DataSculpt: Crafting Data Landscapes for Long-Context LLMs through Multi-Objective Partitioning
作者: Keer Lu, Xiaonan Nie, Zheng Liang, Da Pan, Shusen Zhang, Keshi Zhao, Weipeng Chen, Zenan Zhou, Guosheng Dong, Bin Cui, Wentao Zhang
分类: cs.CL
发布日期: 2024-09-02 (更新: 2024-10-02)
💡 一句话要点
DataSculpt:通过多目标划分构建长文本LLM的数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 数据管理 多目标优化 上下文窗口 数据组织 语义相似性 贪婪搜索
📋 核心要点
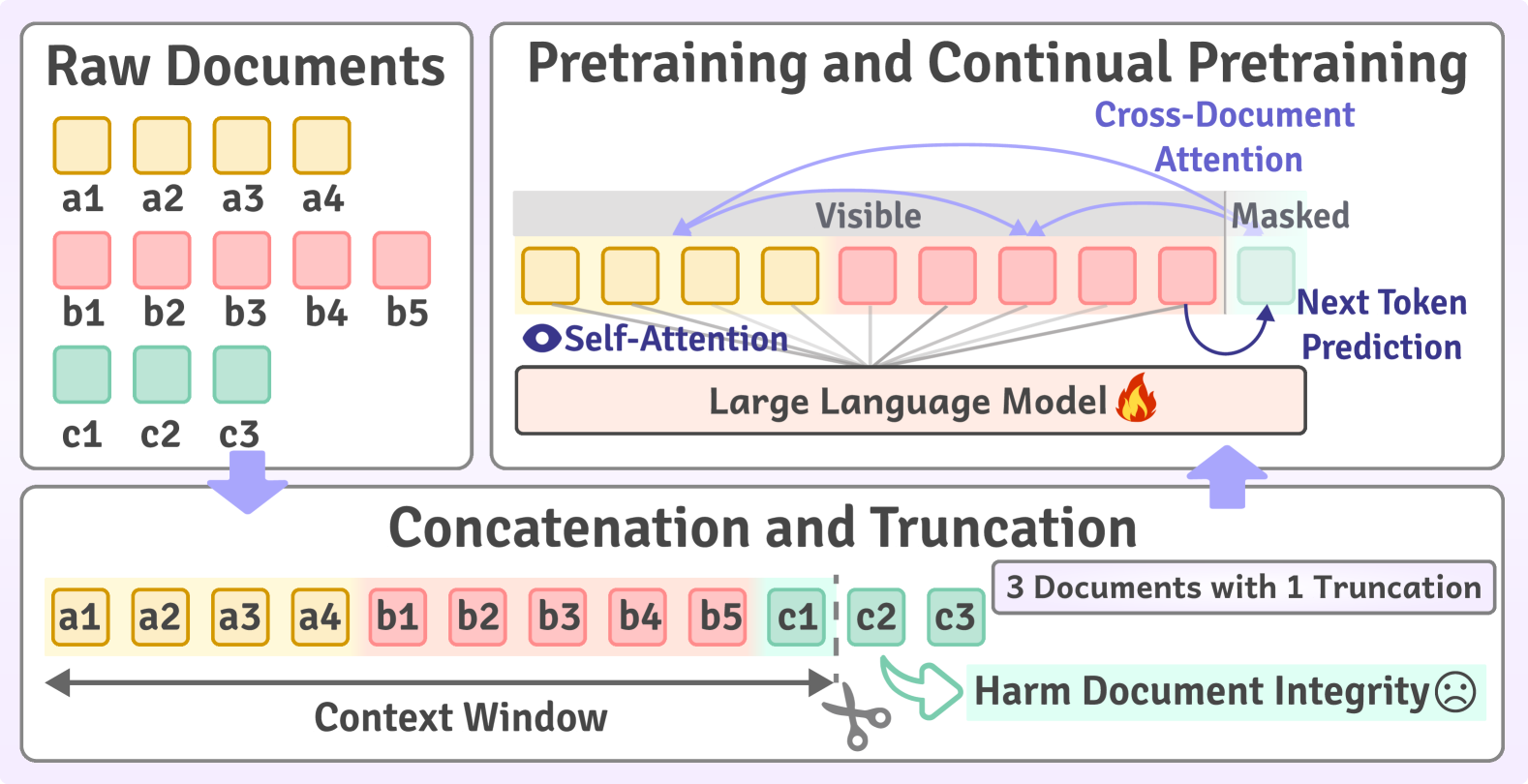
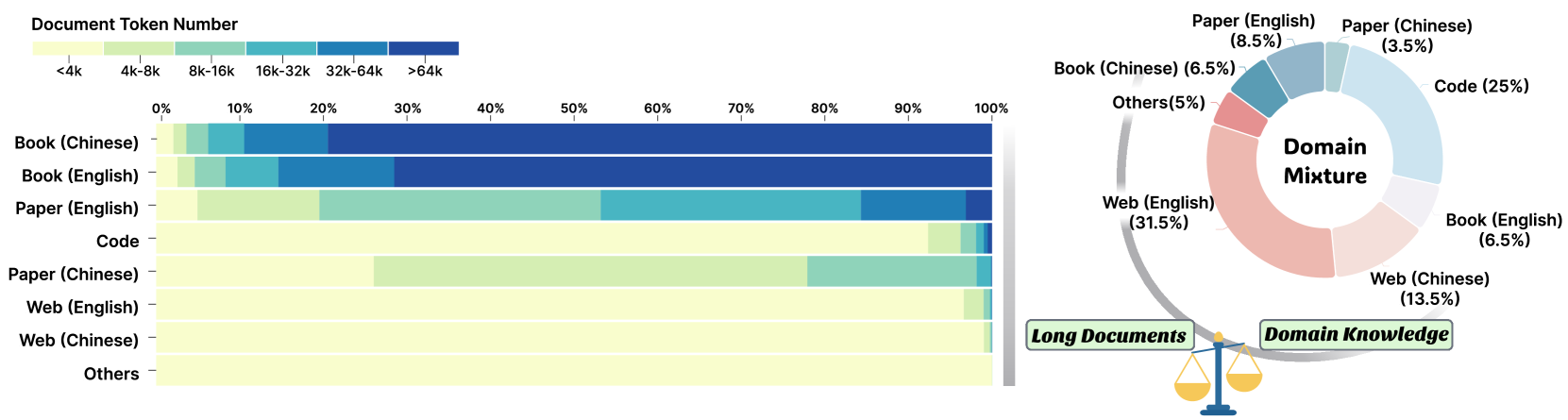
- 现有长文本LLM训练面临多领域长文档稀缺、上下文窗口构建困难、大规模数据组织低效等挑战。
- DataSculpt将数据组织形式化为多目标组合优化问题,兼顾相关性、同质性、完整性和效率。
- 实验表明,DataSculpt在检索增强、摘要、阅读理解和代码完成等任务上均有显著提升。
📝 摘要(中文)
近年来,大型语言模型(LLMs)在各种任务中都表现出显著的改进,其中之一就是长文本处理能力。提高长文本性能的关键在于有效的数据组织和管理策略,这些策略整合来自多个领域的数据,并在训练期间优化上下文窗口。通过广泛的实验分析,我们确定了在设计有效的数据管理策略时面临的三个关键挑战,这些策略使模型能够在不牺牲其他任务性能的情况下实现长文本能力:(1)跨多个领域的长文档短缺,(2)上下文窗口的有效构建,以及(3)大规模数据集的有效组织。为了应对这些挑战,我们引入了DataSculpt,这是一个为长文本训练而设计的新型数据管理框架。我们首先将训练数据的组织形式化为一个多目标组合优化问题,重点关注相关性、同质性、完整性和效率等属性。具体来说,我们的方法采用了一种由粗到精的方法来高效且有效地优化训练数据组织。我们首先基于语义相似性对数据进行聚类(粗略),然后对每个聚类中的文档进行多目标贪婪搜索,以对文档进行评分并将其连接到各种上下文窗口中(精细)。我们的综合评估表明,DataSculpt显著提高了长文本训练性能,从而在检索增强方面提高了18.09%,在摘要方面提高了21.23%,在阅读理解方面提高了21.27%,在代码完成方面提高了3.81%,同时通过提高4.88%的整体模型熟练度来保持整体模型能力。
🔬 方法详解
问题定义:当前长文本LLM训练面临数据组织上的挑战,具体表现为:缺乏跨领域长文档,难以有效构建上下文窗口,以及大规模数据集组织效率低下。这些问题限制了模型长文本处理能力的提升,并且可能影响模型在其他任务上的表现。
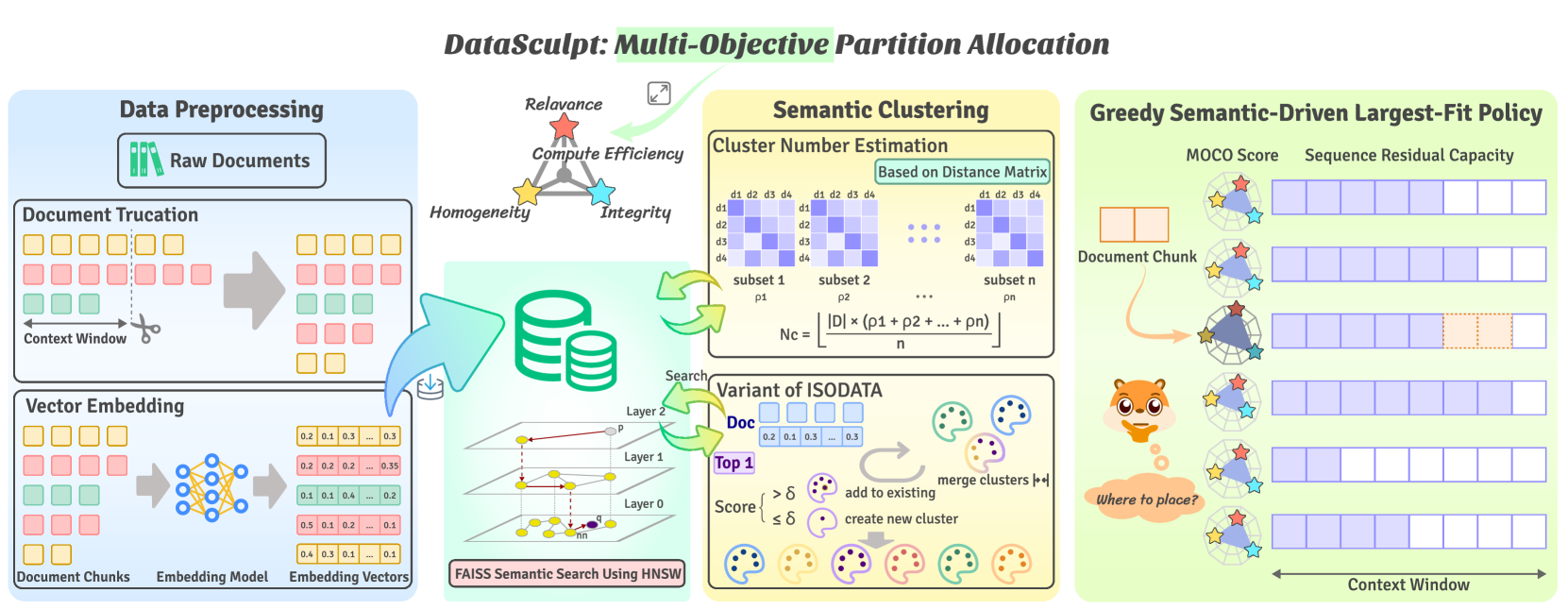
核心思路:DataSculpt的核心思路是将训练数据的组织过程视为一个多目标组合优化问题。通过优化数据组织方式,使得模型能够更有效地学习长文本信息,从而提升长文本处理能力。这种方法旨在平衡不同目标(如相关性、同质性、完整性和效率),以获得最佳的训练效果。
技术框架:DataSculpt采用粗到精的方法进行数据组织。首先,基于语义相似性对数据进行聚类(粗略阶段),将相似的文档归为一类。然后,在每个聚类内部,采用多目标贪婪搜索算法,对文档进行评分并连接成不同的上下文窗口(精细阶段)。这个过程旨在找到最优的文档组合方式,以最大化模型的学习效果。
关键创新:DataSculpt的关键创新在于将数据组织问题形式化为多目标优化问题,并采用粗到精的方法进行求解。与传统的数据组织方法相比,DataSculpt能够更全面地考虑各种因素,并找到更优的数据组织方案。此外,DataSculpt的多目标贪婪搜索算法能够有效地处理大规模数据集,并找到接近最优解的方案。
关键设计:DataSculpt的关键设计包括:1) 语义相似性聚类算法的选择,用于将相似的文档归为一类;2) 多目标贪婪搜索算法的设计,用于在每个聚类内部找到最优的文档组合方式;3) 目标函数的定义,用于衡量不同数据组织方案的优劣。目标函数需要综合考虑相关性、同质性、完整性和效率等因素。具体的参数设置和损失函数选择可能需要根据具体的数据集和任务进行调整。
🖼️ 关键图片
📊 实验亮点
DataSculpt在多个长文本处理任务上取得了显著的性能提升。具体来说,在检索增强方面提高了18.09%,在摘要方面提高了21.23%,在阅读理解方面提高了21.27%,在代码完成方面提高了3.81%。同时,DataSculpt还保持了整体模型熟练度,提升了4.88%。这些结果表明,DataSculpt能够有效地提升LLM的长文本处理能力。
🎯 应用场景
DataSculpt可应用于各种需要长文本处理能力的场景,例如:长文档摘要、信息检索、阅读理解、代码生成等。该研究成果有助于提升LLM在这些领域的性能,具有重要的实际应用价值。未来,DataSculpt可以进一步扩展到其他类型的数据,例如图像、音频等,以支持更多模态的长上下文学习。
📄 摘要(原文)
In recent years, Large Language Models (LLMs) have demonstrated significant improvements across a variety of tasks, one of which is the long-context capability. The key to improving long-context performance lies in effective data organization and management strategies that integrate data from multiple domains and optimize the context window during training. Through extensive experimental analysis, we identified three key challenges in designing effective data management strategies that enable the model to achieve long-context capability without sacrificing performance in other tasks: (1) a shortage of long documents across multiple domains, (2) effective construction of context windows, and (3) efficient organization of large-scale datasets. To address these challenges, we introduce DataSculpt, a novel data management framework designed for long-context training. We first formulate the organization of training data as a multi-objective combinatorial optimization problem, focusing on attributes including relevance, homogeneity, integrity, and efficiency. Specifically, our approach utilizes a coarse-to-fine methodology to optimize training data organization both efficiently and effectively. We begin by clustering the data based on semantic similarity (coarse), followed by a multi-objective greedy search within each cluster to score and concatenate documents into various context windows (fine). Our comprehensive evaluations demonstrate that DataSculpt significantly enhances long-context training performance, resulting in improvements of 18.09% in retrieval augmentation, 21.23% in summarization, 21.27% in reading comprehension, and a 3.81% increase in code completion, while also maintaining overall model proficiency with a 4.88% improvement.