Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
作者: Fuqiang Niu, Zebang Cheng, Xianghua Fu, Xiaojiang Peng, Genan Dai, Yin Chen, Hu Huang, Bowen Zhang
分类: cs.MM, cs.CL
发布日期: 2024-09-01
备注: ACM MM2024
💡 一句话要点
提出MmMtCSD数据集与MLLM-SD框架,解决多模态多轮对话场景下的立场检测问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 立场检测 对话系统 社交媒体分析 大型语言模型
📋 核心要点
- 现有MSD研究忽略了社交媒体中自然存在的多方对话语境,缺乏真实捕捉对话场景的数据集。
- 提出MLLM-SD框架,通过多模态大型语言模型学习文本和视觉模态的联合立场表示。
- 在MmMtCSD数据集上的实验表明,MLLM-SD方法在多模态立场检测方面取得了最先进的性能。
📝 摘要(中文)
立场检测旨在利用社交媒体数据识别公众对特定目标的观点,这是一项重要但具有挑战性的任务。随着包含文本和图像等多种模态的社交媒体内容的激增,多模态立场检测(MSD)已成为一个关键的研究领域。然而,现有的MSD研究主要集中在对单个文本-图像对中的立场进行建模,忽略了社交媒体上自然发生的多方对话语境。这种局限性源于缺乏能够真实捕捉此类对话场景的数据集,阻碍了会话MSD的进展。为了解决这个问题,我们引入了一个新的多模态多轮会话立场检测数据集(称为MmMtCSD)。为了从这个具有挑战性的数据集中推导出立场,我们提出了一个新颖的多模态大型语言模型立场检测框架(MLLM-SD),该框架学习来自文本和视觉模态的联合立场表示。在MmMtCSD上的实验表明,我们提出的MLLM-SD方法在多模态立场检测方面表现出最先进的性能。我们相信MmMtCSD将有助于推进立场检测研究的实际应用。
🔬 方法详解
问题定义:论文旨在解决多模态多轮对话场景下的立场检测问题。现有方法主要关注单个文本-图像对的立场建模,忽略了对话上下文,导致在实际社交媒体场景中表现不佳。缺乏能够真实反映多轮对话的数据集也是一个关键痛点。
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)同时处理文本和图像信息,并结合对话历史进行立场判断。通过联合学习文本和视觉模态的表示,模型能够更好地理解上下文信息,从而更准确地检测立场。
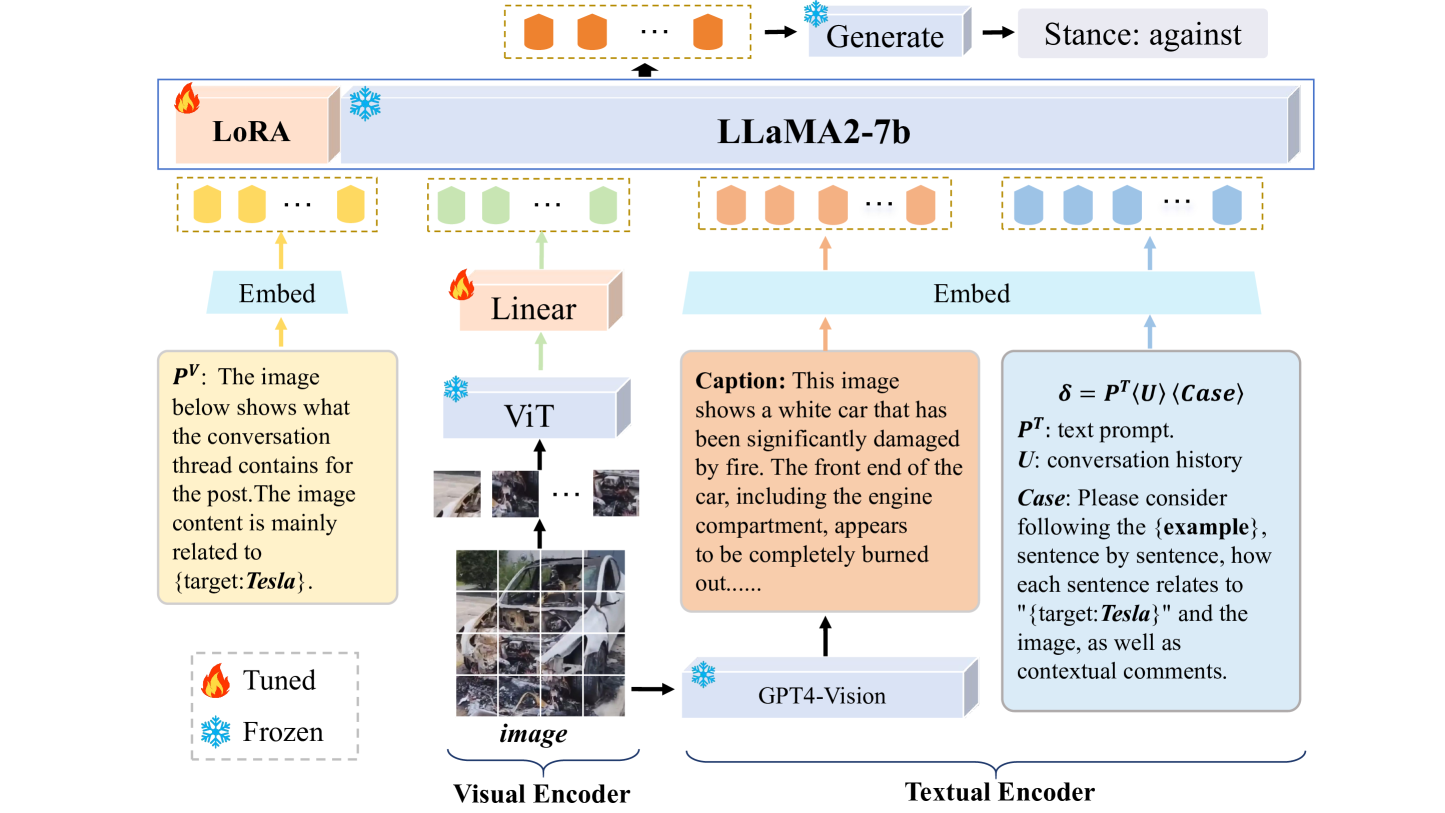
技术框架:MLLM-SD框架主要包含以下几个模块:1) 多模态输入编码器:用于提取文本和图像的特征表示。2) 对话历史编码器:用于编码多轮对话的历史信息。3) 融合模块:将文本、图像和对话历史的特征进行融合。4) 立场分类器:根据融合后的特征预测立场。整体流程是,首先使用多模态输入编码器提取文本和图像特征,然后使用对话历史编码器编码对话历史,接着使用融合模块将所有特征融合,最后使用立场分类器预测立场。
关键创新:论文的关键创新在于提出了一个专门针对多模态多轮对话场景的立场检测框架MLLM-SD,并构建了一个新的数据集MmMtCSD。MLLM-SD框架能够有效地利用多模态信息和对话历史,从而提高立场检测的准确性。与现有方法相比,MLLM-SD更关注对话上下文,更贴近实际应用场景。
关键设计:论文中关于参数设置、损失函数和网络结构的具体技术细节未详细描述,属于未知信息。但可以推测,损失函数可能包含交叉熵损失,用于优化立场分类器。网络结构可能采用了Transformer架构,用于编码文本和对话历史。
🖼️ 关键图片

📊 实验亮点
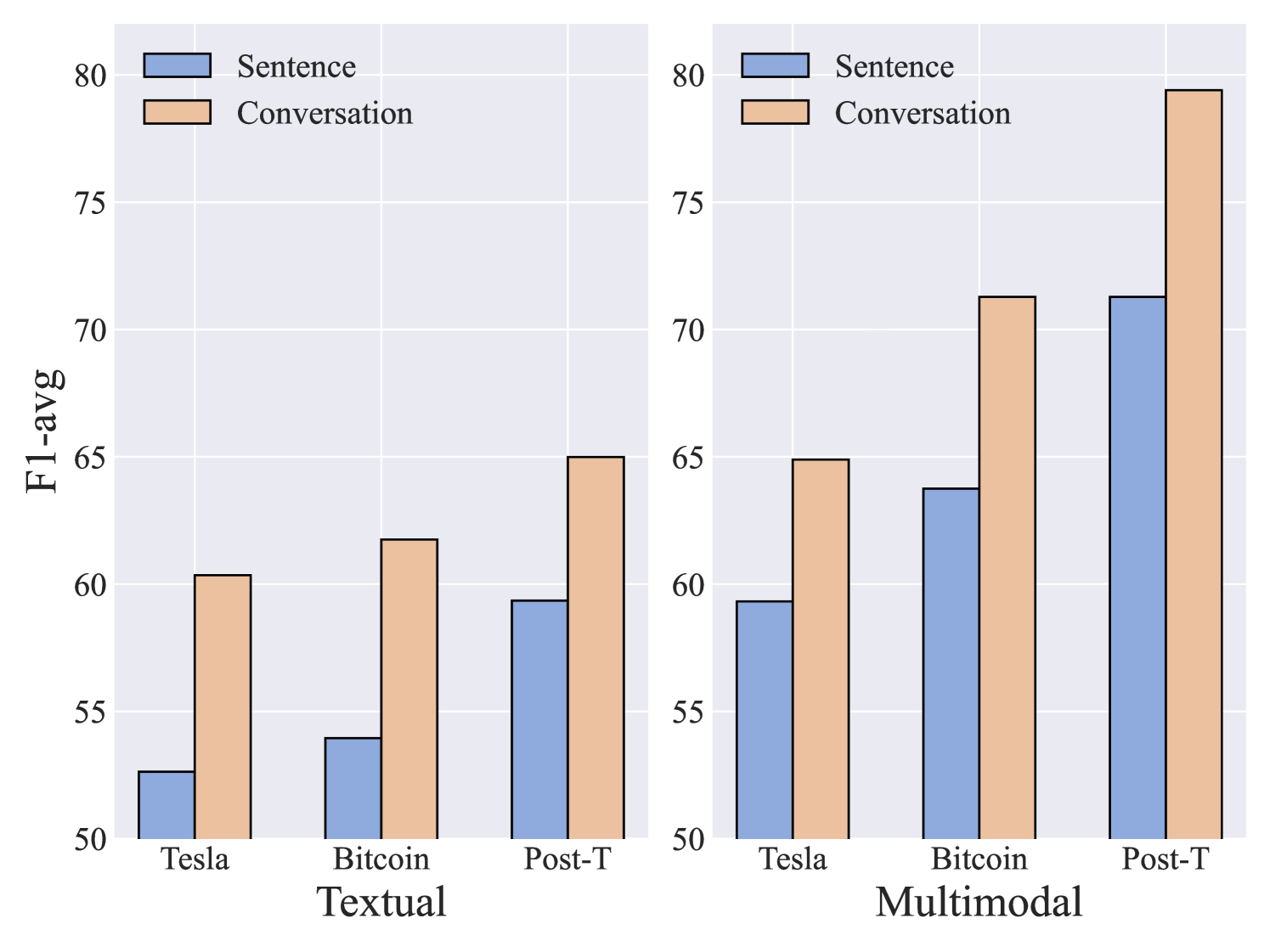
论文提出了MmMtCSD数据集,填补了多模态多轮对话立场检测数据集的空白。实验结果表明,提出的MLLM-SD框架在MmMtCSD数据集上取得了state-of-the-art的性能,证明了该方法的有效性。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于舆情监控、社交媒体分析、虚假信息检测等领域。通过自动检测用户在对话中的立场,可以帮助政府、企业和个人更好地了解公众舆论,及时发现和应对潜在的风险。此外,该技术还可以用于个性化推荐、智能客服等应用场景,提升用户体验。
📄 摘要(原文)
Stance detection, which aims to identify public opinion towards specific targets using social media data, is an important yet challenging task. With the proliferation of diverse multimodal social media content including text, and images multimodal stance detection (MSD) has become a crucial research area. However, existing MSD studies have focused on modeling stance within individual text-image pairs, overlooking the multi-party conversational contexts that naturally occur on social media. This limitation stems from a lack of datasets that authentically capture such conversational scenarios, hindering progress in conversational MSD. To address this, we introduce a new multimodal multi-turn conversational stance detection dataset (called MmMtCSD). To derive stances from this challenging dataset, we propose a novel multimodal large language model stance detection framework (MLLM-SD), that learns joint stance representations from textual and visual modalities. Experiments on MmMtCSD show state-of-the-art performance of our proposed MLLM-SD approach for multimodal stance detection. We believe that MmMtCSD will contribute to advancing real-world applications of stance detection research.