From Prediction to Application: Language Model-based Code Knowledge Tracing with Domain Adaptive Pre-Training and Automatic Feedback System with Pedagogical Prompting for Comprehensive Programming Education
作者: Unggi Lee, Jiyeong Bae, Yeonji Jung, Minji Kang, Gyuri Byun, Yeonseo Lee, Dohee Kim, Sookbun Lee, Jaekwon Park, Taekyung Ahn, Gunho Lee, Hyeoncheol Kim
分类: cs.CL, cs.SE
发布日期: 2024-08-31
备注: 9 pages, 2 figures
DOI: 10.13140/RG.2.2.25134.11847
💡 一句话要点
提出CodeLKT:基于语言模型的代码知识追踪与自适应反馈系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码知识追踪 语言模型 预训练 领域自适应 个性化反馈
📋 核心要点
- 传统知识追踪方法缺乏可解释性,且难以跨领域应用,限制了在线编程教育的个性化和智能化。
- CodeLKT利用预训练语言模型进行代码知识追踪,并通过领域自适应预训练和任务自适应预训练提升模型性能。
- 实验表明,CodeLKT优于现有知识追踪模型,并结合大型语言模型生成个性化反馈,有效支持编程学习。
📝 摘要(中文)
本文提出了一种基于语言模型的代码知识追踪方法(CodeLKT),旨在解决传统知识追踪方法在可解释性和跨领域适应性方面的局限性。CodeLKT利用预训练语言模型处理学习数据,在性能上优于现有的知识追踪和代码知识追踪模型。研究探索了领域自适应预训练(DAPT)和任务自适应预训练(TAPT),表明其在编码领域具有增强的性能,并研究了数学和编码之间的跨领域迁移。此外,本文还提出了一个理论驱动的集成系统,该系统结合了CodeLKT与大型语言模型,以生成个性化的、深入的反馈,从而支持学生的编程学习。这项工作通过扩展基于语言模型的方法的知识库,并提供通过数据驱动的反馈对编程教育的实际意义,从而推进了代码知识追踪领域。
🔬 方法详解
问题定义:论文旨在解决传统知识追踪(KT)方法在编程教育领域应用的局限性。现有KT模型的可解释性较差,难以捕捉代码的语义信息,并且在不同编程领域之间的迁移能力不足。此外,如何利用KT模型为学生提供个性化的、有针对性的反馈也是一个挑战。
核心思路:论文的核心思路是利用预训练语言模型(Language Model)强大的语义理解能力,将其应用于代码知识追踪任务。通过对代码进行建模,可以更准确地评估学生的编程知识掌握程度,并基于此生成个性化的反馈。此外,通过领域自适应预训练(DAPT)和任务自适应预训练(TAPT),可以进一步提升模型在特定编程领域和任务上的性能。
技术框架:CodeLKT的整体框架包括以下几个主要模块:1) 数据预处理模块:对编程学习数据进行清洗和转换,使其适用于语言模型的输入格式。2) 语言模型编码模块:使用预训练语言模型(如BERT、CodeBERT等)对代码进行编码,提取代码的语义特征。3) 知识追踪模块:基于语言模型的编码结果,预测学生在特定编程概念上的掌握程度。4) 反馈生成模块:结合CodeLKT的预测结果和大型语言模型,生成个性化的、有针对性的编程反馈。
关键创新:该论文的关键创新在于将语言模型应用于代码知识追踪任务,并提出了领域自适应预训练和任务自适应预训练方法。与传统的基于规则或统计的KT模型相比,CodeLKT能够更好地理解代码的语义信息,从而更准确地评估学生的知识掌握程度。此外,结合大型语言模型生成反馈,可以为学生提供更个性化、更深入的学习支持。
关键设计:在领域自适应预训练(DAPT)中,使用大量的编程代码数据对预训练语言模型进行微调,使其更好地适应编程领域的特点。在任务自适应预训练(TAPT)中,使用特定的编程任务数据(如代码补全、代码纠错等)对模型进行进一步微调,以提升模型在特定任务上的性能。损失函数方面,可以使用交叉熵损失函数或BCE损失函数来训练知识追踪模型。网络结构方面,可以使用Transformer或其他适合序列建模的网络结构。
🖼️ 关键图片

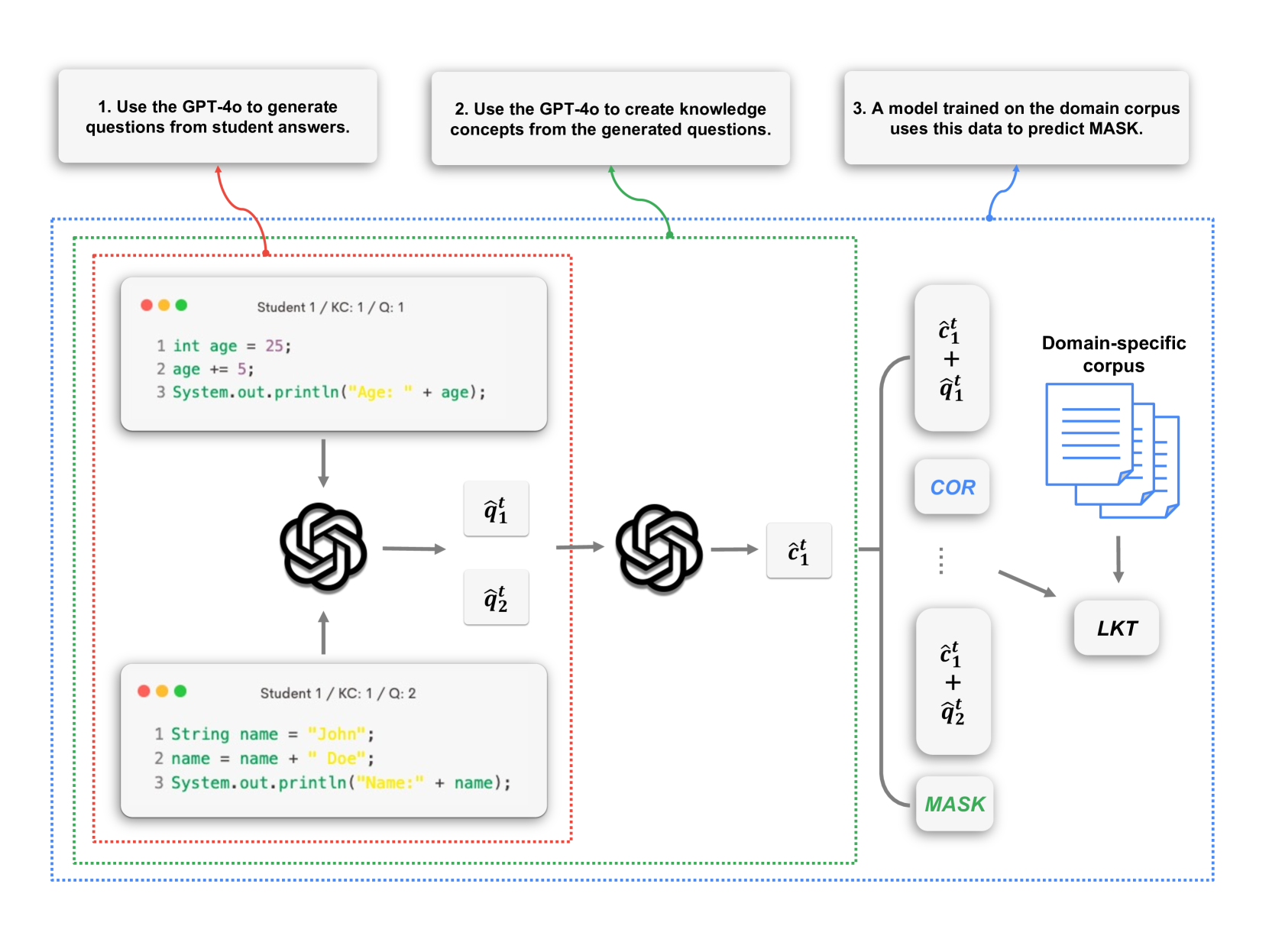
📊 实验亮点
实验结果表明,CodeLKT在代码知识追踪任务上优于现有的知识追踪模型和代码知识追踪模型。通过领域自适应预训练和任务自适应预训练,模型性能得到进一步提升。此外,结合大型语言模型生成的个性化反馈能够有效提高学生的学习效果。具体性能提升数据未知。
🎯 应用场景
CodeLKT可应用于在线编程教育平台,为学生提供个性化的学习路径和实时的反馈。它可以帮助教师更好地了解学生的学习情况,并根据学生的知识掌握程度调整教学策略。此外,CodeLKT还可以用于评估学生的编程能力,为企业招聘提供参考。
📄 摘要(原文)
Knowledge Tracing (KT) is a critical component in online learning, but traditional approaches face limitations in interpretability and cross-domain adaptability. This paper introduces Language Model-based Code Knowledge Tracing (CodeLKT), an innovative application of Language model-based Knowledge Tracing (LKT) to programming education. CodeLKT leverages pre-trained language models to process learning data, demonstrating superior performance over existing KT and Code KT models. We explore Domain Adaptive Pre-Training (DAPT) and Task Adaptive Pre-Training (TAPT), showing enhanced performance in the coding domain and investigating cross-domain transfer between mathematics and coding. Additionally, we present an theoretically-informed integrated system combining CodeLKT with large language models to generate personalized, in-depth feedback to support students' programming learning. This work advances the field of Code Knowledge Tracing by expanding the knowledge base with language model-based approach and offering practical implications for programming education through data-informed feedback.