AdaComp: Extractive Context Compression with Adaptive Predictor for Retrieval-Augmented Large Language Models
作者: Qianchi Zhang, Hainan Zhang, Liang Pang, Hongwei Zheng, Zhiming Zheng
分类: cs.CL, cs.AI
发布日期: 2024-09-03
备注: 8 pages, 5 figures, code available at https://anonymous.4open.science/r/AdaComp-8C0C/
💡 一句话要点
AdaComp:基于自适应预测器的抽取式上下文压缩,提升检索增强大语言模型效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 上下文压缩 自适应预测 问答系统 信息检索
📋 核心要点
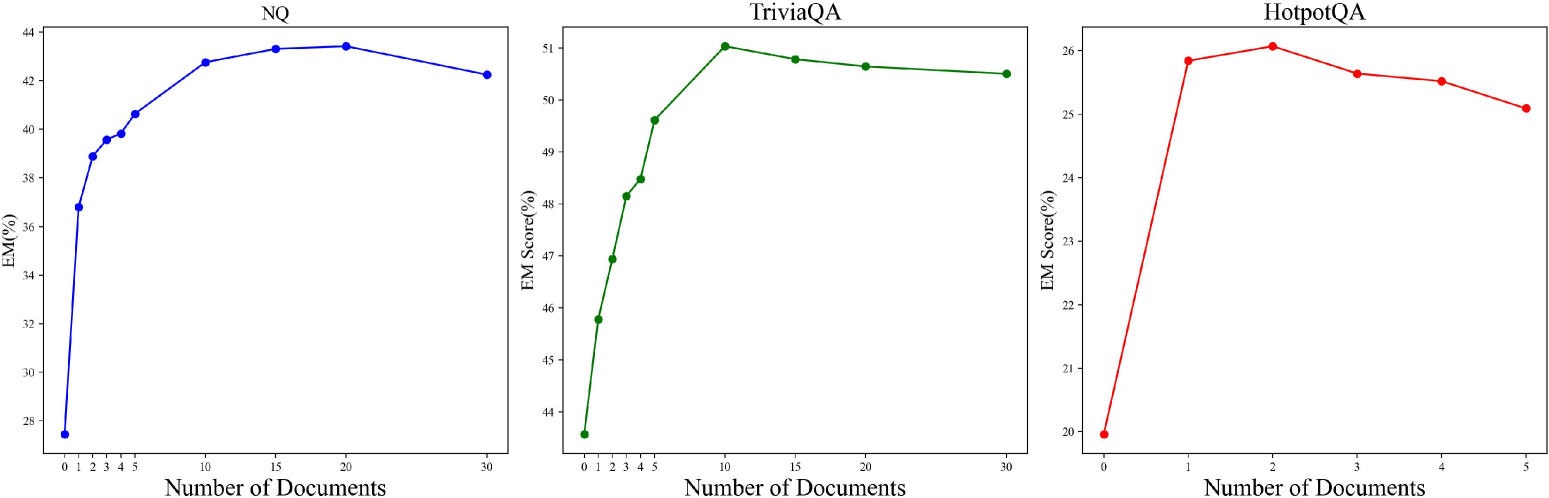
- 现有上下文压缩方法存在过度压缩或计算成本高的问题,难以确定RAG所需的最少文档数量。
- AdaComp通过训练一个压缩率预测器,根据查询复杂度和检索质量自适应地确定压缩率。
- 实验表明,AdaComp在显著降低推理成本的同时,保持了与未压缩模型几乎相同的性能。
📝 摘要(中文)
检索到的文档中包含噪声会阻碍RAG检测答案线索,并使推理过程缓慢且昂贵。因此,上下文压缩对于提高其准确性和效率至关重要。现有的上下文压缩方法使用抽取式或生成式模型来保留最相关的句子,或应用信息瓶颈理论来保留足够的信息。然而,这些方法可能面临过度压缩或高计算成本等问题。我们观察到,检索器通常将相关文档排在最前面,但回答查询所需的文档确切数量是不确定的,这受到查询复杂性和检索质量的影响:复杂查询(如多跳问题)可能需要保留比简单查询更多的文档,而低质量的检索可能需要依赖更多文档才能生成准确的输出。因此,确定所需的最少文档数量(压缩率)仍然是RAG面临的挑战。在本文中,我们介绍了一种低成本的抽取式上下文压缩方法AdaComp,该方法基于查询复杂性和检索质量自适应地确定压缩率。具体来说,我们首先标注RAG系统回答当前查询所需的最少top-k文档作为压缩率,然后构建查询、检索文档及其压缩率的三元组。然后,我们使用这个三元组数据集来训练压缩率预测器。在三个QA数据集和一个会话式多文档QA数据集上的实验表明,AdaComp显著降低了推理成本,同时保持了与未压缩模型几乎相同的性能,实现了效率和性能之间的平衡。
🔬 方法详解
问题定义:现有RAG系统在处理复杂查询或低质量检索结果时,需要依赖大量文档,导致推理效率低下。现有的上下文压缩方法要么过度压缩丢失关键信息,要么计算成本过高,难以在效率和性能之间取得平衡。因此,如何自适应地确定RAG所需的最少文档数量,即压缩率,是一个亟待解决的问题。
核心思路:AdaComp的核心思路是训练一个压缩率预测器,该预测器能够根据查询的复杂度和检索结果的质量,自适应地预测RAG系统回答该查询所需的最少文档数量。通过这种方式,AdaComp可以在保证性能的前提下,最大限度地减少需要处理的文档数量,从而提高推理效率。这种自适应性使得AdaComp能够更好地应对不同类型的查询和检索结果。
技术框架:AdaComp的整体框架包括以下几个主要步骤:1) 数据标注:人工标注RAG系统回答每个查询所需的最少top-k文档作为压缩率。2) 数据集构建:构建包含查询、检索文档和对应压缩率的三元组数据集。3) 压缩率预测器训练:使用三元组数据集训练一个压缩率预测器。4) 上下文压缩:使用训练好的压缩率预测器,根据查询和检索文档自适应地确定压缩率,并抽取相应数量的文档作为上下文。
关键创新:AdaComp的关键创新在于其自适应的压缩率预测机制。与以往的固定压缩率或基于信息瓶颈的压缩方法不同,AdaComp能够根据查询复杂度和检索质量动态地调整压缩率,从而更好地适应不同的场景。此外,AdaComp采用抽取式压缩方法,避免了生成式压缩方法带来的高计算成本。
关键设计:AdaComp的关键设计包括:1) 压缩率预测器的选择:可以使用各种机器学习模型,如线性回归、决策树或神经网络,来构建压缩率预测器。2) 特征工程:需要提取能够反映查询复杂度和检索质量的特征,例如查询的长度、检索结果的相似度得分等。3) 损失函数:可以使用均方误差等回归损失函数来训练压缩率预测器。4) Top-k文档标注:标注过程需要保证标注的top-k文档包含回答问题所需的所有信息,避免过度压缩。
🖼️ 关键图片


📊 实验亮点
在三个QA数据集和一个会话式多文档QA数据集上的实验表明,AdaComp在显著降低推理成本的同时,保持了与未压缩模型几乎相同的性能。具体来说,AdaComp能够在保证性能几乎不变的情况下,显著减少需要处理的文档数量,从而提高推理效率。这表明AdaComp在效率和性能之间取得了良好的平衡。
🎯 应用场景
AdaComp可应用于各种需要RAG的场景,例如问答系统、对话系统、信息检索等。通过自适应地压缩上下文,AdaComp可以显著降低推理成本,提高系统的响应速度和效率。尤其是在处理大规模文档或复杂查询时,AdaComp的优势更加明显。未来,AdaComp可以进一步扩展到其他类型的上下文压缩任务,例如代码压缩、知识图谱压缩等。
📄 摘要(原文)
Retrieved documents containing noise will hinder RAG from detecting answer clues and make the inference process slow and expensive. Therefore, context compression is necessary to enhance its accuracy and efficiency. Existing context compression methods use extractive or generative models to retain the most query-relevant sentences or apply the information bottleneck theory to preserve sufficient information. However, these methods may face issues such as over-compression or high computational costs. We observe that the retriever often ranks relevant documents at the top, but the exact number of documents needed to answer the query is uncertain due to the impact of query complexity and retrieval quality: complex queries like multi-hop questions may require retaining more documents than simpler queries, and a low-quality retrieval may need to rely on more documents to generate accurate outputs. Therefore, determining the minimum number of required documents (compression rate) is still a challenge for RAG. In this paper, we introduce AdaComp, a low-cost extractive context compression method that adaptively determines the compression rate based on both query complexity and retrieval quality. Specifically, we first annotate the minimum top-k documents necessary for the RAG system to answer the current query as the compression rate and then construct triplets of the query, retrieved documents, and its compression rate. Then, we use this triplet dataset to train a compression-rate predictor. Experiments on three QA datasets and one conversational Muiti-doc QA dataset show that AdaComp significantly reduces inference costs while maintaining performance nearly identical to uncompressed models, achieving a balance between efficiency and performance.