LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
作者: Fnu Mohbat, Mohammed J. Zaki
分类: cs.CL, cs.LG
发布日期: 2024-08-29
💡 一句话要点
提出LLaVA-Chef,一种用于生成食物菜谱的多模态生成模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 菜谱生成 大型语言模型 领域自适应 视觉语言模型
📋 核心要点
- 现有大型语言模型在菜谱生成方面表现出潜力,但缺乏领域特定训练,限制了其在食物领域的有效应用。
- LLaVA-Chef通过多阶段训练方法,包括视觉嵌入映射优化、领域自适应微调和多样化提示学习,提升菜谱生成能力。
- 实验结果表明,LLaVA-Chef在菜谱生成方面优于预训练LLMs和现有方法,能够生成更详细、成分更精确的菜谱。
📝 摘要(中文)
在全球化背景下,在线菜谱分享迅速发展,对理解和生成食物菜谱的研究也显著增加。GPT-2和LLaVA等大型语言模型(LLMs)的最新进展为自然语言处理(NLP)方法深入研究食物相关任务(包括成分识别和综合菜谱生成)铺平了道路。尽管LLMs具有令人印象深刻的性能和多模态适应性,但领域特定的训练对于其有效应用仍然至关重要。本文评估了现有LLMs在菜谱生成方面的表现,并提出了LLaVA-Chef,这是一种在多样化菜谱提示的精选数据集上以多阶段方法训练的新模型。首先,我们改进了视觉食物图像嵌入到语言空间的映射。其次,我们通过在相关的菜谱数据上进行微调,使LLaVA适应食物领域。第三,我们利用多样化的提示来增强模型对菜谱的理解。最后,我们通过使用自定义损失函数惩罚模型来提高生成菜谱的语言质量。LLaVA-Chef在预训练LLMs和先前工作的基础上展示了令人印象深刻的改进。详细的定性分析表明,与现有方法相比,LLaVA-Chef生成了更详细的菜谱,并精确地提到了成分。
🔬 方法详解
问题定义:论文旨在解决现有大型语言模型在食物菜谱生成任务中,由于缺乏领域特定知识而导致的生成质量不高的问题。现有方法生成的菜谱可能不够详细,成分描述不够精确,难以满足用户需求。
核心思路:论文的核心思路是通过多阶段训练,将视觉信息与语言信息更好地结合,并使模型更好地理解食物领域的知识。通过领域自适应微调,使模型能够生成更符合食物领域特点的菜谱。
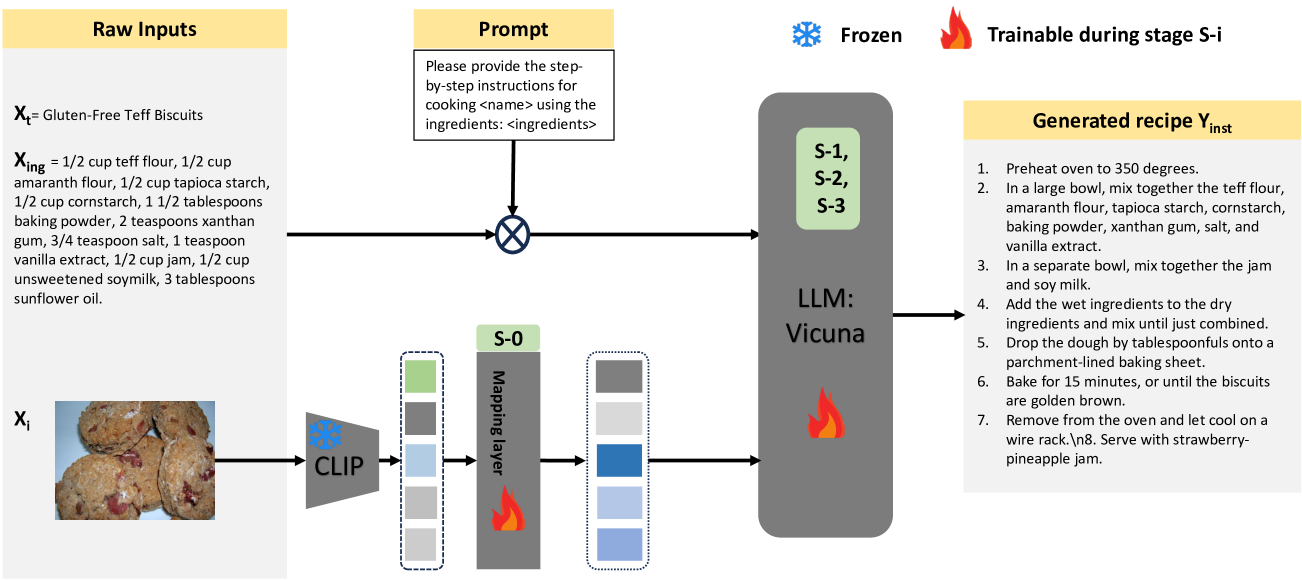
技术框架:LLaVA-Chef的整体框架包括以下几个阶段:1) 视觉食物图像嵌入到语言空间的映射优化;2) LLaVA模型在食物领域数据集上的微调;3) 利用多样化的提示来增强模型对菜谱的理解;4) 使用自定义损失函数来提高生成菜谱的语言质量。
关键创新:论文的关键创新在于多阶段训练方法,特别是视觉嵌入映射优化和领域自适应微调。通过这些方法,模型能够更好地理解食物图像和菜谱文本之间的关系,并生成更符合食物领域特点的菜谱。此外,自定义损失函数的设计也有助于提高生成菜谱的语言质量。
关键设计:论文中,视觉嵌入映射优化可能涉及对比学习或相似的技术,以确保视觉特征与语言特征在嵌入空间中对齐。领域自适应微调可能采用低秩适应(LoRA)等参数高效微调方法,以避免灾难性遗忘。自定义损失函数可能包含惩罚不流畅或不相关的词语的项,以提高生成文本的质量。具体参数设置和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
论文通过定性分析表明,LLaVA-Chef生成的菜谱比现有方法更详细,成分描述更精确。虽然论文中没有提供具体的量化指标,但定性分析结果表明LLaVA-Chef在菜谱生成质量方面取得了显著提升。与预训练LLMs相比,LLaVA-Chef在食物领域的表现得到了显著改善。
🎯 应用场景
该研究成果可应用于智能菜谱推荐系统、自动菜谱生成工具、食品图像识别与描述等领域。通过生成高质量的菜谱,可以帮助用户更好地了解食物的制作方法,提高烹饪效率,并促进健康饮食。未来,该技术还可应用于个性化菜谱定制、营养分析等方面。
📄 摘要(原文)
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.