Pre-Training Multimodal Hallucination Detectors with Corrupted Grounding Data
作者: Spencer Whitehead, Jacob Phillips, Sean Hendryx
分类: cs.CL, cs.CV
发布日期: 2024-08-30
💡 一句话要点
提出一种基于损坏的 grounding 数据预训练的多模态幻觉检测方法,提升样本效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 幻觉检测 预训练 grounding数据 序列标注
📋 核心要点
- 多模态语言模型易产生幻觉,降低了可靠性,而现有幻觉检测方法缺乏定位能力。
- 通过生成损坏的 grounding 数据进行预训练,提升模型在幻觉检测任务中的样本效率。
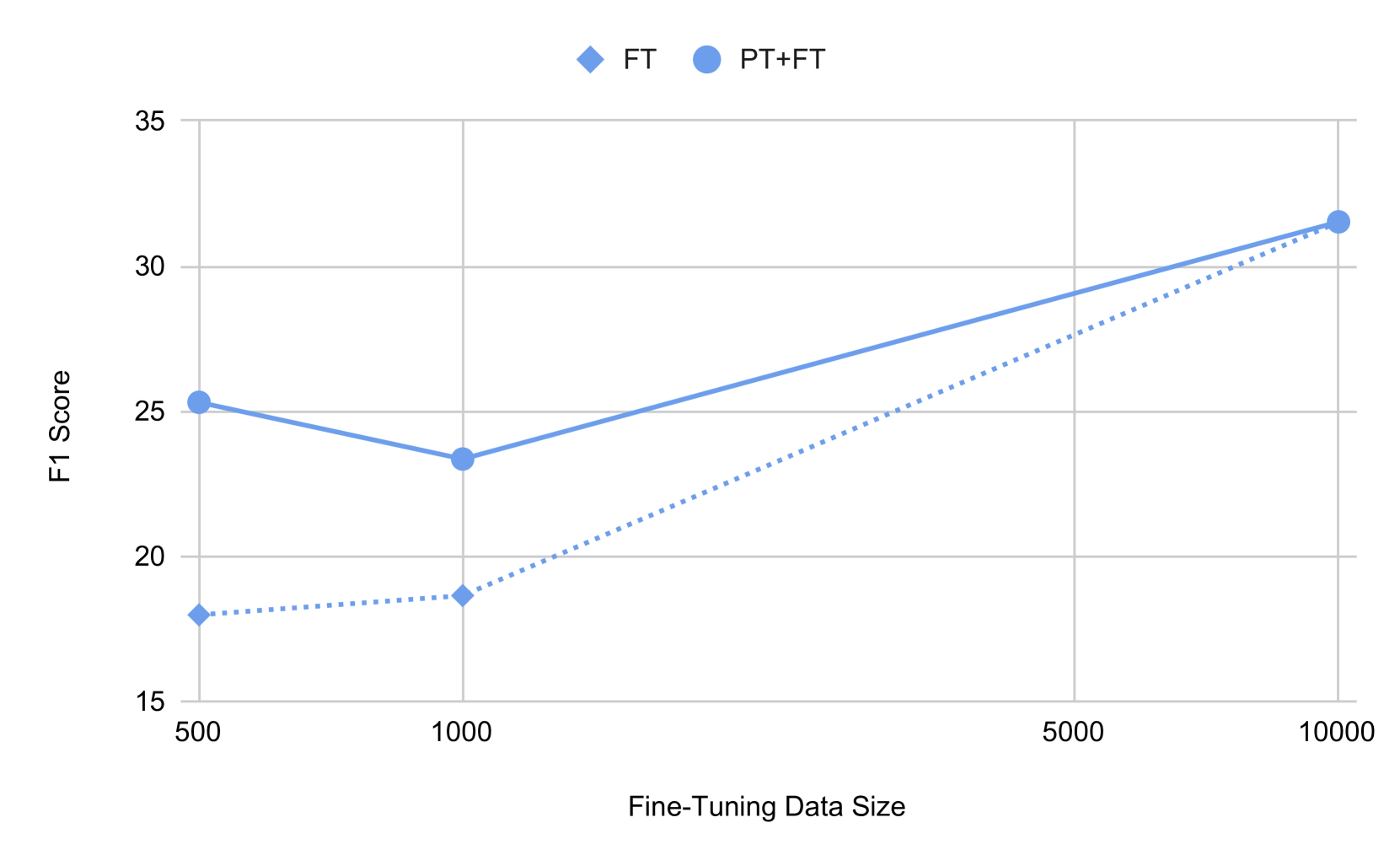
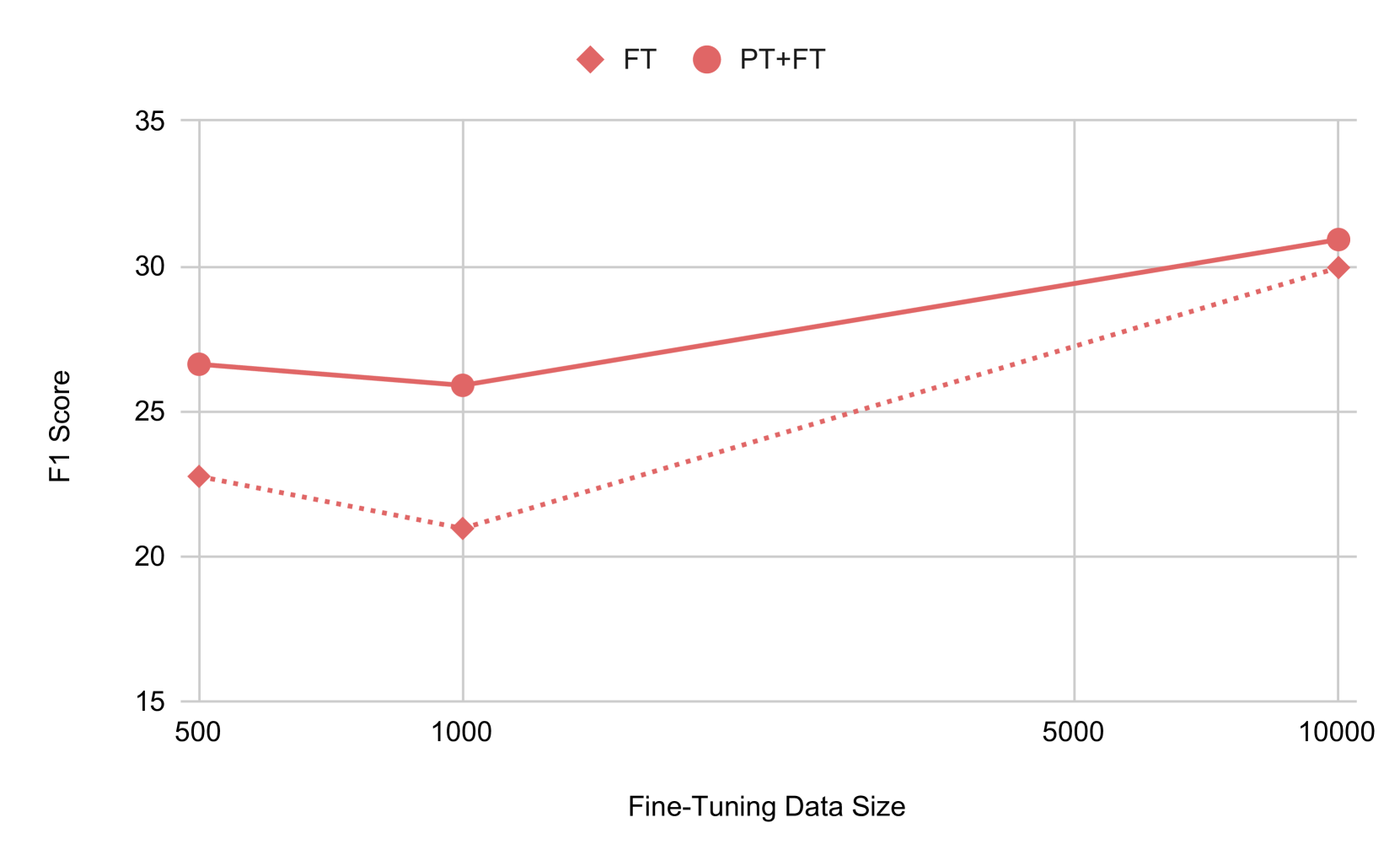
- 实验表明,预训练能有效提升微调阶段的样本效率, grounding 数据的学习信号至关重要。
📝 摘要(中文)
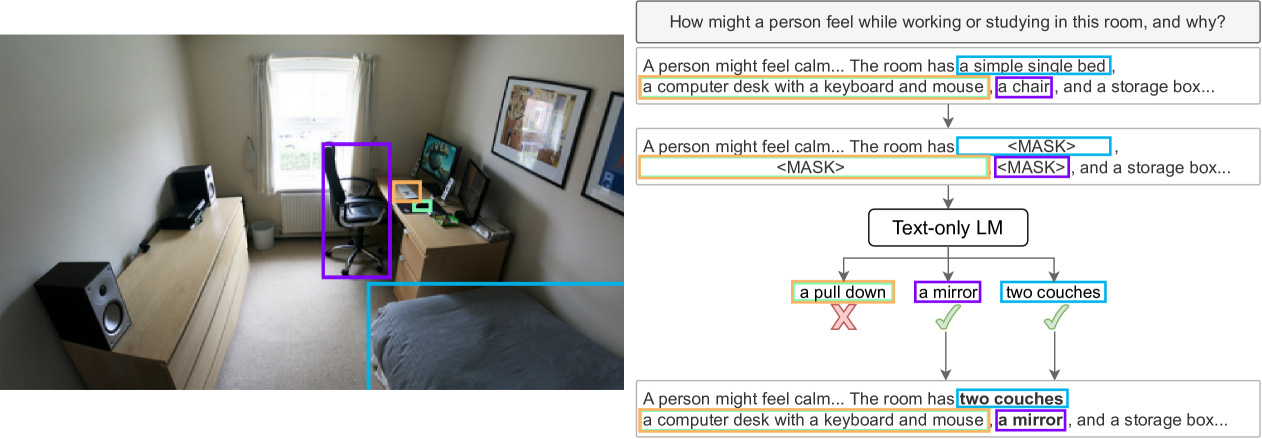
多模态语言模型在其输出中可能出现幻觉,这限制了它们的可靠性。自动检测这些错误的能力对于缓解它们至关重要,但相关研究较少,并且现有工作没有定位幻觉,而是将其视为分类任务。本文首先将多模态幻觉检测定义为序列标注任务,模型必须定位幻觉文本跨度,并提出了一个强大的基线模型。考虑到此任务的人工标注成本很高,我们提出了一种通过创建损坏的 grounding 数据来提高这些模型样本效率的方法,并将其用于预训练。利用短语 grounding 数据,我们生成幻觉来替换已 grounding 的跨度,并创建幻觉文本。实验表明,在此数据上进行预训练可以提高微调时的样本效率,并且来自 grounding 数据的学习信号在这些改进中起着重要作用。
🔬 方法详解
问题定义:论文旨在解决多模态语言模型中幻觉检测的问题,特别是缺乏对幻觉文本跨度的精确定位。现有方法通常将幻觉检测视为一个分类任务,无法指出具体的幻觉内容,这限制了模型的可解释性和实用性。人工标注幻觉数据成本高昂,限制了模型的训练规模和泛化能力。
核心思路:论文的核心思路是利用 phrase grounding 数据,通过人为引入错误(即生成幻觉并替换原始 grounding 文本)来构建大规模的预训练数据集。这种方法旨在让模型学习区分真实 grounding 和幻觉之间的差异,从而提高其在真实场景中检测幻觉的能力。通过预训练,模型可以获得更好的初始化参数,从而在后续的微调阶段提高样本效率。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:收集 phrase grounding 数据集,其中包含图像和对应的文本描述,以及文本中每个短语与图像区域的对应关系。2) 幻觉生成:对于每个 grounding 文本,随机选择一些短语,并使用其他文本生成模型(如语言模型)生成与图像不相关的幻觉文本来替换这些短语。3) 预训练:使用包含原始 grounding 数据和生成的幻觉数据的混合数据集来预训练多模态模型。预训练的目标是让模型能够区分真实 grounding 和幻觉。4) 微调:在真实的幻觉检测数据集上微调预训练模型,使其能够精确定位幻觉文本跨度。
关键创新:该论文的关键创新在于提出了一种利用损坏的 grounding 数据进行预训练的方法,以提高多模态幻觉检测模型的样本效率。与传统的监督学习方法相比,该方法能够利用大规模的 grounding 数据,通过人为引入幻觉来增强模型的鲁棒性和泛化能力。此外,该论文还将幻觉检测问题定义为序列标注任务,使得模型能够精确定位幻觉文本跨度。
关键设计:在幻觉生成阶段,需要仔细设计幻觉生成策略,以确保生成的幻觉文本与图像不相关,并且与原始文本在语义上存在一定的差异。预训练阶段可以使用对比学习或 masked language modeling 等方法,以增强模型对 grounding 和幻觉的区分能力。微调阶段可以使用序列标注模型,如 BiLSTM-CRF 或 Transformer,并采用合适的损失函数,如交叉熵损失或 focal loss。
🖼️ 关键图片
📊 实验亮点
该研究通过在损坏的 grounding 数据上进行预训练,显著提高了多模态幻觉检测模型的样本效率。实验结果表明,与不进行预训练的模型相比,该方法在微调阶段能够更快地收敛,并且在幻觉检测的准确率和召回率方面均有显著提升。具体的性能数据和对比基线在论文中给出,表明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种多模态语言模型,例如图像描述生成、视觉问答等,提高模型输出的可靠性和准确性。通过自动检测和定位幻觉,可以减少错误信息的传播,提升用户体验。未来,该技术有望应用于内容审核、智能客服等领域,降低人工审核成本,提高服务质量。
📄 摘要(原文)
Multimodal language models can exhibit hallucinations in their outputs, which limits their reliability. The ability to automatically detect these errors is important for mitigating them, but has been less explored and existing efforts do not localize hallucinations, instead framing this as a classification task. In this work, we first pose multimodal hallucination detection as a sequence labeling task where models must localize hallucinated text spans and present a strong baseline model. Given the high cost of human annotations for this task, we propose an approach to improve the sample efficiency of these models by creating corrupted grounding data, which we use for pre-training. Leveraging phrase grounding data, we generate hallucinations to replace grounded spans and create hallucinated text. Experiments show that pre-training on this data improves sample efficiency when fine-tuning, and that the learning signal from the grounding data plays an important role in these improvements.