How Privacy-Savvy Are Large Language Models? A Case Study on Compliance and Privacy Technical Review
作者: Yang Liu, Xichou Zhu, Zhou Shen, Yi Liu, Min Li, Yujun Chen, Benzi John, Zhenzhen Ma, Tao Hu, Zhi Li, Bolong Yang, Manman Wang, Zongxing Xie, Peng Liu, Dan Cai, Junhui Wang
分类: cs.CL
发布日期: 2024-09-04 (更新: 2025-02-14)
备注: 8 pages, 4 figures
💡 一句话要点
评估大语言模型在隐私合规性方面的能力,并提出隐私技术审查框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私合规 隐私技术审查 数据保护 隐私信息提取
📋 核心要点
- 现有大型语言模型在隐私合规性方面应用不足,无法有效识别和处理隐私风险。
- 提出隐私技术审查(PTR)框架,通过隐私信息提取、关键点检测和问答等任务评估LLM的隐私保护能力。
- 实验结果表明LLM在隐私审查方面有潜力,但与法律标准仍有差距,需进一步改进模型。
📝 摘要(中文)
本文旨在评估大型语言模型(LLMs)在隐私合规和技术隐私审查方面的性能。随着LLMs在语言生成、摘要和复杂问答等领域的广泛应用,其在隐私合规方面的能力亟待考察,以确保其符合全球隐私标准并保护敏感用户数据。本文提出了一个隐私技术审查(PTR)框架,旨在降低软件开发生命周期中的隐私风险。通过对BERT、GPT-3.5、GPT-4等主流LLMs进行实证评估,考察了它们在隐私信息提取(PIE)、法律和监管关键点检测(KPD)以及基于隐私策略和数据保护法规的问答(QA)等任务中的表现。实验结果表明,LLMs在自动化隐私审查和识别监管差异方面具有潜力,但在完全符合不断发展的法律标准方面仍存在显著差距。本文为提升LLMs的隐私合规能力提供了可行的建议,强调需要加强模型改进,并更好地与法律和监管要求相结合。本研究强调了开发隐私感知LLMs的重要性,这既能支持企业合规工作,又能保障用户隐私权。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在隐私合规性方面的不足问题。现有方法难以有效识别和处理软件开发生命周期中的隐私风险,无法充分满足不断发展的法律和监管要求。这导致企业在隐私合规方面面临挑战,同时也威胁着用户隐私。
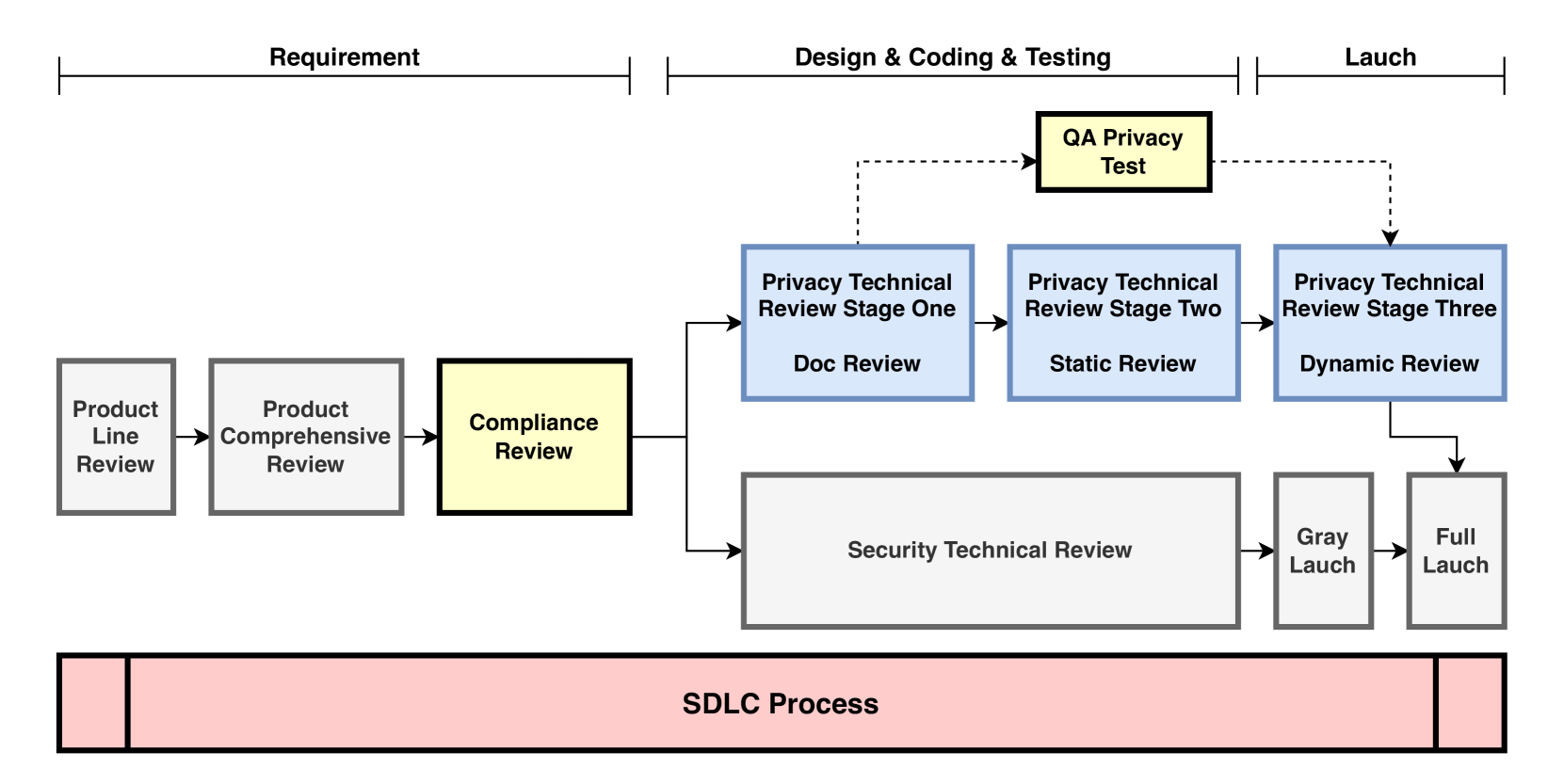
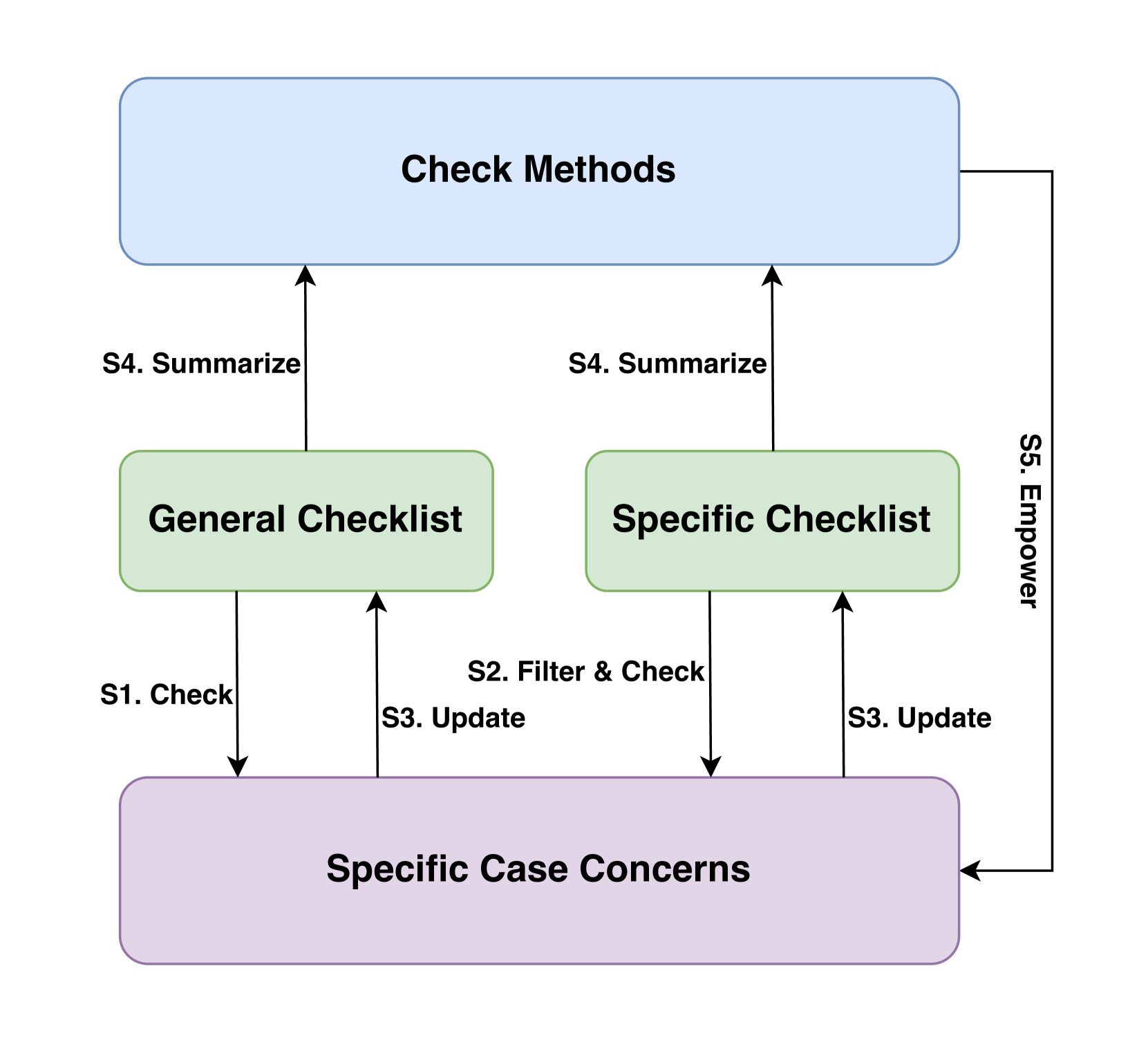
核心思路:论文的核心思路是构建一个隐私技术审查(PTR)框架,用于系统性地评估LLMs在隐私相关任务中的表现。通过定义一系列与隐私合规相关的任务,例如隐私信息提取(PIE)、法律和监管关键点检测(KPD)以及基于隐私策略和数据保护法规的问答(QA),来量化LLMs的隐私保护能力。这种方法旨在揭示LLMs在隐私合规方面的优势和不足,并为改进模型提供指导。
技术框架:PTR框架包含以下主要模块:1) 数据收集与准备:收集隐私策略、法律法规等相关数据,并进行预处理。2) 任务定义:定义PIE、KPD和QA等具体任务,并制定评估指标。3) 模型评估:使用不同的LLMs(如BERT、GPT-3.5、GPT-4)执行定义的任务,并记录性能数据。4) 结果分析:分析实验结果,识别LLMs在隐私合规方面的优势和不足。5) 改进建议:根据分析结果,提出改进LLMs隐私保护能力的建议。
关键创新:论文的关键创新在于提出了PTR框架,这是一个系统性的方法,用于评估和改进LLMs在隐私合规方面的能力。与以往的研究相比,PTR框架更加全面和实用,它不仅关注LLMs的性能,还关注其在实际应用中的可行性。此外,论文还通过实验验证了PTR框架的有效性,并为未来的研究提供了参考。
关键设计:论文的关键设计包括:1) 任务定义:精心设计的PIE、KPD和QA任务,能够全面评估LLMs的隐私保护能力。2) 评估指标:使用精确率、召回率和F1值等指标,能够客观地衡量LLMs的性能。3) 模型选择:选择具有代表性的LLMs(如BERT、GPT-3.5、GPT-4),能够反映当前LLMs的整体水平。4) 实验设置:采用合理的实验设置,能够保证实验结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMs在隐私信息提取和关键点检测方面表现出一定的潜力,但与人工审查相比仍存在差距。例如,GPT-4在某些任务上的F1值高于其他模型,但仍未能完全覆盖所有隐私风险。实验结果强调了持续改进LLMs隐私保护能力的重要性。
🎯 应用场景
该研究成果可应用于自动化隐私合规检查、软件开发生命周期中的隐私风险评估、以及帮助企业更好地理解和遵守数据保护法规。通过提升LLMs的隐私保护能力,可以降低企业在隐私合规方面的成本,并增强用户对数据安全的信任,从而促进人工智能技术的健康发展。
📄 摘要(原文)
The recent advances in large language models (LLMs) have significantly expanded their applications across various fields such as language generation, summarization, and complex question answering. However, their application to privacy compliance and technical privacy reviews remains under-explored, raising critical concerns about their ability to adhere to global privacy standards and protect sensitive user data. This paper seeks to address this gap by providing a comprehensive case study evaluating LLMs' performance in privacy-related tasks such as privacy information extraction (PIE), legal and regulatory key point detection (KPD), and question answering (QA) with respect to privacy policies and data protection regulations. We introduce a Privacy Technical Review (PTR) framework, highlighting its role in mitigating privacy risks during the software development life-cycle. Through an empirical assessment, we investigate the capacity of several prominent LLMs, including BERT, GPT-3.5, GPT-4, and custom models, in executing privacy compliance checks and technical privacy reviews. Our experiments benchmark the models across multiple dimensions, focusing on their precision, recall, and F1-scores in extracting privacy-sensitive information and detecting key regulatory compliance points. While LLMs show promise in automating privacy reviews and identifying regulatory discrepancies, significant gaps persist in their ability to fully comply with evolving legal standards. We provide actionable recommendations for enhancing LLMs' capabilities in privacy compliance, emphasizing the need for robust model improvements and better integration with legal and regulatory requirements. This study underscores the growing importance of developing privacy-aware LLMs that can both support businesses in compliance efforts and safeguard user privacy rights.