Can Large Language Models Address Open-Target Stance Detection?
作者: Abu Ubaida Akash, Ahmed Fahmy, Amine Trabelsi
分类: cs.CL
发布日期: 2024-08-30 (更新: 2025-05-30)
备注: Accepted; ACL 2025 (Findings)
💡 一句话要点
提出开放目标立场检测(OTSD)任务,并评估大型语言模型(LLMs)的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放目标立场检测 大型语言模型 立场检测 目标生成 自然语言处理
📋 核心要点
- 现有立场检测方法依赖于预定义的目标列表,限制了其在开放场景中的应用。
- 本文提出开放目标立场检测(OTSD)任务,旨在评估模型在没有预定义目标的情况下识别立场的能力。
- 实验结果表明,大型语言模型(LLMs)在OTSD任务上表现出潜力,但在隐式目标情况下仍面临挑战。
📝 摘要(中文)
本文提出了开放目标立场检测(OTSD)任务,这是一个更贴近实际场景的任务,其中目标在训练期间不可见,也不作为输入提供。作者评估了来自GPT、Gemini、Llama和Mistral系列的大型语言模型(LLMs),并将它们的性能与现有的目标-立场抽取(TSE)方法进行了比较,后者受益于预定义的目标。与TSE不同,OTSD消除了对预定义列表的依赖,使得目标生成和评估更具挑战性。作者还提供了一种评估目标质量的指标,该指标与人类判断具有良好的相关性。实验结果表明,LLMs在目标生成方面优于TSE,无论真实目标是否在文本中明确提及。同样,LLMs在立场检测方面总体上超过了TSE,无论目标是否明确。然而,当目标不明确时,LLMs在目标生成和立场检测方面都表现不佳。
🔬 方法详解
问题定义:现有的立场检测方法通常依赖于预先定义的目标列表,这在实际应用中存在局限性。真实世界的场景往往涉及未知的、动态变化的目标。因此,如何有效地检测针对未见目标的立场成为一个重要的研究问题。现有的目标-立场抽取(TSE)方法虽然可以抽取目标,但仍然依赖于预定义的目标列表,无法完全解决开放目标的问题。
核心思路:本文的核心思路是利用大型语言模型(LLMs)的强大生成和推理能力,直接从文本中生成目标,并判断文本对生成目标的立场。这种方法无需预定义的目标列表,更贴近实际应用场景。通过比较LLMs和TSE方法在开放目标立场检测(OTSD)任务上的性能,评估LLMs在处理开放目标立场检测任务上的潜力。
技术框架:整体框架包含两个主要阶段:目标生成和立场检测。在目标生成阶段,LLM接收一段文本作为输入,并生成一个或多个目标。在立场检测阶段,LLM接收文本和生成的目标作为输入,并判断文本对该目标的立场(支持、反对或中立)。作者还提出了一种评估目标质量的指标,用于评估生成目标的合理性。
关键创新:最重要的创新点在于提出了开放目标立场检测(OTSD)任务,并探索了大型语言模型(LLMs)在解决该任务上的能力。与现有的目标-立场抽取(TSE)方法相比,OTSD无需预定义的目标列表,更具挑战性和实用性。此外,作者还提出了一种评估目标质量的指标,为评估生成目标的合理性提供了依据。
关键设计:作者使用了来自GPT、Gemini、Llama和Mistral等多个LLM家族的模型进行实验。对于目标生成,采用prompt engineering的方式引导LLM生成目标。对于立场检测,同样采用prompt engineering的方式,将文本和生成的目标作为输入,让LLM判断立场。目标质量评估指标的设计考虑了目标与文本的相关性和合理性,具体计算方法未知。
🖼️ 关键图片
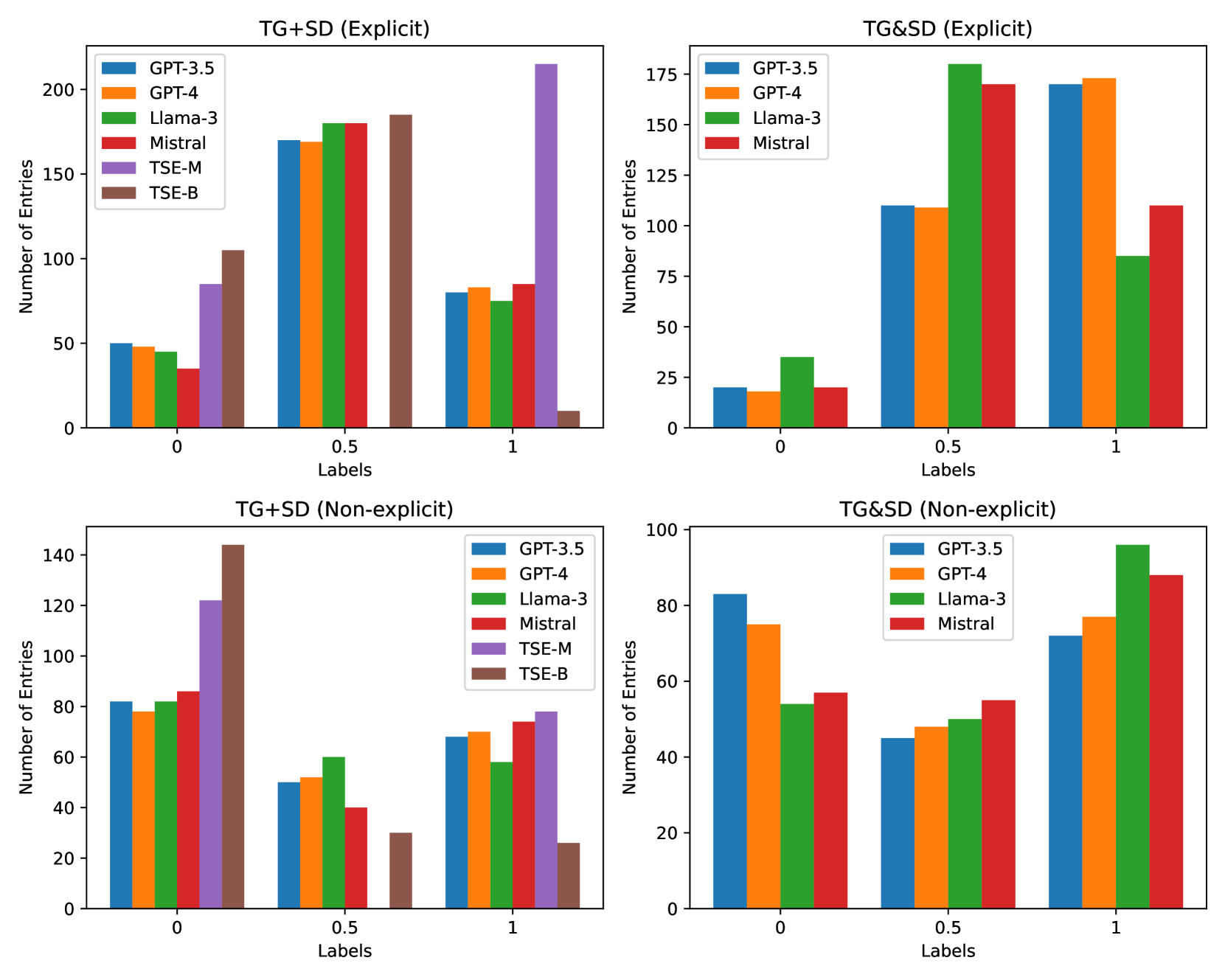
📊 实验亮点
实验结果表明,大型语言模型(LLMs)在开放目标立场检测(OTSD)任务上表现出优于现有目标-立场抽取(TSE)方法的性能。在目标生成方面,LLMs能够生成更合理、更相关的目标。在立场检测方面,LLMs在显式目标情况下表现良好,但在隐式目标情况下仍面临挑战。具体性能数据未知。
🎯 应用场景
该研究成果可应用于舆情分析、社交媒体监控、虚假信息检测等领域。通过自动检测针对各种目标的立场,可以帮助人们更好地理解社会舆论,及时发现潜在的风险和问题。未来,该技术还可以应用于智能客服、个性化推荐等领域,提供更精准、更智能的服务。
📄 摘要(原文)
Stance detection (SD) identifies the text position towards a target, typically labeled as favor, against, or none. We introduce Open-Target Stance Detection (OTSD), the most realistic task where targets are neither seen during training nor provided as input. We evaluate Large Language Models (LLMs) from GPT, Gemini, Llama, and Mistral families, comparing their performance to the only existing work, Target-Stance Extraction (TSE), which benefits from predefined targets. Unlike TSE, OTSD removes the dependency of a predefined list, making target generation and evaluation more challenging. We also provide a metric for evaluating target quality that correlates well with human judgment. Our experiments reveal that LLMs outperform TSE in target generation, both when the real target is explicitly and not explicitly mentioned in the text. Similarly, LLMs overall surpass TSE in stance detection for both explicit and non-explicit cases. However, LLMs struggle in both target generation and stance detection when the target is not explicit.