Benchmarking Cognitive Domains for LLMs: Insights from Taiwanese Hakka Culture
作者: Chen-Chi Chang, Ching-Yuan Chen, Hung-Shin Lee, Chih-Cheng Lee
分类: cs.CL, cs.AI
发布日期: 2024-09-03 (更新: 2024-09-25)
备注: Accepted to O-COCOSDA 2024
💡 一句话要点
构建客家文化认知基准,评估大型语言模型在文化理解和处理中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文化知识 客家文化 布鲁姆分类法 检索增强生成 认知评估 少数民族文化
📋 核心要点
- 现有LLM在处理特定文化知识,尤其是少数民族文化知识时,面临知识表示和理解的挑战。
- 论文提出基于布鲁姆分类法的多维评估框架,并结合检索增强生成(RAG)技术,提升LLM对客家文化的理解和应用能力。
- 实验结果表明,RAG技术能有效提高LLM在各认知领域的准确性,但在创造性任务上仍有提升空间。
📝 摘要(中文)
本研究提出了一套综合基准,旨在评估大型语言模型(LLM)在理解和处理文化知识方面的性能,并以客家文化作为案例研究。该研究利用布鲁姆分类法,开发了一个多维框架,系统地评估LLM在六个认知领域的能力:记忆、理解、应用、分析、评估和创造。该基准超越了传统的单维评估,通过对LLM处理文化特定内容的能力进行更深入的分析,涵盖了从基本事实回忆到更高阶的认知任务(如创造性综合)。此外,该研究集成了检索增强生成(RAG)技术,以应对LLM中少数民族文化知识表示的挑战,展示了RAG如何通过动态地整合相关的外部信息来提高模型的性能。结果表明,RAG在提高所有认知领域的准确性方面是有效的,尤其是在需要精确检索和应用文化知识的任务中。然而,研究结果也揭示了RAG在创造性任务中的局限性,强调了进一步优化的必要性。该基准为评估和比较文化多样性背景下的LLM提供了一个强大的工具,为人工智能驱动的文化知识保存和传播的未来研究和发展提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在理解和处理特定文化知识,特别是少数民族文化知识时所面临的挑战。现有方法在处理此类知识时,往往存在知识覆盖不足、理解偏差以及难以进行高阶认知推理等问题。这限制了LLM在文化传承、文化交流等领域的应用潜力。
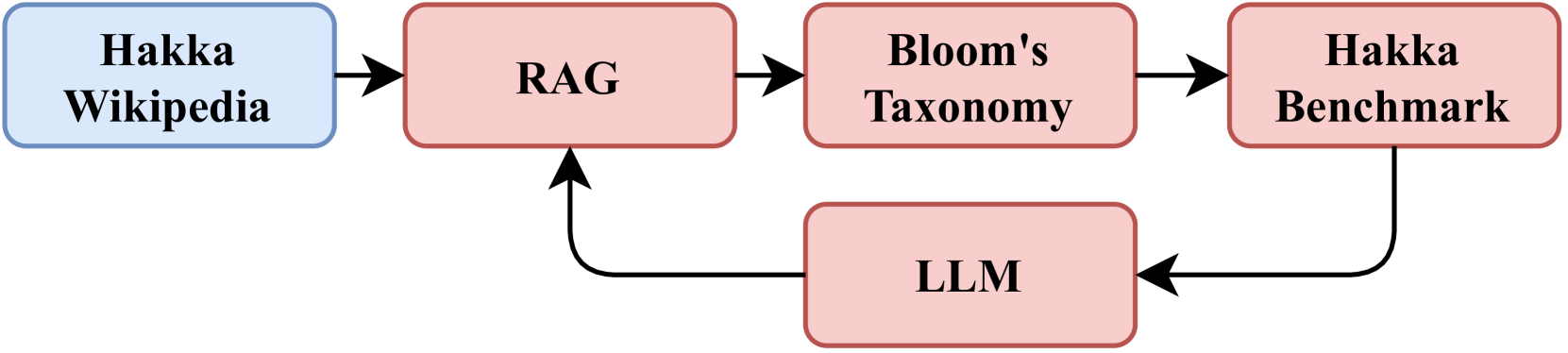
核心思路:论文的核心思路是构建一个多维的评估基准,并结合检索增强生成(RAG)技术来提升LLM对特定文化知识的理解和应用能力。通过布鲁姆分类法,将认知过程分解为记忆、理解、应用、分析、评估和创造六个维度,从而更全面地评估LLM的认知能力。RAG技术则通过动态地检索外部知识,弥补LLM自身知识库的不足。
技术框架:整体框架包含两个主要部分:一是基于布鲁姆分类法的多维评估基准构建,二是RAG技术的集成。评估基准用于系统地评估LLM在六个认知领域的能力。RAG技术则包含知识检索模块和生成模块。知识检索模块负责从外部知识库中检索与输入问题相关的知识,生成模块则利用检索到的知识来生成答案。
关键创新:论文的关键创新在于将布鲁姆分类法应用于LLM的文化知识评估,并结合RAG技术来提升LLM的文化理解能力。与传统的单维评估方法相比,该方法能够更全面地评估LLM的认知能力。RAG技术的引入则有效弥补了LLM自身知识库的不足,提高了LLM在处理特定文化知识时的准确性和可靠性。
关键设计:在RAG技术中,关键设计包括知识检索策略和生成模型的选择。知识检索策略需要能够准确地检索到与输入问题相关的知识。生成模型的选择则需要考虑其生成能力和对文化知识的理解能力。论文中可能使用了特定的相似度计算方法进行知识检索,并选择了具有较强生成能力的LLM作为生成模型。具体的参数设置和损失函数等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RAG技术能够显著提高LLM在所有认知领域的准确性,尤其是在需要精确检索和应用文化知识的任务中。具体性能提升数据(例如,准确率提升百分比)和对比基线(例如,未使用RAG的LLM性能)需要在论文中查找(未知)。研究还发现,RAG在创造性任务中的提升相对有限,表明需要进一步优化。
🎯 应用场景
该研究成果可应用于文化知识保护与传播、智能文化旅游、文化教育等领域。通过提升LLM对特定文化知识的理解和应用能力,可以更好地传承和推广优秀传统文化,促进不同文化之间的交流与理解。未来,该研究可以扩展到其他文化领域,为构建更加多元和包容的人工智能系统提供支持。
📄 摘要(原文)
This study introduces a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in understanding and processing cultural knowledge, with a specific focus on Hakka culture as a case study. Leveraging Bloom's Taxonomy, the study develops a multi-dimensional framework that systematically assesses LLMs across six cognitive domains: Remembering, Understanding, Applying, Analyzing, Evaluating, and Creating. This benchmark extends beyond traditional single-dimensional evaluations by providing a deeper analysis of LLMs' abilities to handle culturally specific content, ranging from basic recall of facts to higher-order cognitive tasks such as creative synthesis. Additionally, the study integrates Retrieval-Augmented Generation (RAG) technology to address the challenges of minority cultural knowledge representation in LLMs, demonstrating how RAG enhances the models' performance by dynamically incorporating relevant external information. The results highlight the effectiveness of RAG in improving accuracy across all cognitive domains, particularly in tasks requiring precise retrieval and application of cultural knowledge. However, the findings also reveal the limitations of RAG in creative tasks, underscoring the need for further optimization. This benchmark provides a robust tool for evaluating and comparing LLMs in culturally diverse contexts, offering valuable insights for future research and development in AI-driven cultural knowledge preservation and dissemination.