Interpreting and Improving Large Language Models in Arithmetic Calculation
作者: Wei Zhang, Chaoqun Wan, Yonggang Zhang, Yiu-ming Cheung, Xinmei Tian, Xu Shen, Jieping Ye
分类: cs.CL
发布日期: 2024-09-03
备注: Accepted by ICML 2024 (oral)
💡 一句话要点
揭示大语言模型算术计算机制,选择性微调提升数学能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 算术计算 注意力机制 多层感知器 选择性微调
📋 核心要点
- 现有大语言模型在算术计算中表现出能力,但其内在机制尚不明确,可靠性难以保证。
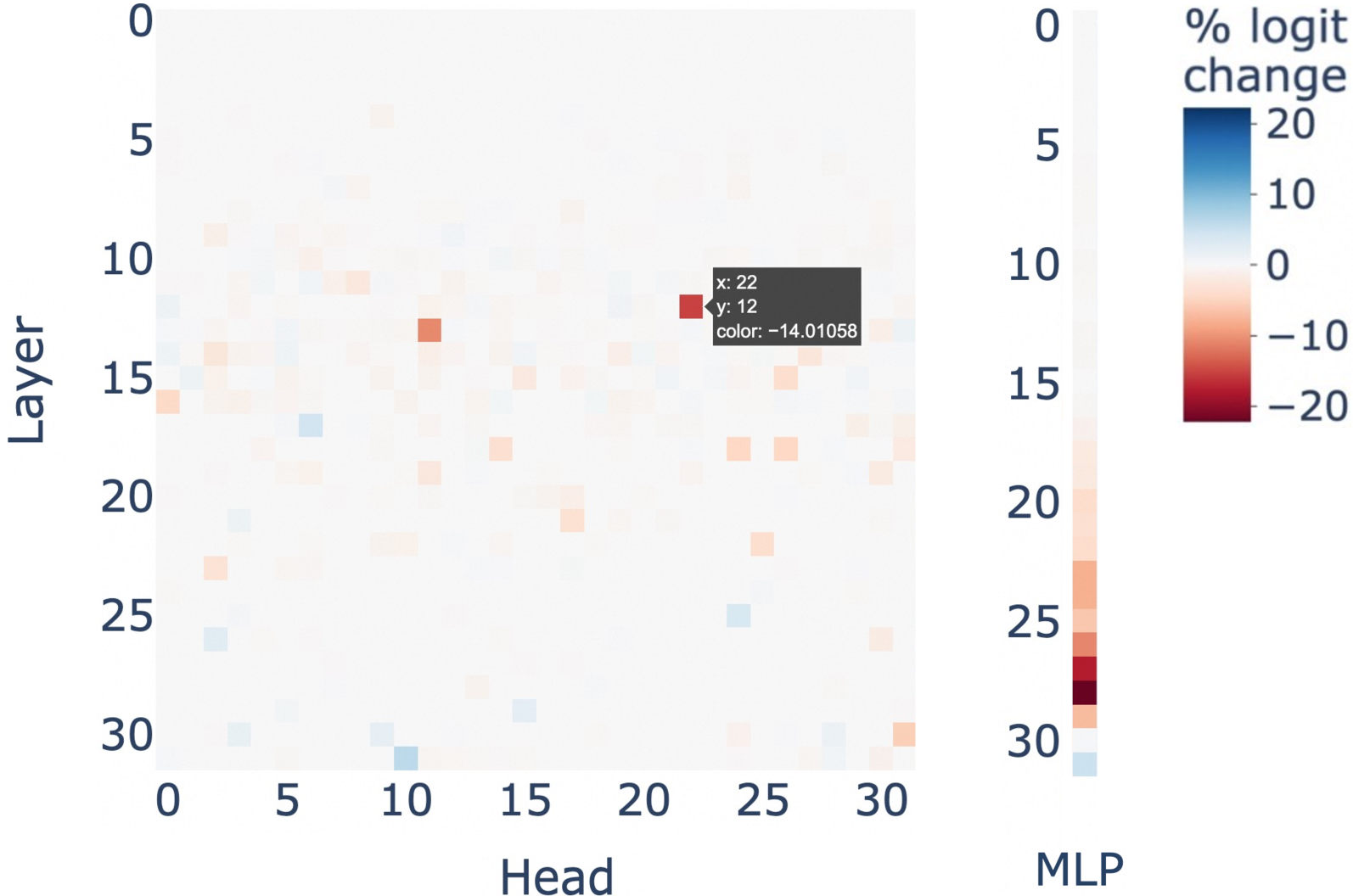
- 通过分析注意力头和MLP的作用,发现少量关键模块在算术计算中起主导作用。
- 选择性微调这些关键模块,能够在提升数学能力的同时,保持非数学任务的性能。
📝 摘要(中文)
大语言模型(LLMs)在众多应用中展现了卓越的潜力,并表现出解决复杂推理任务(如数学计算)的新兴能力。然而,即使对于最简单的算术计算,LLMs背后的内在机制仍然神秘,难以确保可靠性。本文深入研究并揭示LLMs执行计算的一种特定机制。通过全面的实验,我们发现LLMs在计算过程中通常只涉及一小部分(<5%)的注意力头,这些头在关注操作数和运算符方面起着关键作用。随后,来自这些操作数的信息通过多层感知器(MLPs)进行处理,逐步得出最终解。这些关键的头/MLPs虽然是在特定数据集上识别的,但表现出跨不同数据集甚至不同任务的迁移能力。这一发现促使我们研究选择性地微调这些关键头/MLPs以提高LLMs计算性能的潜在好处。经验表明,这种精确的调整可以显著提高数学能力,而不会影响非数学任务的性能。我们的工作是对LLMs内在算术计算能力的初步探索,为揭示更复杂的数学任务奠定了坚实的基础。
🔬 方法详解
问题定义:大语言模型在算术计算中表现出一定的能力,但其内部机制仍然是一个黑盒。现有方法缺乏对LLM如何进行计算的深入理解,导致难以优化和提高其计算能力,并且存在过拟合特定数据集的风险。因此,需要深入理解LLM的计算机制,并找到一种有效的方法来提高其计算能力,同时保持其在其他任务上的性能。
核心思路:论文的核心思路是揭示LLM在算术计算中的关键组成部分,并针对性地进行优化。通过分析注意力头和MLP的激活情况,识别出在计算过程中起主导作用的少量关键模块。然后,通过选择性地微调这些关键模块,提高LLM的计算能力,同时避免对其他任务产生负面影响。这种方法旨在提高LLM的计算效率和泛化能力。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据集准备:使用包含算术计算任务的数据集。2) 模型分析:分析LLM在执行算术计算任务时的注意力头和MLP的激活情况,识别出关键模块。3) 选择性微调:只微调识别出的关键注意力头和MLP,而保持其他模块的参数不变。4) 性能评估:在不同的数据集和任务上评估微调后的LLM的性能,包括算术计算能力和其他任务的性能。
关键创新:该论文的关键创新在于:1) 揭示了LLM在算术计算中的关键组成部分,即少量起主导作用的注意力头和MLP。2) 提出了一种选择性微调方法,只针对关键模块进行优化,从而提高计算能力,同时避免对其他任务产生负面影响。3) 验证了关键模块的迁移能力,即在特定数据集上识别出的关键模块可以在其他数据集和任务上发挥作用。
关键设计:论文的关键设计包括:1) 使用注意力头激活值的统计分析方法来识别关键注意力头。2) 使用类似的方法来识别关键MLP层。3) 设计了一种选择性微调策略,只更新关键注意力头和MLP的参数,而保持其他参数不变。4) 使用了多种数据集和任务来评估微调后的LLM的性能,包括算术计算任务和其他自然语言处理任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,选择性微调关键注意力头和MLP能够显著提升LLM的算术计算能力,同时保持在非数学任务上的性能。具体而言,在数学数据集上的准确率得到了显著提升,并且在GLUE benchmark上没有明显的性能下降,验证了该方法的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于提升大语言模型在科学计算、金融分析等领域的应用能力。通过选择性微调,可以定制化地增强LLM在特定领域的计算能力,同时保持其通用性。未来,该方法有望扩展到更复杂的数学推理任务,并促进LLM在需要精确计算的实际场景中的应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable potential across numerous applications and have shown an emergent ability to tackle complex reasoning tasks, such as mathematical computations. However, even for the simplest arithmetic calculations, the intrinsic mechanisms behind LLMs remain mysterious, making it challenging to ensure reliability. In this work, we delve into uncovering a specific mechanism by which LLMs execute calculations. Through comprehensive experiments, we find that LLMs frequently involve a small fraction (< 5%) of attention heads, which play a pivotal role in focusing on operands and operators during calculation processes. Subsequently, the information from these operands is processed through multi-layer perceptrons (MLPs), progressively leading to the final solution. These pivotal heads/MLPs, though identified on a specific dataset, exhibit transferability across different datasets and even distinct tasks. This insight prompted us to investigate the potential benefits of selectively fine-tuning these essential heads/MLPs to boost the LLMs' computational performance. We empirically find that such precise tuning can yield notable enhancements on mathematical prowess, without compromising the performance on non-mathematical tasks. Our work serves as a preliminary exploration into the arithmetic calculation abilities inherent in LLMs, laying a solid foundation to reveal more intricate mathematical tasks.