Learning to Ask: When LLM Agents Meet Unclear Instruction
作者: Wenxuan Wang, Juluan Shi, Zixuan Ling, Yuk-Kit Chan, Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, Michael R. Lyu
分类: cs.CL, cs.AI, cs.SE
发布日期: 2024-08-31 (更新: 2025-02-16)
💡 一句话要点
针对指令不明确场景,提出Ask-when-Needed框架提升LLM工具使用能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 指令不明确 主动提问 人机交互 自动化评估 Noisy ToolBench
📋 核心要点
- 现有LLM工具使用依赖精确指令,现实场景指令不明确导致性能下降,存在幻觉风险。
- 提出Ask-when-Needed框架,当LLM遇到不明确指令时,主动向用户提问以获取必要信息。
- 设计自动化评估工具ToolEvaluator,从准确性和效率评估LLM工具使用性能,实验证明AwN显著优于现有方法。
📝 摘要(中文)
现代大型语言模型(LLMs)具备调用函数的能力,可以利用外部工具来解决仅凭语言技能无法完成的各种任务。然而,这些工具的有效执行不仅依赖于LLMs的先进能力,还依赖于精确的用户指令,而这在现实世界中往往无法保证。为了评估LLMs在不完善指令下的工具使用性能,我们仔细检查了用户查询的真实指令,分析了错误模式,并构建了一个具有挑战性的工具使用基准,名为Noisy ToolBench (NoisyToolBench)。我们发现,由于next-token prediction的训练目标,LLMs倾向于随意生成缺失的参数,这可能导致幻觉和风险。为了解决这个问题,我们提出了一个名为Ask-when-Needed (AwN)的新框架,该框架提示LLMs在遇到由于指令不明确而造成的障碍时向用户提问。此外,为了减少用户-LLM交互中的人工劳动,并从准确性和效率的角度评估LLMs在工具利用方面的性能,我们设计了一个名为ToolEvaluator的自动化评估工具。我们的实验表明,AwN在NoisyToolBench中显著优于现有的工具学习框架。我们将发布所有相关的代码和数据集,以支持未来的研究。
🔬 方法详解
问题定义:论文旨在解决LLM在工具使用过程中,由于用户指令不明确而导致的性能下降问题。现有方法通常假设指令是清晰完整的,但在实际应用中,用户可能遗漏或模糊某些参数,导致LLM错误地生成参数,产生幻觉,甚至导致危险行为。
核心思路:论文的核心思路是让LLM具备“主动提问”的能力。当LLM在解析用户指令时遇到缺失或不明确的参数时,不是直接进行预测或生成,而是主动向用户提问,以获取更清晰的指令信息。这种方式可以有效避免LLM的盲目猜测,从而提高工具使用的准确性和安全性。
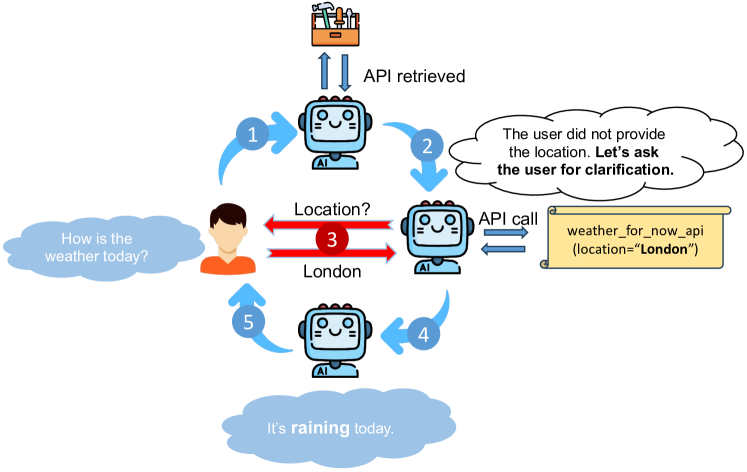
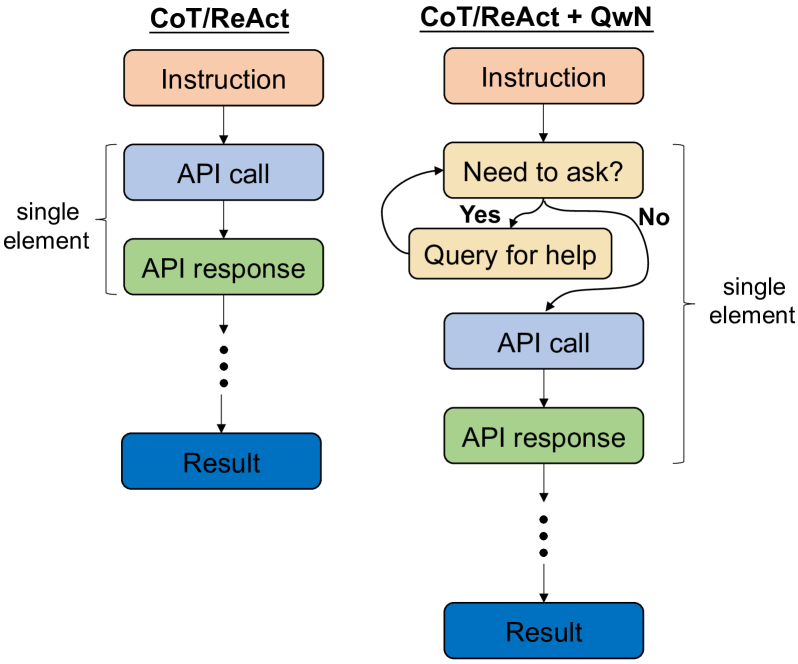
技术框架:Ask-when-Needed (AwN) 框架主要包含以下几个阶段:1. 指令解析:LLM首先解析用户指令,识别需要调用的工具和参数。2. 参数检查:检查指令中是否存在缺失或不明确的参数。3. 提问:如果发现缺失或不明确的参数,LLM会生成问题,向用户询问相关信息。4. 接收回答:LLM接收用户的回答,并将其整合到指令中。5. 工具调用:使用完善后的指令调用相应的工具。
关键创新:AwN框架的关键创新在于其“按需提问”的机制。与现有方法直接进行参数预测不同,AwN框架允许LLM在必要时与用户进行交互,从而获取更准确的指令信息。这种交互式的工具使用方式可以有效提高LLM的鲁棒性和可靠性。
关键设计:AwN框架的关键设计包括:1. 问题生成策略:如何生成清晰、简洁且能够有效获取所需信息的问题。2. 回答整合策略:如何将用户的回答有效地整合到原始指令中,以便后续的工具调用。3. ToolEvaluator自动化评估工具:用于评估LLM在工具使用方面的准确性和效率,减少人工评估成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在NoisyToolBench基准测试中,AwN框架显著优于现有的工具学习框架。具体而言,AwN框架在工具使用准确率方面取得了显著提升,有效降低了LLM的幻觉现象。此外,ToolEvaluator自动化评估工具能够高效地评估LLM的工具使用性能,为未来的研究提供了有力的支持。
🎯 应用场景
该研究成果可应用于各种需要LLM进行工具调用的场景,例如智能助手、自动化客服、智能家居控制等。通过提高LLM在不明确指令下的工具使用能力,可以提升用户体验,降低错误率,并扩展LLM的应用范围。未来,该研究可以进一步探索更复杂的交互模式和更智能的提问策略。
📄 摘要(原文)
Equipped with the capability to call functions, modern large language models (LLMs) can leverage external tools for addressing a range of tasks unattainable through language skills alone. However, the effective execution of these tools relies heavily not just on the advanced capabilities of LLMs but also on precise user instructions, which often cannot be ensured in the real world. To evaluate the performance of LLMs tool-use under imperfect instructions, we meticulously examine the real-world instructions queried from users, analyze the error patterns, and build a challenging tool-use benchmark called Noisy ToolBench (NoisyToolBench). We find that due to the next-token prediction training objective, LLMs tend to arbitrarily generate the missed argument, which may lead to hallucinations and risks. To address this issue, we propose a novel framework, Ask-when-Needed (AwN), which prompts LLMs to ask questions to users whenever they encounter obstacles due to unclear instructions. Moreover, to reduce the manual labor involved in user-LLM interaction and assess LLMs performance in tool utilization from both accuracy and efficiency perspectives, we design an automated evaluation tool named ToolEvaluator. Our experiments demonstrate that the AwN significantly outperforms existing frameworks for tool learning in the NoisyToolBench. We will release all related code and datasets to support future research.