LongGenBench: Benchmarking Long-Form Generation in Long Context LLMs
作者: Yuhao Wu, Ming Shan Hee, Zhiqing Hu, Roy Ka-Wei Lee
分类: cs.CL
发布日期: 2024-09-03 (更新: 2025-01-23)
备注: ICLR 2025; Github: https://github.com/mozhu621/LongGenBench/
💡 一句话要点
LongGenBench:提出长文本生成评测基准,揭示现有LLM在长上下文任务中的不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 大型语言模型 评测基准 长上下文 指令遵循 文本连贯性 生成质量
📋 核心要点
- 现有长文本评测benchmark缺乏对生成质量的有效评估,无法反映LLM在实际应用中的长文本生成能力。
- LongGenBench通过设计包含特定事件或约束的长文本生成任务,全面评估LLM在不同场景和指令下的生成性能。
- 实验结果表明,现有LLM在LongGenBench上表现不佳,尤其是在长文本生成时,揭示了现有模型在长文本生成方面的不足。
📝 摘要(中文)
现有评测基准如NIAH、Ruler和Needlebench侧重于评估模型理解长上下文输入序列的能力,但忽略了高质量长文本生成这一关键维度。设计方案、技术文档和创意写作等应用依赖于连贯、遵循指令的长序列输出,而现有基准未能充分解决这一挑战。为此,我们提出了LongGenBench,这是一个旨在严格评估大型语言模型(LLM)在遵循复杂指令的同时生成长文本能力的新型基准。LongGenBench通过要求在生成的文本中包含特定事件或约束的任务,评估模型在四种不同场景、三种指令类型和两种生成长度(16K和32K tokens)下的性能。对十个最先进的LLM的评估表明,尽管在Ruler上取得了不错的成绩,但所有模型在LongGenBench上的长文本生成方面都表现不佳,尤其是在文本长度增加时。这表明当前的LLM尚未具备满足现实世界长文本生成需求的能力。
🔬 方法详解
问题定义:现有长文本评测基准主要关注模型对长上下文的理解能力,而忽略了长文本生成质量的评估。实际应用中,如设计方案、技术文档等,需要模型生成连贯、符合指令的长文本,现有方法无法有效评估模型在这些场景下的表现。现有benchmark的痛点在于无法有效衡量模型生成长文本的连贯性、指令遵循度和整体质量。
核心思路:LongGenBench的核心思路是设计一系列需要生成长文本的任务,并在任务中设置特定的事件或约束条件。通过评估模型生成文本中是否包含这些事件或约束,以及生成文本的连贯性和质量,来全面评估模型在长文本生成方面的能力。这种设计能够更真实地反映模型在实际应用中的表现。
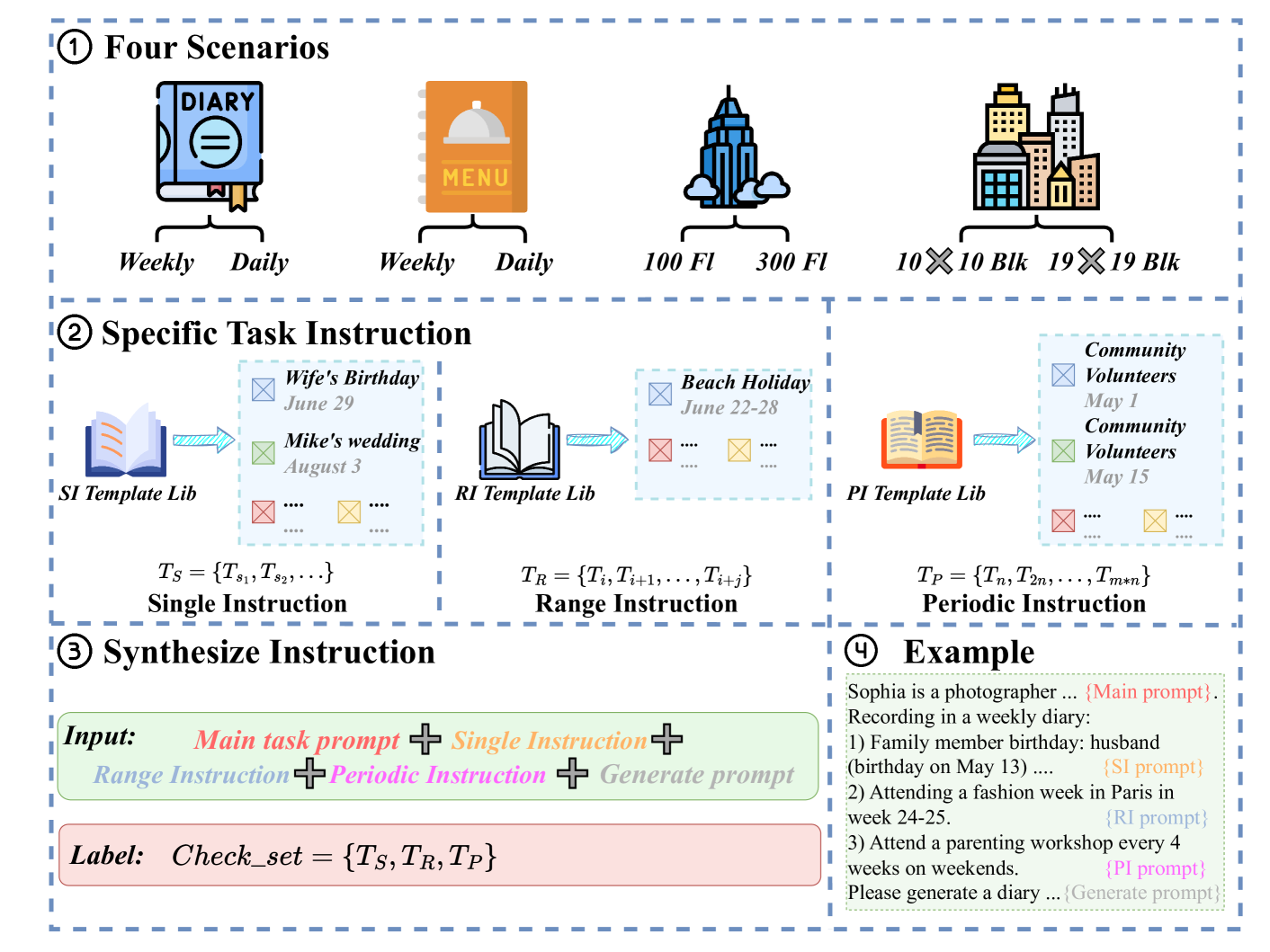
技术框架:LongGenBench包含四个不同的场景,三种指令类型和两种生成长度(16K和32K tokens)。四个场景包括:故事生成、技术文档生成、新闻报道生成和对话生成。三种指令类型包括:开放式生成、条件生成和约束生成。通过组合这些场景、指令类型和生成长度,LongGenBench可以全面评估模型在不同情况下的长文本生成能力。
关键创新:LongGenBench的关键创新在于其评测任务的设计。与现有benchmark只关注上下文理解不同,LongGenBench侧重于评估模型生成长文本的质量,包括连贯性、指令遵循度和整体流畅性。通过要求模型在生成文本中包含特定事件或约束,LongGenBench可以更有效地评估模型在实际应用中的表现。
关键设计:LongGenBench的关键设计包括:1) 任务的多样性,涵盖了不同的场景和指令类型;2) 评估指标的全面性,包括事件/约束的包含率、文本的连贯性和流畅性;3) 生成长度的设置,包括16K和32K tokens,以评估模型在不同长度下的表现。此外,LongGenBench还提供了一套评估脚本,方便用户进行评测。
🖼️ 关键图片
📊 实验亮点
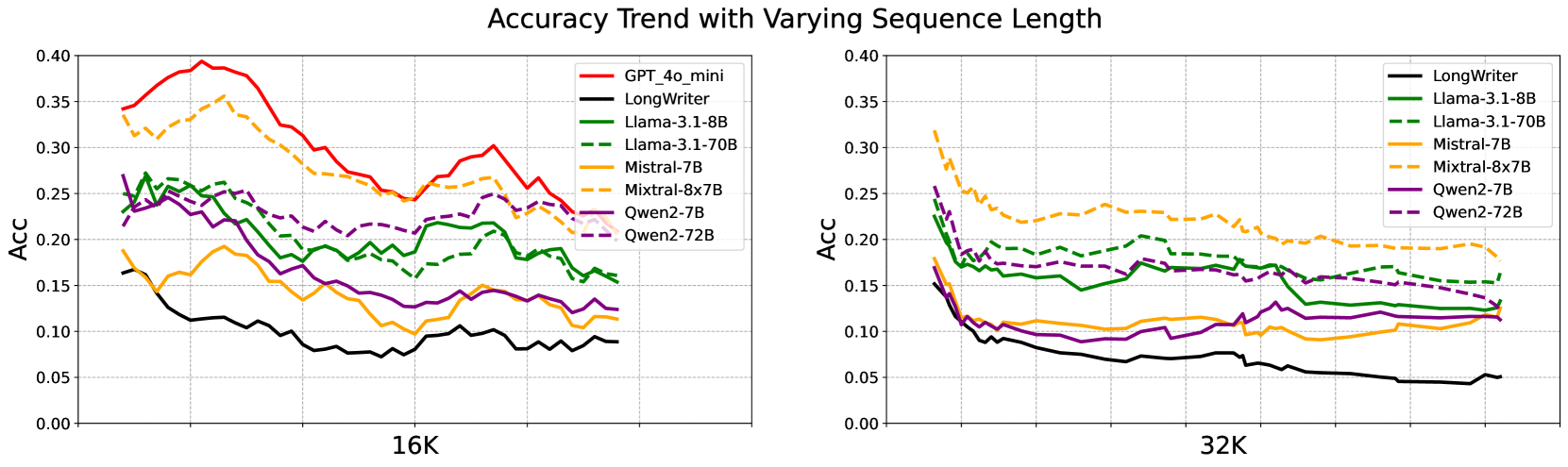
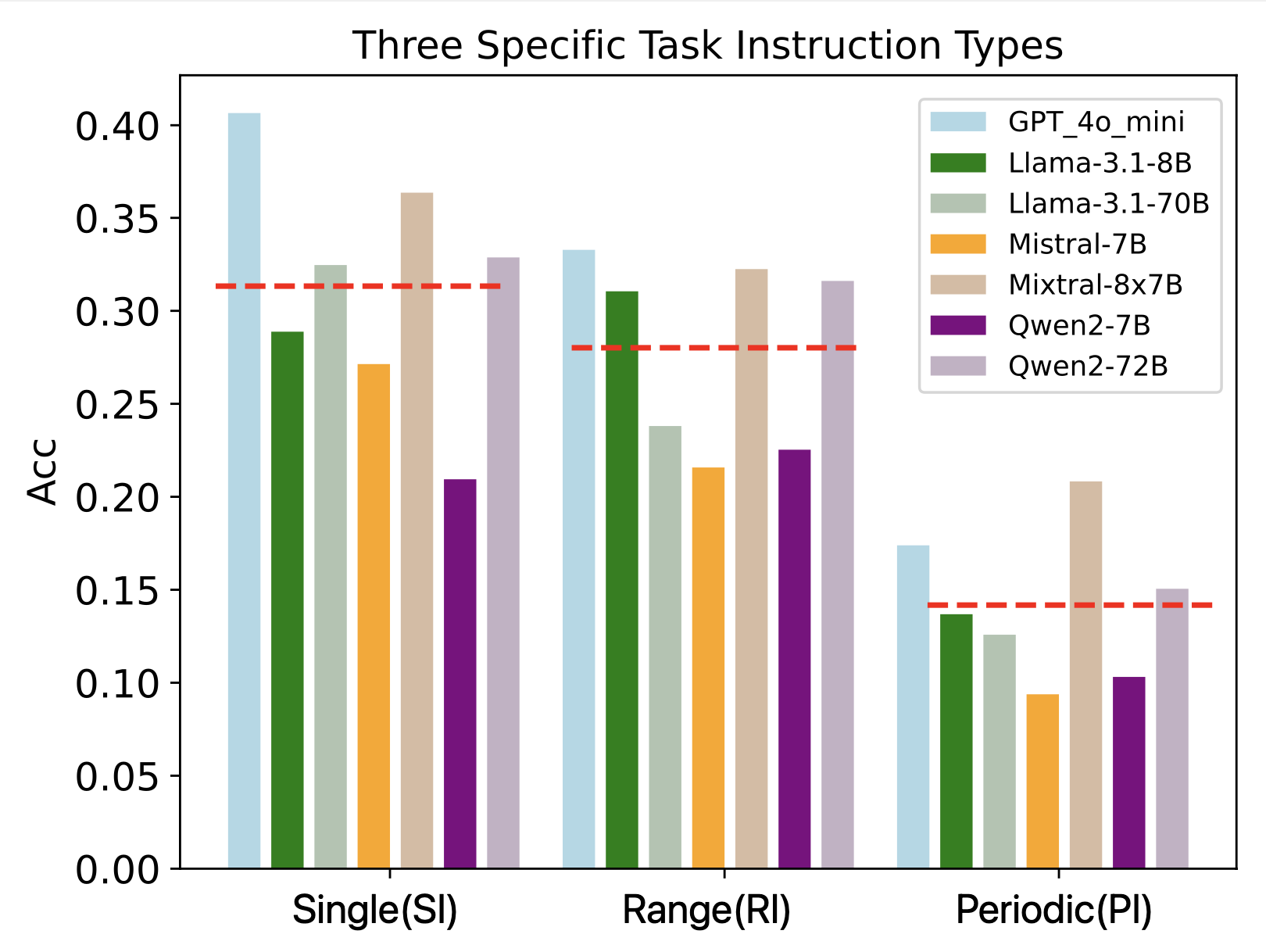
实验结果表明,尽管现有LLM在Ruler等基准上表现良好,但在LongGenBench上的长文本生成方面表现不佳,尤其是在文本长度增加到32K tokens时。这表明现有模型在长文本生成方面仍存在显著不足,需要进一步改进。例如,在某些任务上,模型的事件/约束包含率仅为个位数,远低于预期。
🎯 应用场景
LongGenBench可用于评估和改进大型语言模型在长文本生成方面的能力,从而提升模型在设计方案撰写、技术文档生成、创意写作等领域的应用效果。该基准的推出将促进长文本生成技术的发展,并推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Current benchmarks like Needle-in-a-Haystack (NIAH), Ruler, and Needlebench focus on models' ability to understand long-context input sequences but fail to capture a critical dimension: the generation of high-quality long-form text. Applications such as design proposals, technical documentation, and creative writing rely on coherent, instruction-following outputs over extended sequences - a challenge that existing benchmarks do not adequately address. To fill this gap, we introduce LongGenBench, a novel benchmark designed to rigorously evaluate large language models' (LLMs) ability to generate long text while adhering to complex instructions. Through tasks requiring specific events or constraints within generated text, LongGenBench evaluates model performance across four distinct scenarios, three instruction types, and two generation-lengths (16K and 32K tokens). Our evaluation of ten state-of-the-art LLMs reveals that, despite strong results on Ruler, all models struggled with long text generation on LongGenBench, particularly as text length increased. This suggests that current LLMs are not yet equipped to meet the demands of real-world, long-form text generation.