The Unreasonable Ineffectiveness of Nucleus Sampling on Mitigating Text Memorization
作者: Luka Borec, Philipp Sadler, David Schlangen
分类: cs.CL
发布日期: 2024-08-29
备注: 9 pages, Accepted at INLG 2024 (International Natural Language Generation Conference)
💡 一句话要点
分析Nucleus Sampling对缓解LLM文本记忆化效果不佳的现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本记忆化 Nucleus Sampling 大型语言模型 GPT-Neo 随机解码
📋 核心要点
- 大型语言模型存在文本记忆化问题,Nucleus Sampling等随机解码方法被寄希望于缓解此问题。
- 该研究假设Nucleus Sampling通过选择记忆序列外的token来减少记忆化,并设计实验进行验证。
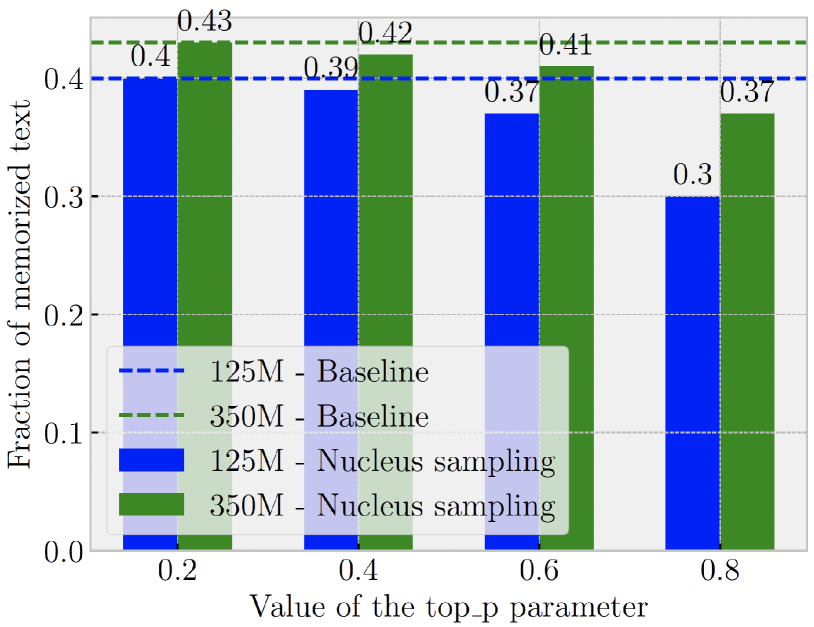
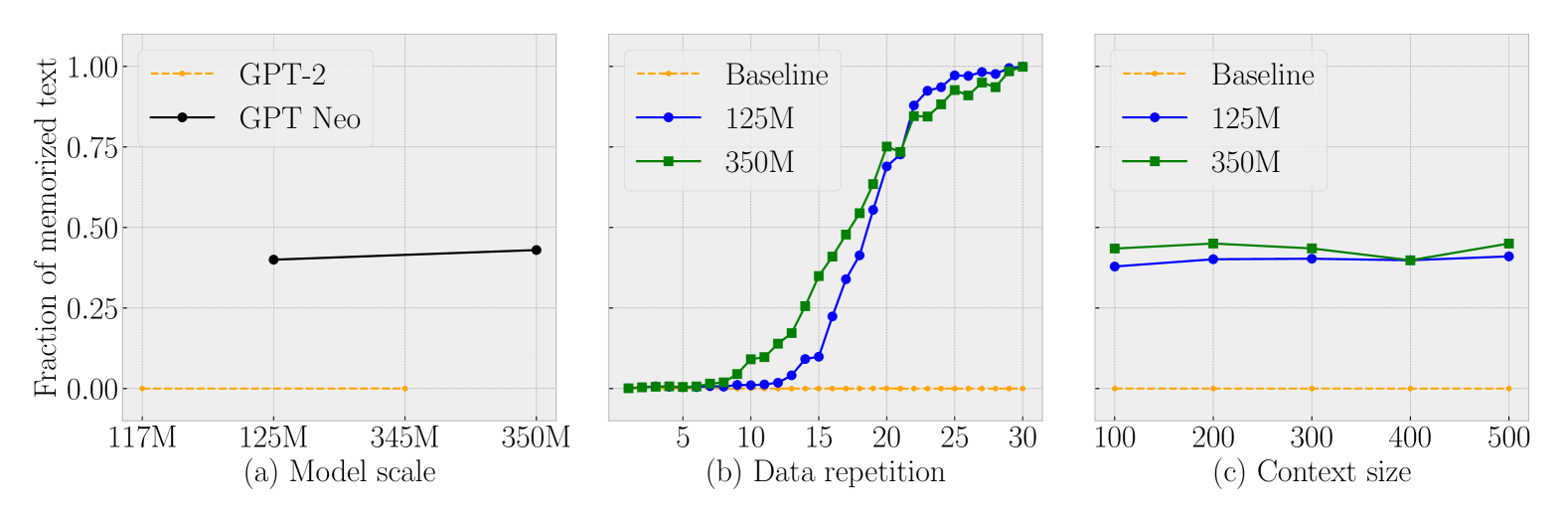
- 实验结果表明,增加Nucleus Size对减少记忆化效果有限,且模型存在“软”记忆现象。
📝 摘要(中文)
本文分析了大型语言模型(LLM)在使用Nucleus Sampling时出现的文本记忆化行为。通常,像Nucleus Sampling这样的随机解码方法被用于克服基于最大化的解码技术中常见的单调和重复文本生成问题。我们假设Nucleus Sampling也可能减少记忆化模式的出现,因为它可能导致选择记忆序列之外的token。为了验证这个假设,我们创建了一个诊断数据集,其中包含已知分布的重复数据,从而使我们能够控制训练数据某些部分被记忆的可能性。对两个在这个数据集上微调的GPT-Neo模型的分析表明:(i)增加Nucleus Size仅适度地减少了记忆化;(ii)即使模型没有进行“硬”记忆——即逐字复制训练样本——它们仍然可能表现出“软”记忆,即生成与训练数据相似但不完全相同的输出。
🔬 方法详解
问题定义:论文旨在研究Nucleus Sampling在缓解大型语言模型(LLM)文本记忆化方面的有效性。现有基于最大化的解码方法容易产生单调和重复的文本,而Nucleus Sampling等随机解码方法被认为可能减少记忆化,但其效果尚不明确。
核心思路:论文的核心思路是通过构建一个包含已知重复数据分布的诊断数据集,来控制模型记忆训练数据某些部分的可能性,从而量化分析Nucleus Sampling对记忆化的影响。通过分析模型在生成文本时对这些重复数据的复现程度,评估Nucleus Sampling的有效性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建包含重复数据的诊断数据集;2) 使用该数据集微调GPT-Neo模型;3) 使用不同大小的Nucleus Sampling进行文本生成;4) 分析生成文本中重复数据的复现情况,区分“硬”记忆和“软”记忆。
关键创新:该研究的关键创新在于构建了一个可控的诊断数据集,能够更精确地评估模型对特定训练数据的记忆程度。此外,该研究区分了“硬”记忆(逐字复制)和“软”记忆(语义相似),更全面地分析了模型的记忆行为。
关键设计:诊断数据集的设计是关键。论文控制了数据集中重复样本的频率和位置,以便更好地分析模型对不同类型重复数据的记忆情况。实验中,使用了不同大小的Nucleus Size (p值) 来观察其对记忆化的影响。同时,定义了“硬”记忆和“软”记忆的评估指标,以便更细致地分析模型的记忆行为。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增加Nucleus Size对减少记忆化的效果并不显著。即使模型没有完全复制训练样本(“硬”记忆),仍然会生成与训练数据相似的文本(“软”记忆)。这表明Nucleus Sampling在缓解文本记忆化方面存在局限性,需要进一步研究更有效的策略。
🎯 应用场景
该研究成果可应用于提升大型语言模型生成文本的质量和安全性。通过深入理解Nucleus Sampling等解码方法对记忆化的影响,可以设计更有效的训练策略和解码算法,减少模型对训练数据的过度依赖,从而避免生成包含敏感信息或不当内容的文本。这对于构建更可靠、更安全的AI系统具有重要意义。
📄 摘要(原文)
This work analyses the text memorization behavior of large language models (LLMs) when subjected to nucleus sampling. Stochastic decoding methods like nucleus sampling are typically applied to overcome issues such as monotonous and repetitive text generation, which are often observed with maximization-based decoding techniques. We hypothesize that nucleus sampling might also reduce the occurrence of memorization patterns, because it could lead to the selection of tokens outside the memorized sequence. To test this hypothesis we create a diagnostic dataset with a known distribution of duplicates that gives us some control over the likelihood of memorization of certain parts of the training data. Our analysis of two GPT-Neo models fine-tuned on this dataset interestingly shows that (i) an increase of the nucleus size reduces memorization only modestly, and (ii) even when models do not engage in "hard" memorization -- a verbatim reproduction of training samples -- they may still display "soft" memorization whereby they generate outputs that echo the training data but without a complete one-by-one resemblance.