STAB: Speech Tokenizer Assessment Benchmark
作者: Shikhar Vashishth, Harman Singh, Shikhar Bharadwaj, Sriram Ganapathy, Chulayuth Asawaroengchai, Kartik Audhkhasi, Andrew Rosenberg, Ankur Bapna, Bhuvana Ramabhadran
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-09-04
备注: 5 pages
💡 一句话要点
提出STAB:语音Tokenizer评估基准,用于全面评估和理解语音Tokenizer的特性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音Tokenizer 评估基准 语音处理 大型语言模型 语音识别
📋 核心要点
- 现有语音Tokenizer缺乏系统性评估,难以确定其在不同下游任务中的适用性和泛化能力。
- STAB通过设计一系列评估指标,从多个维度分析语音Tokenizer的特性,无需大量下游任务实验。
- 实验结果表明,STAB指标与下游任务性能具有相关性,可用于指导Tokenizer的选择和优化。
📝 摘要(中文)
本文提出STAB(Speech Tokenizer Assessment Benchmark),一个系统性的评估框架,旨在全面评估语音Tokenizer并揭示其内在特性。将语音表示为离散token提供了一种将语音转换为类似于文本格式的框架,从而能够将语音用作广泛应用的大型语言模型(LLM)的输入。目前,虽然已经提出了几种语音Tokenizer,但对于特定下游任务所需的Tokenizer属性及其整体泛化能力存在不确定性。跨不同下游任务评估Tokenizer的性能是一项计算密集型工作,对可扩展性提出了挑战。STAB旨在规避这一需求,通过更深入地理解语音tokenization的底层机制,为加速未来Tokenizer模型的发展提供有价值的资源,并支持使用标准化基准进行比较分析。论文评估了STAB指标,并将其与一系列语音任务和Tokenizer选择中的下游任务性能相关联。
🔬 方法详解
问题定义:现有语音Tokenizer的评估缺乏统一的标准和方法,难以客观地比较不同Tokenizer的性能,也难以了解Tokenizer的内在特性,从而阻碍了语音Tokenizer的进一步发展。针对特定下游任务选择合适的Tokenizer也缺乏有效指导。
核心思路:STAB的核心思路是通过设计一系列与Tokenizer特性相关的评估指标,直接评估Tokenizer本身,从而避免了对大量下游任务进行评估的需求。这些指标旨在捕捉Tokenizer在不同方面的表现,例如token的利用率、token的长度分布、以及token与语音信号的对齐程度等。
技术框架:STAB框架主要包含以下几个阶段:1)选择待评估的语音Tokenizer;2)准备评估数据集,该数据集应包含不同语境和口音的语音数据;3)使用Tokenizer将语音数据转换为token序列;4)计算预定义的评估指标,这些指标涵盖了Tokenizer的多个方面,例如token的利用率、token的长度分布、以及token与语音信号的对齐程度等;5)分析评估结果,并将其与下游任务的性能进行关联,从而验证STAB指标的有效性。
关键创新:STAB的关键创新在于提出了一套系统性的、与下游任务无关的语音Tokenizer评估指标。这些指标能够直接反映Tokenizer的内在特性,从而避免了对大量下游任务进行评估的需求。此外,STAB还提供了一个标准化的评估框架,使得不同Tokenizer之间的比较更加客观和公平。
关键设计:STAB的关键设计包括:1)选择合适的评估指标,这些指标应能够捕捉Tokenizer在不同方面的表现;2)设计合理的评估流程,确保评估结果的可靠性和可重复性;3)使用足够大的评估数据集,以保证评估结果的泛化能力。具体的指标包括token utilization, token length distribution, token-speech alignment等。这些指标的具体计算方法在论文中有详细描述。
🖼️ 关键图片

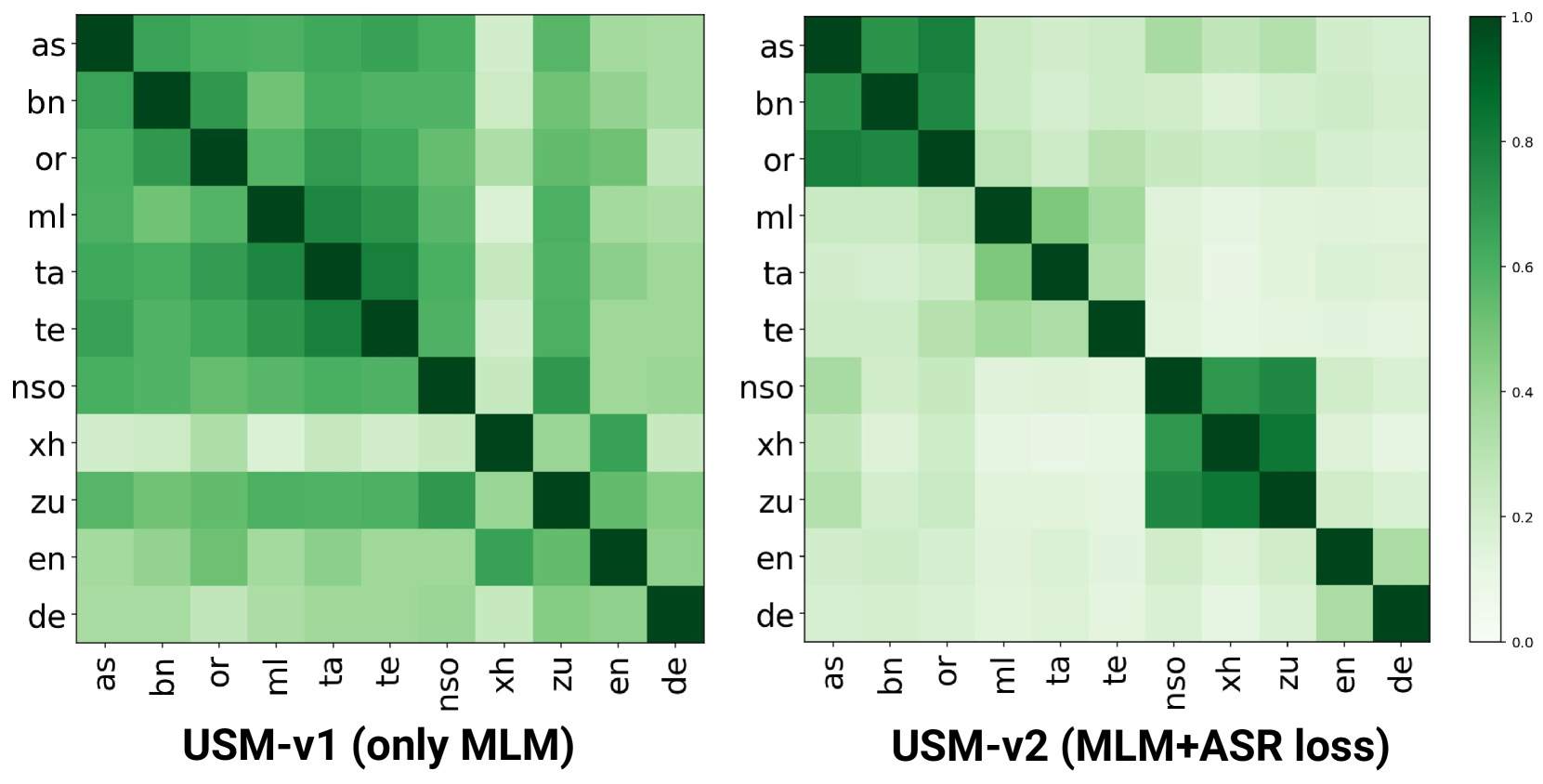
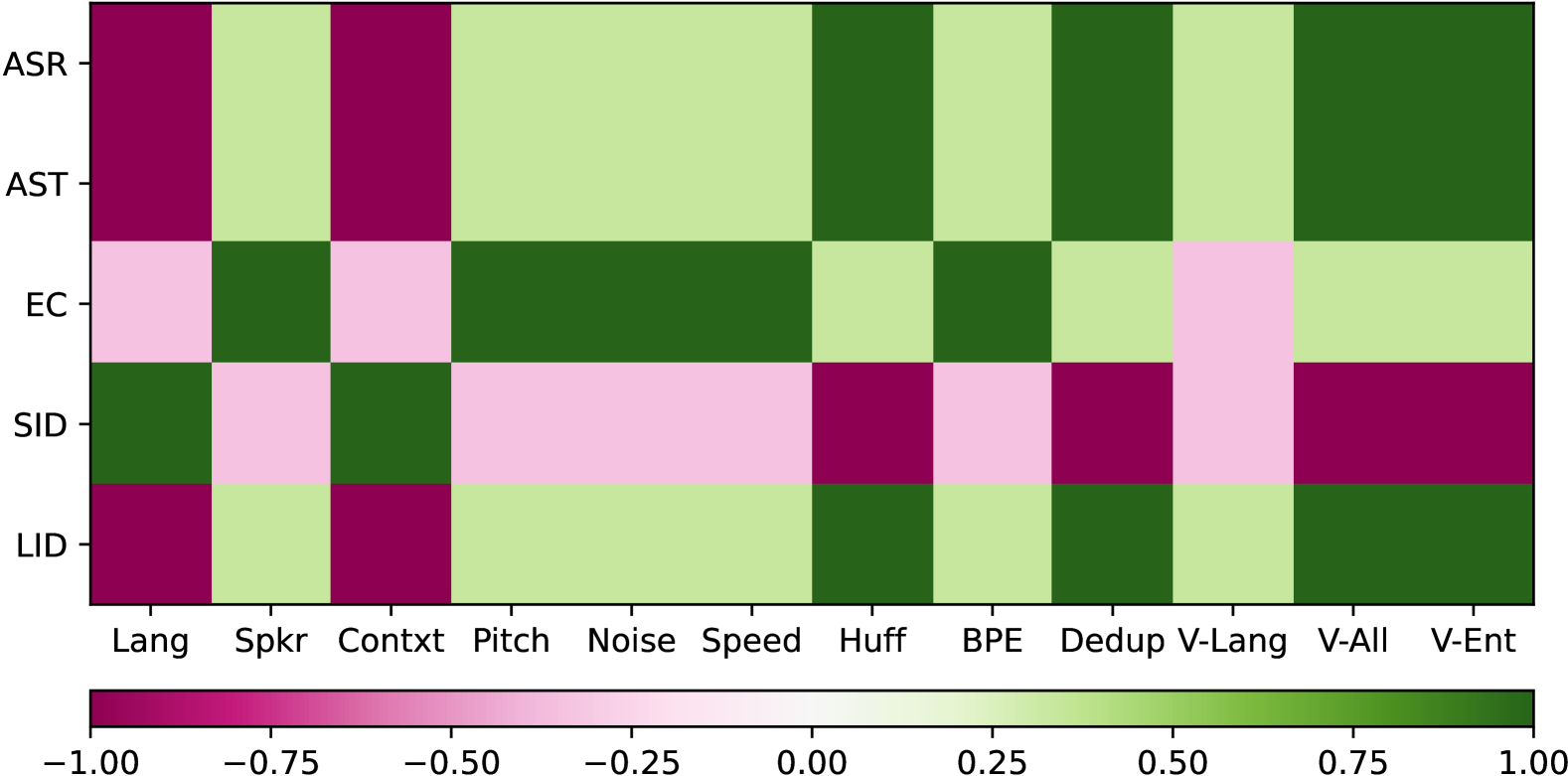
📊 实验亮点
论文通过实验验证了STAB指标与下游任务性能之间的相关性。具体来说,实验结果表明,在语音识别任务中,具有较高token利用率和较好token-speech对齐的Tokenizer通常能够取得更好的性能。此外,实验还表明,STAB指标可以用于指导Tokenizer的选择和优化,从而提高下游任务的性能。
🎯 应用场景
STAB可应用于语音识别、语音合成、语音翻译等多个领域。它可以帮助研究人员和工程师选择合适的语音Tokenizer,从而提高下游任务的性能。此外,STAB还可以用于指导语音Tokenizer的设计和优化,从而推动语音处理技术的发展。未来,STAB可以扩展到支持更多语言和更多类型的语音数据。
📄 摘要(原文)
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.