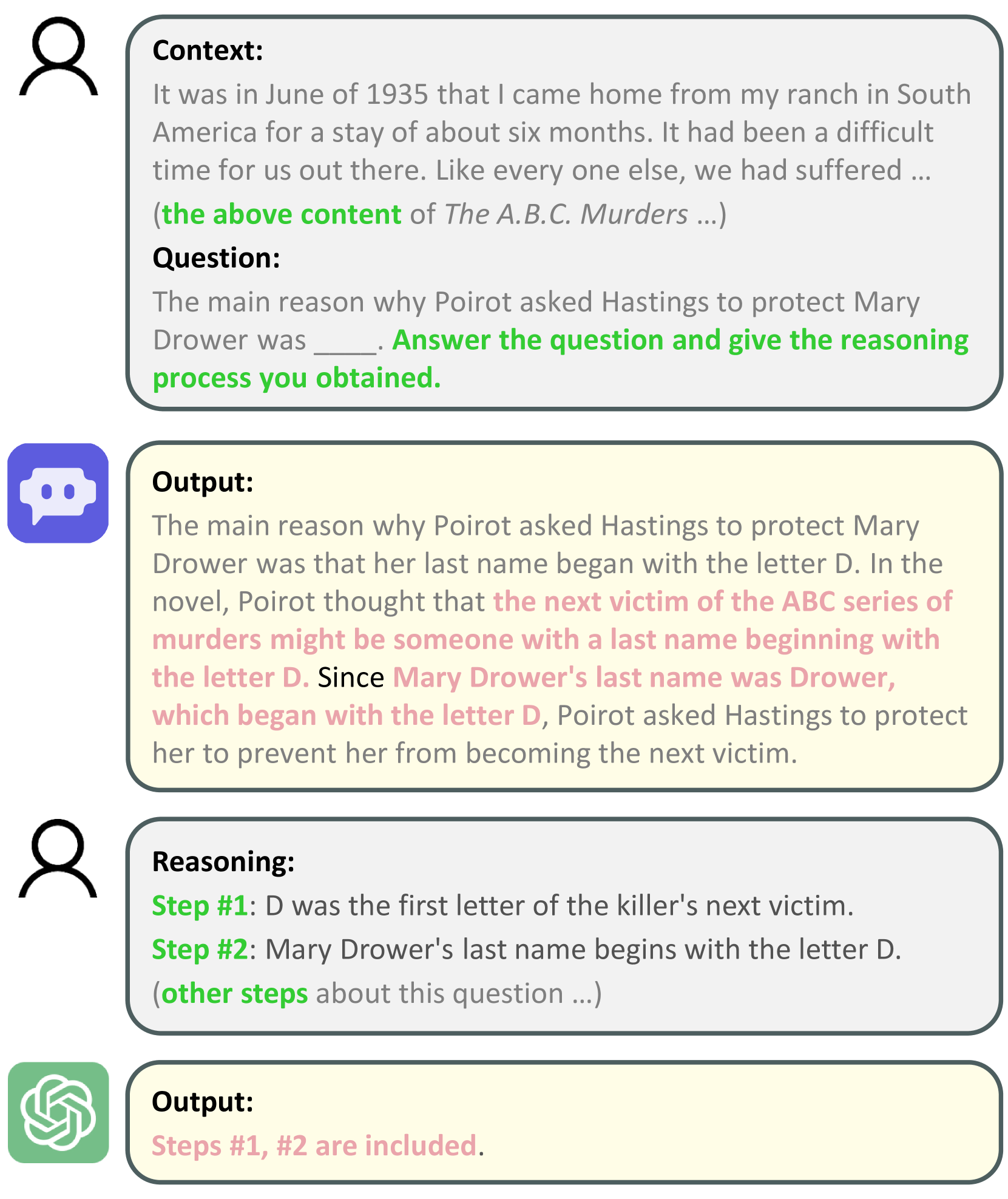
技术框架:DetectiveQA数据集的构建流程主要包括以下几个阶段:1) 选择侦探小说作为数据来源;2) 人工标注问题,问题需要基于小说内容进行推理才能回答;3) 提供参考推理步骤,详细描述从小说中提取证据并进行推理的过程;4) 设计逐步推理指标,用于更细粒度地评估LLM的推理过程。
关键创新:DetectiveQA数据集的关键创新在于其专注于长文本叙事推理,并提供了人工标注的推理步骤。与现有数据集相比,DetectiveQA更具挑战性,能够更有效地评估LLM在复杂情境下的推理能力。逐步推理指标的设计也为评估LLM的推理过程提供了新的视角。
关键设计:DetectiveQA数据集使用了平均超过10万tokens的侦探小说,确保了长文本的长度。人工标注的问题涵盖了不同类型的推理,例如演绎推理、归纳推理和溯因推理。逐步推理指标的设计考虑了推理过程的完整性和准确性,能够更全面地评估LLM的推理能力。具体参数设置和网络结构未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,包括GPT-4、Claude和LLaMA在内的主流LLM在DetectiveQA数据集上表现出长文本推理和证据检索方面的不足。这表明即使是最先进的LLM在处理长文本推理任务时仍然面临挑战,需要进一步的研究和改进。具体的性能数据和提升幅度未在摘要中提及,属于未知信息。
🎯 应用场景
DetectiveQA数据集可用于评估和提升LLM在长文本理解和推理方面的能力,尤其是在需要处理复杂叙事和大量信息的场景中,如法律文本分析、金融报告解读、医学诊断等。该数据集的发布将促进长文本推理领域的研究,并推动LLM在实际应用中的落地。
📄 摘要(原文)
Recently, significant efforts have been devoted to enhancing the long-context capabilities of Large Language Models (LLMs), particularly in long-context reasoning. To facilitate this research, we propose \textbf{DetectiveQA}, a dataset specifically designed for narrative reasoning within long contexts. We leverage detective novels, averaging over 100k tokens, to create a dataset containing 1200 human-annotated questions in both Chinese and English, each paired with corresponding reference reasoning steps. Furthermore, we introduce a step-wise reasoning metric, which enhances the evaluation of LLMs' reasoning processes. We validate our approach and evaluate the mainstream LLMs, including GPT-4, Claude, and LLaMA, revealing persistent long-context reasoning challenges and demonstrating their evidence-retrieval challenges. Our findings offer valuable insights into the study of long-context reasoning and lay the base for more rigorous evaluations.