Multi-Source Knowledge Pruning for Retrieval-Augmented Generation: A Benchmark and Empirical Study
作者: Shuo Yu, Mingyue Cheng, Qi Liu, Daoyu Wang, Jiqian Yang, Jie Ouyang, Yucong Luo, Chenyi Lei, Enhong Chen
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-09-03 (更新: 2025-10-09)
备注: Accepted by CIKM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出PruningRAG框架,解决RAG中多源知识融合与噪声干扰问题,并构建基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多源知识 知识剪枝 大型语言模型 RAG框架
📋 核心要点
- 现有RAG方法在处理多源知识时,难以有效区分相关信息和噪声,导致生成质量下降。
- PruningRAG框架通过多粒度剪枝策略,优化知识整合,减少噪声干扰,提升RAG性能。
- 实验表明,PruningRAG在多种RAG变体上均能稳定提升性能,验证了其鲁棒性和通用性。
📝 摘要(中文)
检索增强生成(RAG)通过整合外部知识来缓解大型语言模型(LLM)的幻觉问题,正日益受到重视。虽然已经有很多研究,但大多数研究都集中在单一类型的外部知识源上。然而,在实际应用中,大多数情况涉及来自各种来源的多样化知识,但这一领域的研究较少。主要的困境是缺乏包含多个知识源的合适数据集,以及对相关问题的预先探索。为了应对这些挑战,我们标准化了一个基准数据集,该数据集结合了跨不同和互补领域的结构化和非结构化知识。基于此数据集,我们进一步开发了一个即插即用的RAG框架 extbf{PruningRAG},其主要特点是使用多粒度剪枝策略来优化相关信息的整合,同时最大限度地减少误导性上下文。它始终如一地提高了各种现有RAG变体的性能,证明了其鲁棒性和广泛适用性。基于标准化的数据集和PruningRAG,我们还报告了一系列实验结果以及深刻的发现。我们的数据集和代码是公开可用的,旨在推进RAG社区未来的研究。
🔬 方法详解
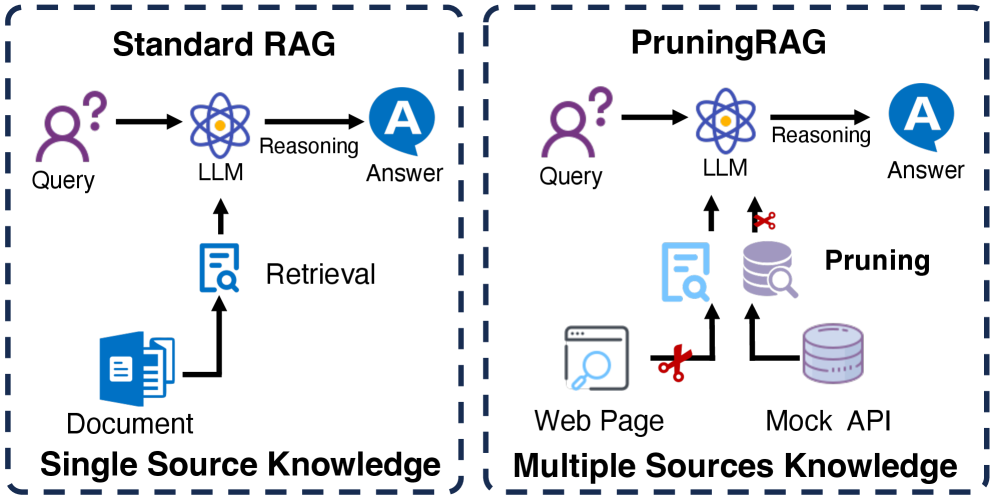
问题定义:论文旨在解决检索增强生成(RAG)在处理多源知识时面临的挑战。现有RAG方法通常只关注单一知识源,或者简单地将多个知识源的信息拼接在一起,导致相关信息被噪声淹没,影响生成质量。现有方法缺乏有效区分和筛选多源知识的能力,难以充分利用多源知识的优势。
核心思路:论文的核心思路是引入多粒度剪枝策略,对检索到的多源知识进行筛选和过滤,保留与问题最相关的信息,去除噪声和冗余信息。通过剪枝,可以减少LLM处理的上下文长度,提高生成效率和质量。这种方法旨在优化知识整合,提高RAG系统的鲁棒性和准确性。
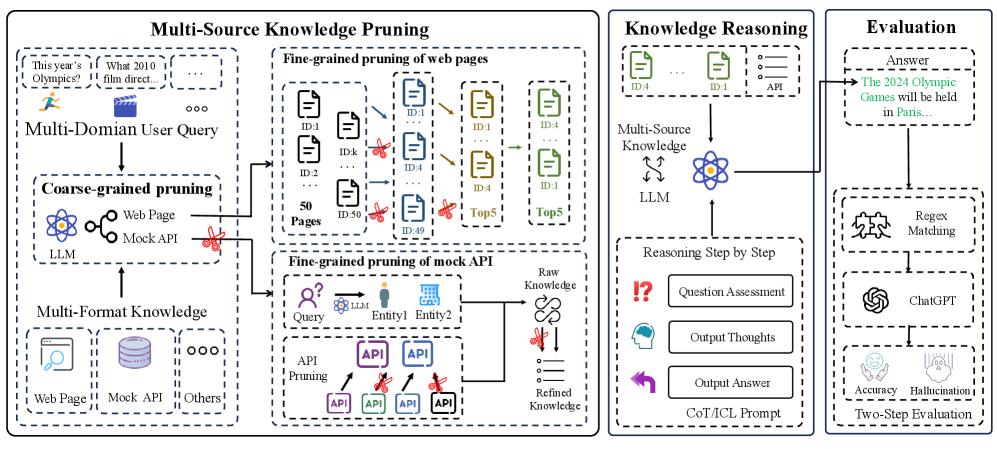
技术框架:PruningRAG框架是一个即插即用的RAG框架,可以与现有的RAG变体结合使用。其主要流程包括:1) 从多个知识源检索相关文档;2) 对检索到的文档进行多粒度剪枝,包括段落级别、句子级别和词级别;3) 将剪枝后的知识输入LLM进行生成。框架的核心是剪枝模块,该模块使用不同的策略来评估和过滤知识,保留最相关的信息。
关键创新:论文的关键创新在于提出了多粒度剪枝策略,该策略能够更精细地筛选知识,去除噪声和冗余信息。与传统的基于相似度或相关性的筛选方法不同,多粒度剪枝策略综合考虑了不同粒度的信息,能够更准确地评估知识的重要性。此外,论文还构建了一个包含结构化和非结构化知识的基准数据集,为多源知识RAG的研究提供了基础。
关键设计:论文中,多粒度剪枝策略的具体实现包括:1) 段落级别剪枝:根据段落与问题的相关性得分,去除不相关的段落;2) 句子级别剪枝:根据句子与问题的相关性得分,去除不相关的句子;3) 词级别剪枝:根据词语的重要性得分,去除不重要的词语。相关性得分可以使用不同的方法计算,例如基于Transformer的交叉注意力机制。框架没有明确提及损失函数或网络结构等细节,可能依赖于预训练的LLM和现有的RAG方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PruningRAG框架在多种RAG变体上均能稳定提升性能。具体而言,在基准数据集上,PruningRAG相比于baseline方法,在生成质量、准确性和相关性等方面均有显著提升。该框架的鲁棒性和通用性得到了验证。
🎯 应用场景
该研究成果可应用于智能问答、知识图谱构建、内容生成等领域。通过整合多源知识,可以提高问答系统的准确性和覆盖范围,生成更丰富、更全面的内容。该方法尤其适用于需要处理大量异构知识的场景,例如金融分析、医疗诊断等。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is increasingly recognized as an effective approach to mitigating the hallucination of large language models (LLMs) through the integration of external knowledge. While numerous efforts, most studies focus on a single type of external knowledge source. However, in real-world applications, most situations involve diverse knowledge from various sources, yet this area has been less explored. The main dilemma is the lack of a suitable dataset containing multiple knowledge sources and pre-exploration of the associated issues. To address these challenges, we standardize a benchmark dataset that combines structured and unstructured knowledge across diverse and complementary domains. Based on this dataset, we further develop a plug-and-play RAG framework, \textbf{PruningRAG}, whose main characteristic is the use of multi-granularity pruning strategies to optimize the integration of relevant information while minimizing misleading context. It consistently improves performance across various existing RAG variants, demonstrating its robustness and broad applicability. Building upon the standardized dataset and PruningRAG, we also report a series of experimental results, as well as insightful findings. Our dataset and code are publicly available\footnote{https://github.com/USTCAGI/PruningRAG}, with the aim of advancing future research in the RAG community.