LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
作者: Zhiyuan Hu, Yuliang Liu, Jinman Zhao, Suyuchen Wang, Yan Wang, Wei Shen, Qing Gu, Anh Tuan Luu, See-Kiong Ng, Zhiwei Jiang, Bryan Hooi
分类: cs.CL
发布日期: 2024-08-31 (更新: 2024-09-04)
备注: Work in Progress
🔗 代码/项目: GITHUB
💡 一句话要点
LongRecipe:一种高效的长文本泛化训练方法,显著扩展大语言模型的上下文窗口。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 上下文窗口扩展 高效训练 大语言模型 长程依赖 位置编码 token分析
📋 核心要点
- 现有大语言模型在长文本处理中受限于预训练时的上下文窗口大小,导致长序列泛化能力不足。
- LongRecipe通过token分析、位置索引转换和训练优化,模拟长序列输入,提升模型对长程依赖的理解。
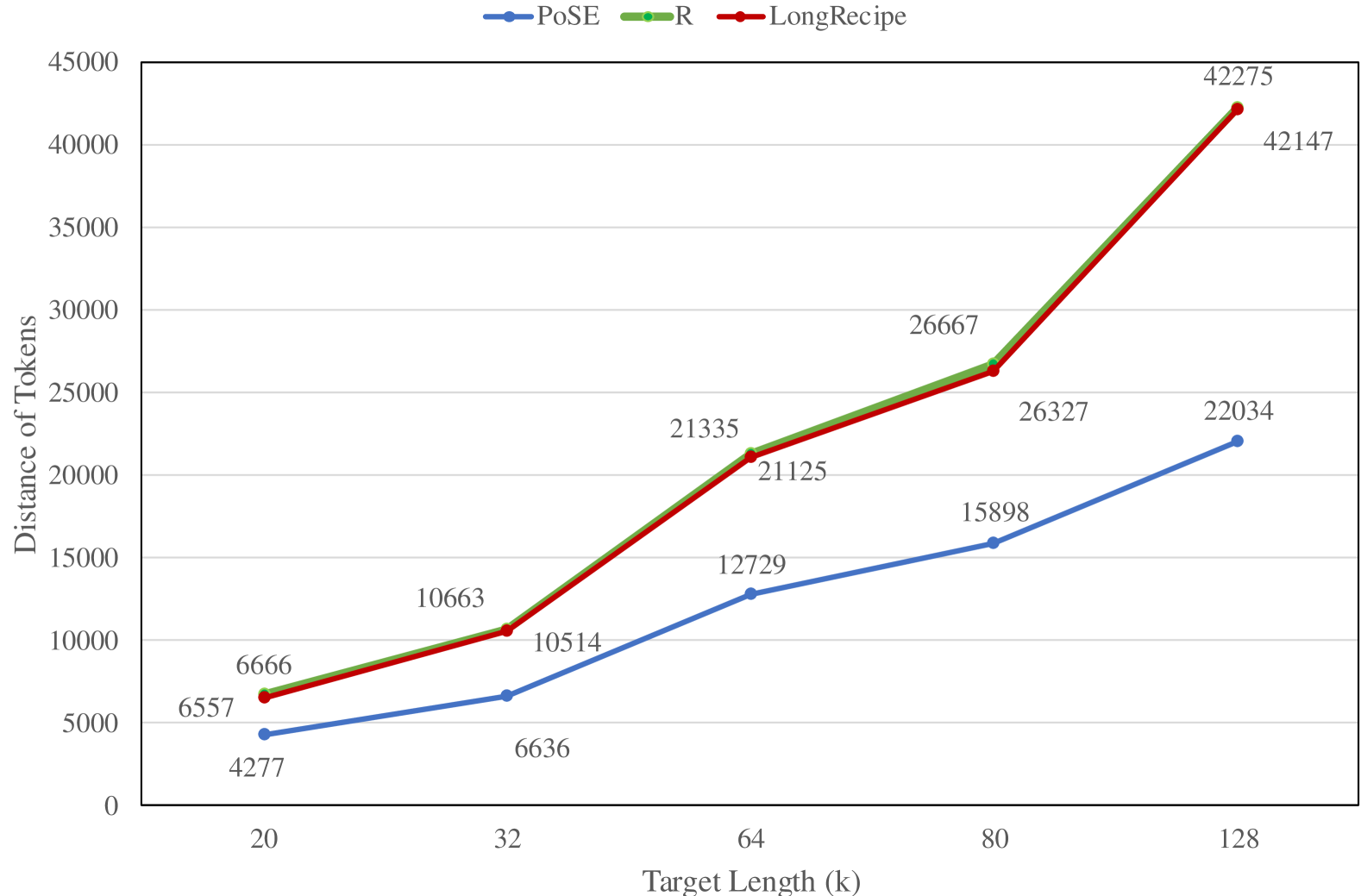
- 实验表明,LongRecipe仅需目标上下文窗口30%的数据,计算资源减少85%,即可将上下文窗口扩展至128k。
📝 摘要(中文)
大型语言模型(LLMs)在处理长文本任务时面临重大挑战,因为预训练期间有效的上下文窗口大小有限,限制了它们在扩展序列上的泛化能力。同时,通过后预训练扩展LLMs的上下文窗口需要消耗大量资源。为了解决这个问题,我们提出了LongRecipe,一种高效的训练策略,用于扩展LLMs的上下文窗口,包括有影响力的token分析、位置索引转换和训练优化策略。它模拟长序列输入,同时保持训练效率,并显著提高模型对长程依赖关系的理解。在三种LLMs上的实验表明,LongRecipe可以使用长序列,同时仅需要目标上下文窗口大小的30%,并且与完整序列训练相比,计算训练资源减少了85%以上。此外,LongRecipe还保留了原始LLM在通用任务中的能力。最终,我们可以将开源LLMs的有效上下文窗口从8k扩展到128k,仅使用具有80G内存的单个GPU进行一天的专门训练,即可实现接近GPT-4的性能。我们的代码已在https://github.com/zhiyuanhubj/LongRecipe上发布。
🔬 方法详解
问题定义:现有的大语言模型在处理长文本时,由于预训练阶段上下文窗口的限制,难以捕捉长距离依赖关系,导致在长文本任务上的性能下降。直接扩展上下文窗口需要大量的计算资源,成本高昂。
核心思路:LongRecipe的核心思路是通过一种高效的训练策略,模拟长序列输入,使模型能够在有限的计算资源下学习到长距离依赖关系。该方法旨在提高训练效率,同时保留模型在通用任务上的能力。
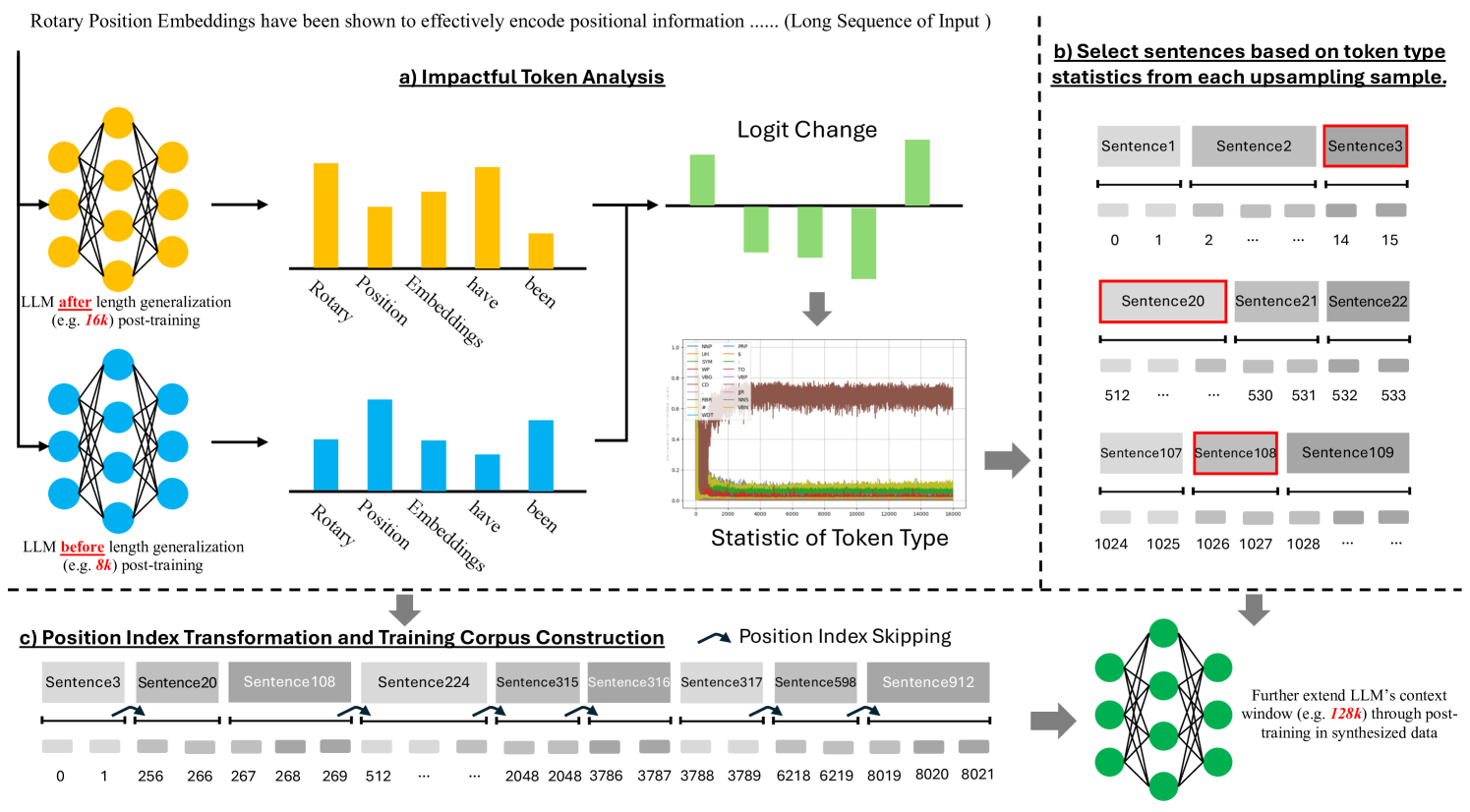
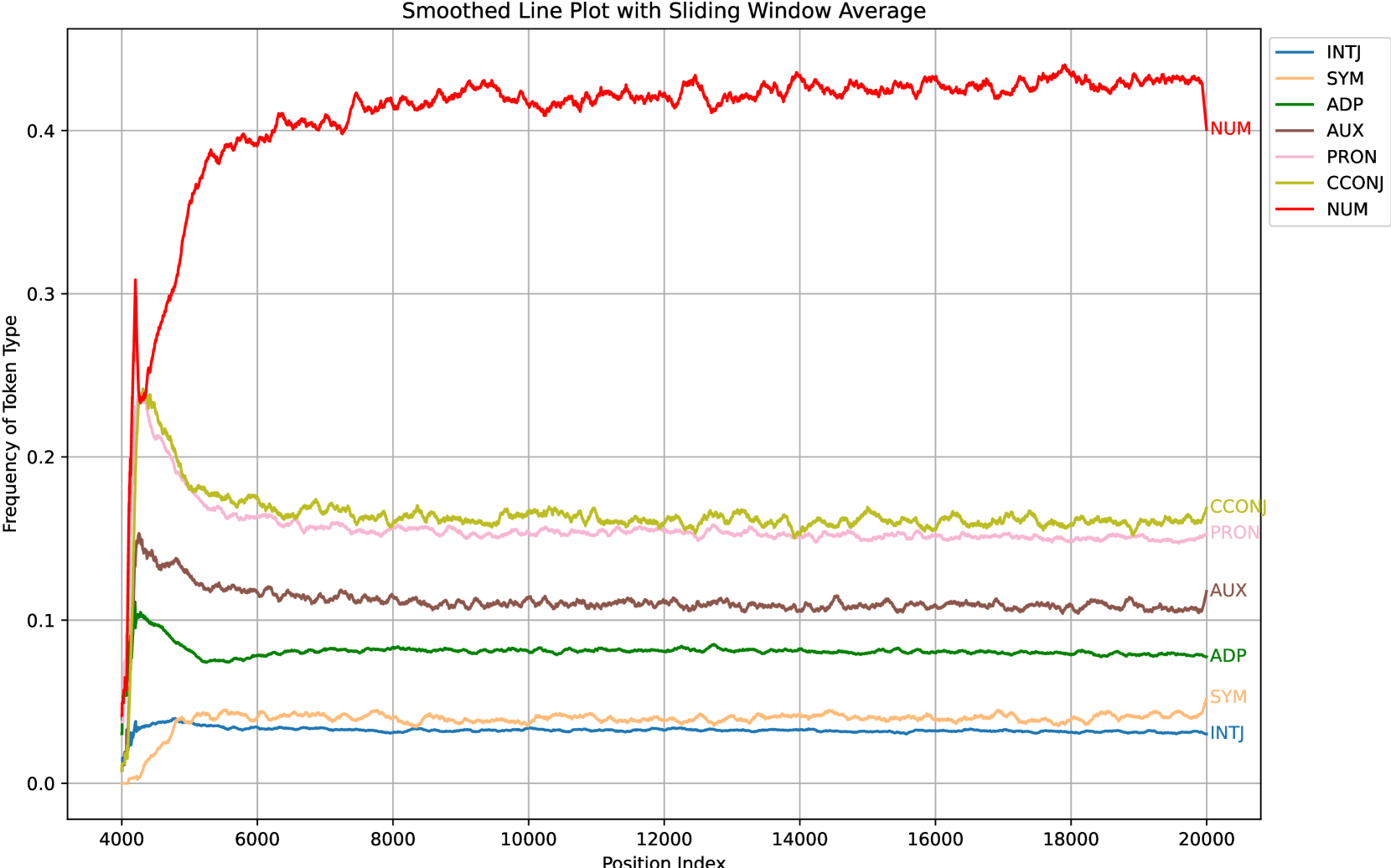
技术框架:LongRecipe包含三个主要组成部分:1) Token分析:用于识别对模型性能影响较大的token,并优先关注这些token的学习。2) 位置索引转换:通过特定的转换方法,使模型能够更好地处理长序列中的位置信息。3) 训练优化策略:采用一系列优化策略,例如梯度累积、混合精度训练等,以提高训练效率。
关键创新:LongRecipe的关键创新在于其高效的训练策略,它能够在仅使用目标上下文窗口大小的30%数据的情况下,将模型的上下文窗口扩展到128k。这种方法显著降低了训练成本,使得在资源有限的条件下训练长文本模型成为可能。
关键设计:LongRecipe的具体设计包括:1) Token选择策略:选择对模型性能影响最大的token进行重点训练。2) 位置编码策略:采用相对位置编码或位置插值等方法,以适应扩展后的上下文窗口。3) 训练参数设置:采用较小的学习率和较大的batch size,以提高训练的稳定性。
🖼️ 关键图片
📊 实验亮点
LongRecipe在三种LLMs上的实验表明,仅需目标上下文窗口大小的30%的数据,即可将开源LLMs的有效上下文窗口从8k扩展到128k,并且计算训练资源减少了85%以上。使用单个80G GPU训练一天即可达到接近GPT-4的性能,充分验证了该方法的有效性和高效性。
🎯 应用场景
LongRecipe具有广泛的应用前景,可应用于长文本摘要、文档问答、代码生成等领域。该方法能够有效提升大语言模型在处理长文本任务时的性能,并降低训练成本,加速长文本大模型的落地应用。未来,该技术有望推动更多长文本相关应用的创新。
📄 摘要(原文)
Large language models (LLMs) face significant challenges in handling long-context tasks because of their limited effective context window size during pretraining, which restricts their ability to generalize over extended sequences. Meanwhile, extending the context window in LLMs through post-pretraining is highly resource-intensive. To address this, we introduce LongRecipe, an efficient training strategy for extending the context window of LLMs, including impactful token analysis, position index transformation, and training optimization strategies. It simulates long-sequence inputs while maintaining training efficiency and significantly improves the model's understanding of long-range dependencies. Experiments on three types of LLMs show that LongRecipe can utilize long sequences while requiring only 30% of the target context window size, and reduces computational training resource over 85% compared to full sequence training. Furthermore, LongRecipe also preserves the original LLM's capabilities in general tasks. Ultimately, we can extend the effective context window of open-source LLMs from 8k to 128k, achieving performance close to GPT-4 with just one day of dedicated training using a single GPU with 80G memory. Our code is released at https://github.com/zhiyuanhubj/LongRecipe.