A Survey for Large Language Models in Biomedicine
作者: Chong Wang, Mengyao Li, Junjun He, Zhongruo Wang, Erfan Darzi, Zan Chen, Jin Ye, Tianbin Li, Yanzhou Su, Jing Ke, Kaili Qu, Shuxin Li, Yi Yu, Pietro Liò, Tianyun Wang, Yu Guang Wang, Yiqing Shen
分类: cs.CL, cs.AI
发布日期: 2024-08-29
💡 一句话要点
综述性分析生物医学领域大语言模型,聚焦实际应用、挑战与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物医学 大语言模型 综述 零样本学习 微调 数据隐私 可解释AI
📋 核心要点
- 现有生物医学LLM综述缺乏对跨领域进展的整合分析,未能充分关注实际应用。
- 本综述深入分析了LLM在生物医学领域的零样本学习能力和适应策略,并探讨了其面临的挑战。
- 论文提出了未来研究方向,包括联邦学习保护隐私和可解释AI提高透明度,以应对现有挑战。
📝 摘要(中文)
大型语言模型(LLM)的最新突破提供了前所未有的自然语言理解和生成能力。然而,现有的生物医学领域LLM综述通常侧重于特定应用或模型架构,缺乏整合各个生物医学领域最新进展的全面分析。本综述基于对来自PubMed、Web of Science和arXiv等数据库的484篇出版物的分析,深入研究了LLM在生物医学领域的现状、应用、挑战和前景,其特点是关注这些模型在现实生物医学环境中的实际意义。首先,我们探讨了LLM在广泛的生物医学任务中的零样本学习能力,包括诊断辅助、药物发现和个性化医疗等,并从137项关键研究中汲取了见解。然后,我们讨论了LLM的适应策略,包括用于单模态和多模态LLM的微调方法,以增强它们在专业生物医学环境中的性能,例如医学问答和生物医学文献的高效处理。最后,我们讨论了LLM在生物医学领域面临的挑战,包括数据隐私问题、模型可解释性有限、数据集质量问题以及伦理问题,并确定了LLM在生物医学领域的未来研究方向,包括保护数据隐私的联邦学习方法和整合可解释AI方法以提高LLM的透明度。
🔬 方法详解
问题定义:现有生物医学领域的大语言模型综述,要么侧重于特定应用,要么关注模型架构本身,缺乏一个全面、整合的分析,无法有效指导实际应用。此外,生物医学数据具有敏感性,对模型的可靠性和伦理要求极高,现有方法难以满足这些需求。
核心思路:本论文的核心思路是通过对大量文献的系统性回顾和分析,全面梳理生物医学领域大语言模型的现状、应用、挑战和未来发展方向。重点关注LLM在实际生物医学场景中的应用,并深入探讨如何解决数据隐私、模型可解释性和伦理等关键问题。
技术框架:该综述的技术框架主要包括以下几个阶段:1) 文献收集:从PubMed、Web of Science和arXiv等数据库收集相关文献;2) 文献筛选:根据预定义的标准筛选出484篇相关性高的文献;3) 内容分析:对筛选出的文献进行深入阅读和分析,提取关键信息;4) 归纳总结:对分析结果进行归纳总结,形成对LLM在生物医学领域现状、应用、挑战和未来方向的全面认识。
关键创新:本综述的创新之处在于其全面性和实用性。它不仅涵盖了LLM在生物医学领域的各种应用,还深入探讨了实际应用中面临的挑战,并提出了具有针对性的解决方案和未来研究方向。与现有综述相比,本综述更注重LLM在实际生物医学环境中的应用,并对数据隐私、模型可解释性和伦理等关键问题进行了深入分析。
关键设计:本综述的关键设计在于其系统性的文献回顾和分析方法。通过对大量文献的深入阅读和分析,提取关键信息,并进行归纳总结,从而形成对LLM在生物医学领域现状、应用、挑战和未来方向的全面认识。此外,本综述还特别关注LLM在实际生物医学环境中的应用,并对数据隐私、模型可解释性和伦理等关键问题进行了深入分析。
🖼️ 关键图片

📊 实验亮点
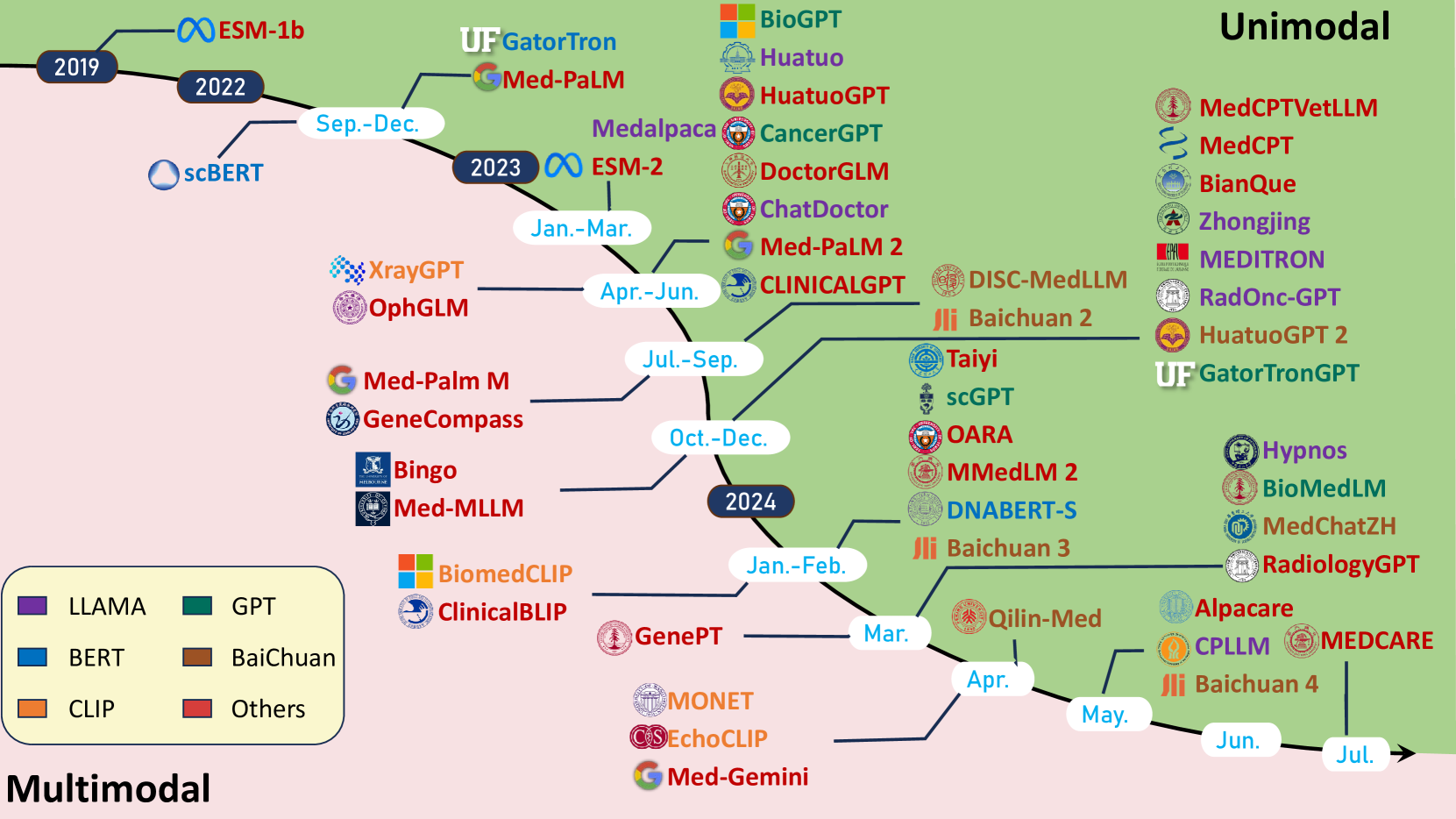
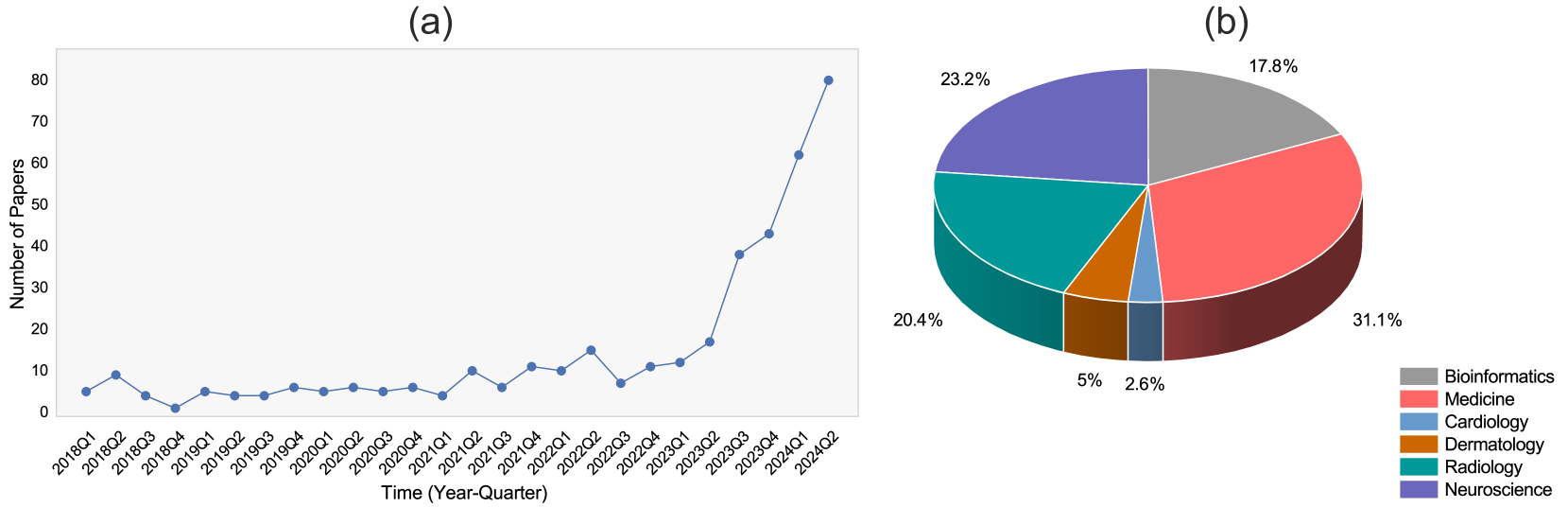
该综述分析了484篇相关文献,总结了LLM在生物医学领域的应用,包括零样本学习在诊断辅助、药物发现和个性化医疗等方面的应用。同时,强调了微调方法在医学问答和生物医学文献处理中的重要性。此外,该综述还突出了数据隐私、模型可解释性和伦理等关键挑战,并提出了联邦学习和可解释AI等潜在解决方案。
🎯 应用场景
该研究成果可应用于指导生物医学领域的研究人员和从业者更好地理解和应用大语言模型。它有助于推动LLM在诊断辅助、药物发现、个性化医疗等领域的应用,并促进相关技术的伦理和安全发展。此外,该综述还为未来的研究提供了方向,例如联邦学习和可解释AI在生物医学LLM中的应用。
📄 摘要(原文)
Recent breakthroughs in large language models (LLMs) offer unprecedented natural language understanding and generation capabilities. However, existing surveys on LLMs in biomedicine often focus on specific applications or model architectures, lacking a comprehensive analysis that integrates the latest advancements across various biomedical domains. This review, based on an analysis of 484 publications sourced from databases including PubMed, Web of Science, and arXiv, provides an in-depth examination of the current landscape, applications, challenges, and prospects of LLMs in biomedicine, distinguishing itself by focusing on the practical implications of these models in real-world biomedical contexts. Firstly, we explore the capabilities of LLMs in zero-shot learning across a broad spectrum of biomedical tasks, including diagnostic assistance, drug discovery, and personalized medicine, among others, with insights drawn from 137 key studies. Then, we discuss adaptation strategies of LLMs, including fine-tuning methods for both uni-modal and multi-modal LLMs to enhance their performance in specialized biomedical contexts where zero-shot fails to achieve, such as medical question answering and efficient processing of biomedical literature. Finally, we discuss the challenges that LLMs face in the biomedicine domain including data privacy concerns, limited model interpretability, issues with dataset quality, and ethics due to the sensitive nature of biomedical data, the need for highly reliable model outputs, and the ethical implications of deploying AI in healthcare. To address these challenges, we also identify future research directions of LLM in biomedicine including federated learning methods to preserve data privacy and integrating explainable AI methodologies to enhance the transparency of LLMs.