MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
作者: Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
分类: cs.CL, cs.AI
发布日期: 2024-08-30
🔗 代码/项目: GITHUB
💡 一句话要点
提出MultiMath以解决视觉与数学推理整合问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数学推理 视觉信息 大型语言模型 教育技术 数据集构建
📋 核心要点
- 现有的开源大型语言模型在数学推理方面表现良好,但缺乏与视觉信息的有效整合,限制了其应用。
- 本文提出MultiMath-7B,通过四个阶段的训练,结合视觉与数学推理,填补了这一领域的空白。
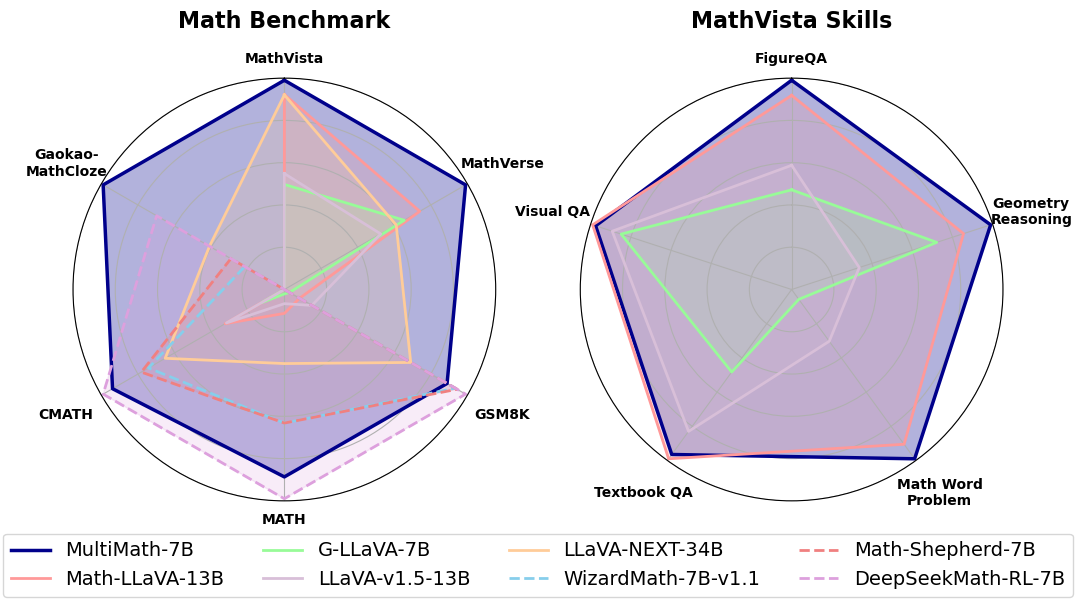
- MultiMath-7B在多模态数学基准测试中达到了最先进的性能,并在文本-only数学基准测试中也表现优异,展示了其强大的能力。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展促使了对其领域特定能力的广泛研究,尤其是在数学推理方面。然而,大多数开源LLMs仅专注于数学推理,忽视了与视觉输入的整合。为填补这一空白,本文提出了MultiMath-7B,这是一种多模态大型语言模型,旨在连接数学与视觉。MultiMath-7B通过四个阶段进行训练,重点关注视觉与语言的对齐、视觉与数学的指令调优以及过程监督的强化学习。此外,我们构建了一个新颖、多样且全面的多模态数学数据集MultiMath-300K,涵盖K-12水平,包含图像说明和逐步解决方案。MultiMath-7B在现有的多模态数学基准测试中实现了开源模型的最先进性能,并在文本-only数学基准测试中表现出色。我们的模型和数据集可在https://github.com/pengshuai-rin/MultiMath获取。
🔬 方法详解
问题定义:本文旨在解决现有大型语言模型在数学推理中未能有效整合视觉信息的问题。许多数学任务依赖于视觉输入,如几何图形和图表,现有方法未能充分利用这些信息。
核心思路:论文提出的MultiMath-7B模型通过多模态学习,将视觉信息与数学推理相结合,增强了模型在处理复杂数学任务时的能力。通过视觉与语言的对齐,模型能够更好地理解和解决数学问题。
技术框架:MultiMath-7B的训练过程分为四个阶段:首先进行视觉与语言的对齐,然后进行视觉和数学的指令调优,接着实施过程监督的强化学习,最后进行模型的优化和评估。
关键创新:最重要的技术创新在于构建了一个多模态数学数据集MultiMath-300K,涵盖了K-12教育水平的多样化数学任务,并提供了图像说明和逐步解决方案,这为模型的训练提供了丰富的资源。
关键设计:在模型设计中,采用了多模态学习框架,结合了视觉特征提取和语言理解模块,损失函数设计上考虑了视觉与语言的对齐度,确保模型能够有效学习两者之间的关系。
🖼️ 关键图片


📊 实验亮点
MultiMath-7B在多模态数学基准测试中实现了最先进的性能,相较于现有开源模型,提升幅度显著。同时,在文本-only数学基准测试中也表现优异,展示了其强大的综合能力。
🎯 应用场景
该研究的潜在应用领域包括教育技术、智能辅导系统和数学问题自动解答等。通过将视觉信息与数学推理相结合,MultiMath-7B能够为学生提供更直观的学习体验,提升学习效果,未来可能在教育领域产生深远影响。
📄 摘要(原文)
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.