LLMs vs Established Text Augmentation Techniques for Classification: When do the Benefits Outweight the Costs?
作者: Jan Cegin, Jakub Simko, Peter Brusilovsky
分类: cs.CL
发布日期: 2024-08-29
备注: 20 pages
💡 一句话要点
对比LLM与传统文本增强技术:探究分类任务中LLM的性价比优势
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本增强 大型语言模型 分类任务 成本效益分析 数据增强 机器学习 自然语言处理
📋 核心要点
- 现有文本分类的数据增强方法存在局限性,难以充分利用大规模预训练语言模型的生成能力。
- 该研究对比了LLM和传统文本增强方法在分类任务中的效果,并进行了成本效益分析。
- 实验结果表明,LLM并非总是优于传统方法,仅在少量种子样本情况下具有优势,且性价比不高。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于数据增强任务,通过LLM对文本样本进行释义,然后用于分类器的微调。然而,目前缺乏研究来证实LLM相对于更成熟的增强方法具有明显的性价比优势。为了研究基于LLM的增强方法在何时以及是否具有优势,我们将最新的LLM增强方法与已建立的方法在6个数据集、3个分类器和2个微调方法上进行了比较。我们还改变了种子数量和收集的样本,以更好地探索下游模型的准确性空间。最后,我们进行了成本效益分析,结果表明,只有在使用非常少的种子时,基于LLM的方法才值得部署。此外,在许多情况下,已建立的方法可以获得相似或更好的模型精度。
🔬 方法详解
问题定义:论文旨在解决文本分类任务中,如何选择合适的数据增强方法的问题。现有方法,如简单的同义词替换或回译,可能无法生成高质量的增强样本,而直接使用LLM进行数据增强的成本较高,且效果并不总是优于传统方法。因此,需要研究LLM在数据增强方面的性价比,明确其适用场景。
核心思路:论文的核心思路是通过实验对比LLM和传统文本增强方法在不同数据集、分类器和微调方法下的性能表现,并结合成本分析,评估LLM在数据增强方面的实际价值。通过改变种子样本数量,探索LLM在不同数据量下的表现。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择数据集和分类器;2) 应用不同的文本增强方法,包括LLM和传统方法;3) 使用增强后的数据对分类器进行微调;4) 评估分类器在测试集上的性能;5) 进行成本效益分析,比较不同方法的计算成本和性能提升。
关键创新:该研究的关键创新在于对LLM在数据增强方面的性价比进行了全面的评估。以往的研究主要关注LLM在生成高质量文本方面的能力,而忽略了其计算成本。该研究通过实验对比,发现LLM并非总是优于传统方法,且在大多数情况下,其性价比并不高。
关键设计:实验中,作者选择了6个数据集、3个分类器和2个微调方法,以保证实验结果的泛化性。同时,作者改变了种子样本的数量,以探索LLM在不同数据量下的表现。成本效益分析主要考虑了计算时间和硬件资源消耗。
🖼️ 关键图片


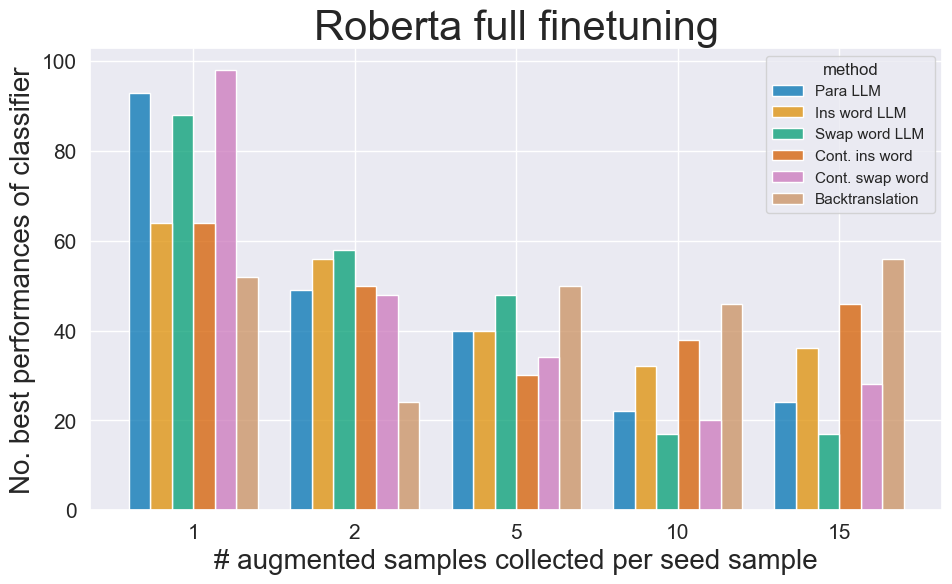
📊 实验亮点
实验结果表明,在大多数情况下,传统的文本增强方法可以获得与LLM相似或更好的模型精度。只有在使用非常少的种子样本时,基于LLM的方法才具有优势。成本效益分析表明,LLM的计算成本较高,性价比并不总是优于传统方法。例如,在某些数据集上,简单的同义词替换方法可以获得与LLM相当的性能,但计算成本却低得多。
🎯 应用场景
该研究成果可应用于文本分类任务的数据增强策略选择。在资源有限的情况下,可以优先考虑传统的文本增强方法。当需要处理少量种子样本时,可以考虑使用LLM进行数据增强,但需要仔细评估其成本效益。该研究有助于更好地理解LLM在数据增强方面的优势和局限性,从而更有效地利用LLM资源。
📄 摘要(原文)
The generative large language models (LLMs) are increasingly being used for data augmentation tasks, where text samples are LLM-paraphrased and then used for classifier fine-tuning. However, a research that would confirm a clear cost-benefit advantage of LLMs over more established augmentation methods is largely missing. To study if (and when) is the LLM-based augmentation advantageous, we compared the effects of recent LLM augmentation methods with established ones on 6 datasets, 3 classifiers and 2 fine-tuning methods. We also varied the number of seeds and collected samples to better explore the downstream model accuracy space. Finally, we performed a cost-benefit analysis and show that LLM-based methods are worthy of deployment only when very small number of seeds is used. Moreover, in many cases, established methods lead to similar or better model accuracies.