An Implementation of Werewolf Agent That does not Truly Trust LLMs
作者: Takehiro Sato, Shintaro Ozaki, Daisaku Yokoyama
分类: cs.CL
发布日期: 2024-09-03
💡 一句话要点
提出结合LLM与规则的狼人杀Agent,提升对话一致性与逻辑性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 狼人杀Agent 大型语言模型 规则算法 对话系统 角色扮演
📋 核心要点
- 狼人杀Agent面临理解情境和生成个性化发言的挑战,现有方法难以兼顾逻辑性和角色扮演。
- 该Agent融合LLM和规则算法,利用LLM分析对话历史,并根据分析结果选择LLM生成或预设模板。
- 实验表明,该Agent能有效缓解对话不一致性,提升逻辑性,并在定性评估中更具人性化。
📝 摘要(中文)
本文提出了一种狼人杀游戏Agent,旨在解决现有计算机Agent在理解情境和表达个性化言语方面的挑战。该Agent结合了大型语言模型(LLM)和基于规则的算法。具体而言,Agent利用LLM分析对话历史,并根据分析结果,选择LLM生成的输出或预先准备的模板。这种方法使得Agent能够在特定情况下反驳,识别何时结束对话,并展现角色个性。实验结果表明,该方法缓解了对话不一致性,并促进了逻辑性发言。定性评估表明,与未经修改的LLM相比,该Agent更具人性化。该Agent已开源,旨在促进狼人杀游戏领域的研究。
🔬 方法详解
问题定义:狼人杀游戏是一种非完全信息博弈,计算机Agent难以理解复杂情境,并生成具有角色特征和逻辑一致性的发言。现有方法难以在逻辑推理和角色扮演之间取得平衡,容易出现对话不一致和不符合游戏规则的情况。
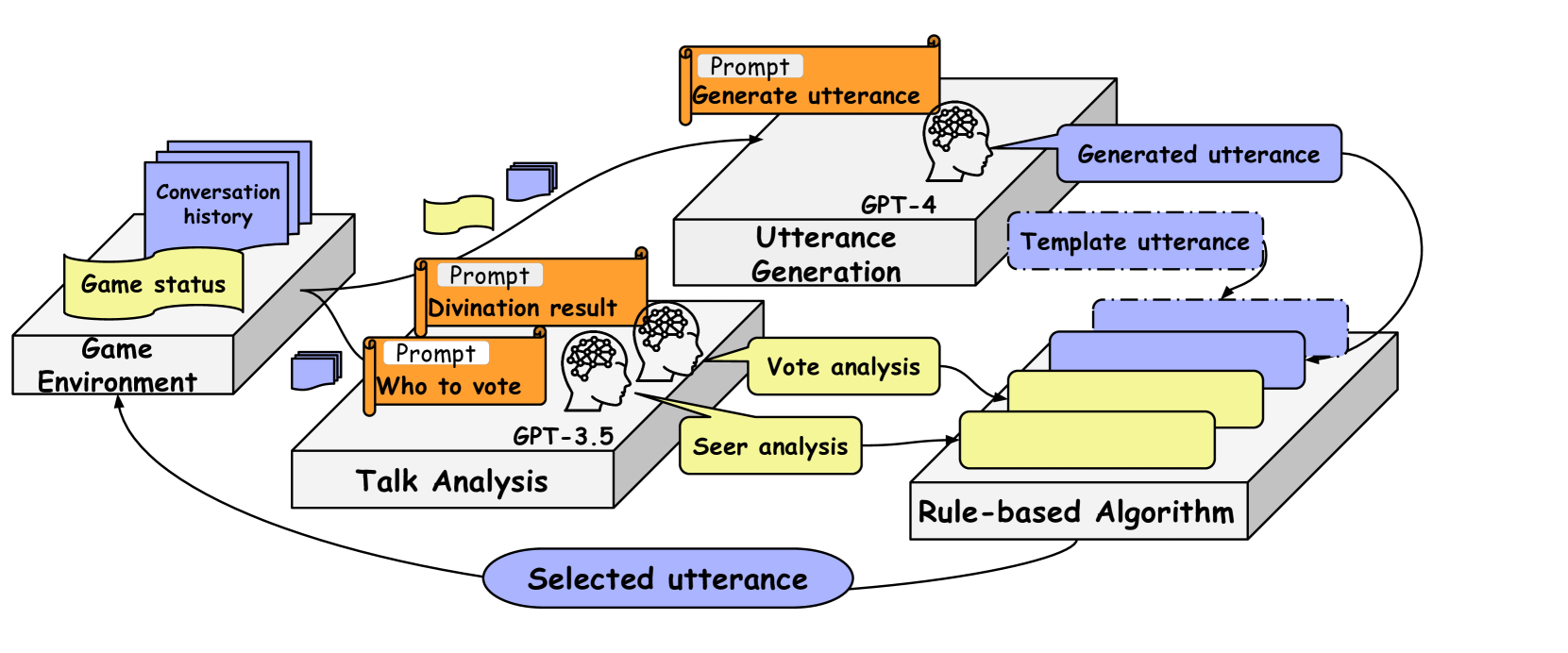
核心思路:论文的核心思路是结合LLM的生成能力和规则算法的逻辑约束,设计一种混合Agent。该Agent利用LLM理解对话历史,并根据LLM的分析结果,决定是使用LLM生成的自然语言回复,还是使用预先定义的模板回复。这样既能利用LLM生成多样化的发言,又能保证发言的逻辑性和符合角色设定。
技术框架:该Agent的技术框架主要包含两个模块:LLM分析模块和规则选择模块。LLM分析模块负责分析对话历史,提取关键信息,例如发言者的身份、发言内容、发言者的意图等。规则选择模块根据LLM的分析结果,选择合适的回复方式。如果LLM分析结果表明当前情境需要进行逻辑推理或反驳,则选择预先定义的模板回复;否则,选择LLM生成的自然语言回复。
关键创新:该论文的关键创新在于将LLM和规则算法相结合,实现了一种既具有生成能力又具有逻辑约束的狼人杀Agent。与完全依赖LLM的Agent相比,该Agent能够更好地保证对话的一致性和逻辑性;与完全依赖规则算法的Agent相比,该Agent能够生成更加多样化和个性化的发言。
关键设计:具体的技术细节包括:(1) 使用特定的prompt工程来指导LLM进行对话历史分析,例如要求LLM提取发言者的身份、发言内容和意图;(2) 设计了一系列规则,用于判断当前情境是否需要进行逻辑推理或反驳,例如判断是否存在矛盾的发言或不符合游戏规则的行为;(3) 预先定义了一系列模板回复,用于在需要进行逻辑推理或反驳时使用,例如用于指出发言者的逻辑错误或反驳发言者的观点。
🖼️ 关键图片


📊 实验亮点
定性评估结果表明,与未经修改的LLM相比,该Agent更具人性化。这意味着该Agent在角色扮演和对话流畅性方面取得了显著提升。虽然论文中没有提供具体的性能数据,但定性评估结果表明该方法是有效的。
🎯 应用场景
该研究成果可应用于开发更智能、更具人性的游戏Agent,提升玩家的游戏体验。此外,该方法也可推广到其他需要逻辑推理和角色扮演的对话场景,例如客户服务、教育辅导等,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Werewolf is an incomplete information game, which has several challenges when creating a computer agent as a player given the lack of understanding of the situation and individuality of utterance (e.g., computer agents are not capable of characterful utterance or situational lying). We propose a werewolf agent that solves some of those difficulties by combining a Large Language Model (LLM) and a rule-based algorithm. In particular, our agent uses a rule-based algorithm to select an output either from an LLM or a template prepared beforehand based on the results of analyzing conversation history using an LLM. It allows the agent to refute in specific situations, identify when to end the conversation, and behave with persona. This approach mitigated conversational inconsistencies and facilitated logical utterance as a result. We also conducted a qualitative evaluation, which resulted in our agent being perceived as more human-like compared to an unmodified LLM. The agent is freely available for contributing to advance the research in the field of Werewolf game.