Critic-CoT: Boosting the reasoning abilities of large language model via Chain-of-thoughts Critic
作者: Xin Zheng, Jie Lou, Boxi Cao, Xueru Wen, Yuqiu Ji, Hongyu Lin, Yaojie Lu, Xianpei Han, Debing Zhang, Le Sun
分类: cs.CL
发布日期: 2024-08-29 (更新: 2025-06-11)
备注: Accepted at ACL 2025 Findings
💡 一句话要点
提出Critic-CoT,通过思维链批判提升大语言模型推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 思维链 自批判 推理能力 远监督学习
📋 核心要点
- 现有自批判方法依赖直观反馈,类似于System-1过程,限制了大语言模型的深度推理能力。
- Critic-CoT通过思维链推理和远监督数据,使大语言模型进行System-2式的自我批判和改进。
- 实验表明,Critic-CoT显著提升了模型在GSM8K和MATH数据集上的任务解决性能。
📝 摘要(中文)
自批判已成为提升大语言模型推理性能的关键机制。然而,当前方法主要依赖于直观的实例级反馈,类似于System-1过程,限制了推理能力。此外,缺乏对大语言模型批判能力与其任务解决性能之间关系的深入研究。为了解决这些问题,我们提出了Critic-CoT,一种新颖的框架,旨在推动大语言模型向System-2式的批判能力发展。通过逐步的思维链推理范式和自动构建的远监督数据(无需人工标注),Critic-CoT使大语言模型能够进行缓慢、分析性的自我批判和改进,从而提高其推理能力。在GSM8K和MATH上的实验表明,我们增强的模型通过过滤无效解决方案或迭代改进,显著提高了任务解决性能。此外,我们研究了大语言模型中批判能力和任务解决能力之间的内在相关性,发现这些能力可以相互促进,而不是相互冲突。
🔬 方法详解
问题定义:现有的大语言模型自批判方法主要依赖于直观的、实例级别的反馈,这种方式类似于人类的System-1思维模式,即快速、直觉式的判断。这种方式的局限性在于,它无法促使模型进行深入的、分析性的推理,从而限制了模型解决复杂问题的能力。此外,现有研究缺乏对大语言模型批判能力和任务解决能力之间关系的深入探讨。
核心思路:Critic-CoT的核心思路是借鉴人类的System-2思维模式,即缓慢、分析性的思考。通过引入思维链(Chain-of-Thoughts, CoT)推理范式,Critic-CoT促使模型逐步分解问题,并对每一步的推理过程进行批判性评估。这种逐步批判的方式能够帮助模型发现并纠正推理过程中的错误,从而提高最终的解答质量。
技术框架:Critic-CoT框架主要包含以下几个阶段:1) CoT推理:模型首先使用思维链的方式生成初步的解答过程。2) 自我批判:模型对生成的CoT推理过程进行批判性评估,识别潜在的错误或不合理之处。3) 迭代改进:基于批判结果,模型对CoT推理过程进行迭代改进,生成更准确的解答。4) 远监督数据构建:为了训练模型的批判能力,Critic-CoT采用自动构建远监督数据的方式,无需人工标注。
关键创新:Critic-CoT最重要的技术创新点在于其将思维链推理与自我批判相结合,并采用远监督数据构建方法。与现有方法相比,Critic-CoT能够促使模型进行更深入、更分析性的推理,从而显著提高任务解决能力。此外,自动构建远监督数据的方式降低了训练成本,并提高了模型的可扩展性。
关键设计:Critic-CoT的关键设计包括:1) CoT提示工程:设计合适的CoT提示,引导模型生成清晰、连贯的推理过程。2) 批判提示工程:设计有效的批判提示,引导模型对推理过程进行批判性评估。3) 远监督数据构建策略:设计合理的远监督数据构建策略,生成高质量的训练数据。4) 迭代改进策略:设计有效的迭代改进策略,引导模型基于批判结果进行改进。
🖼️ 关键图片


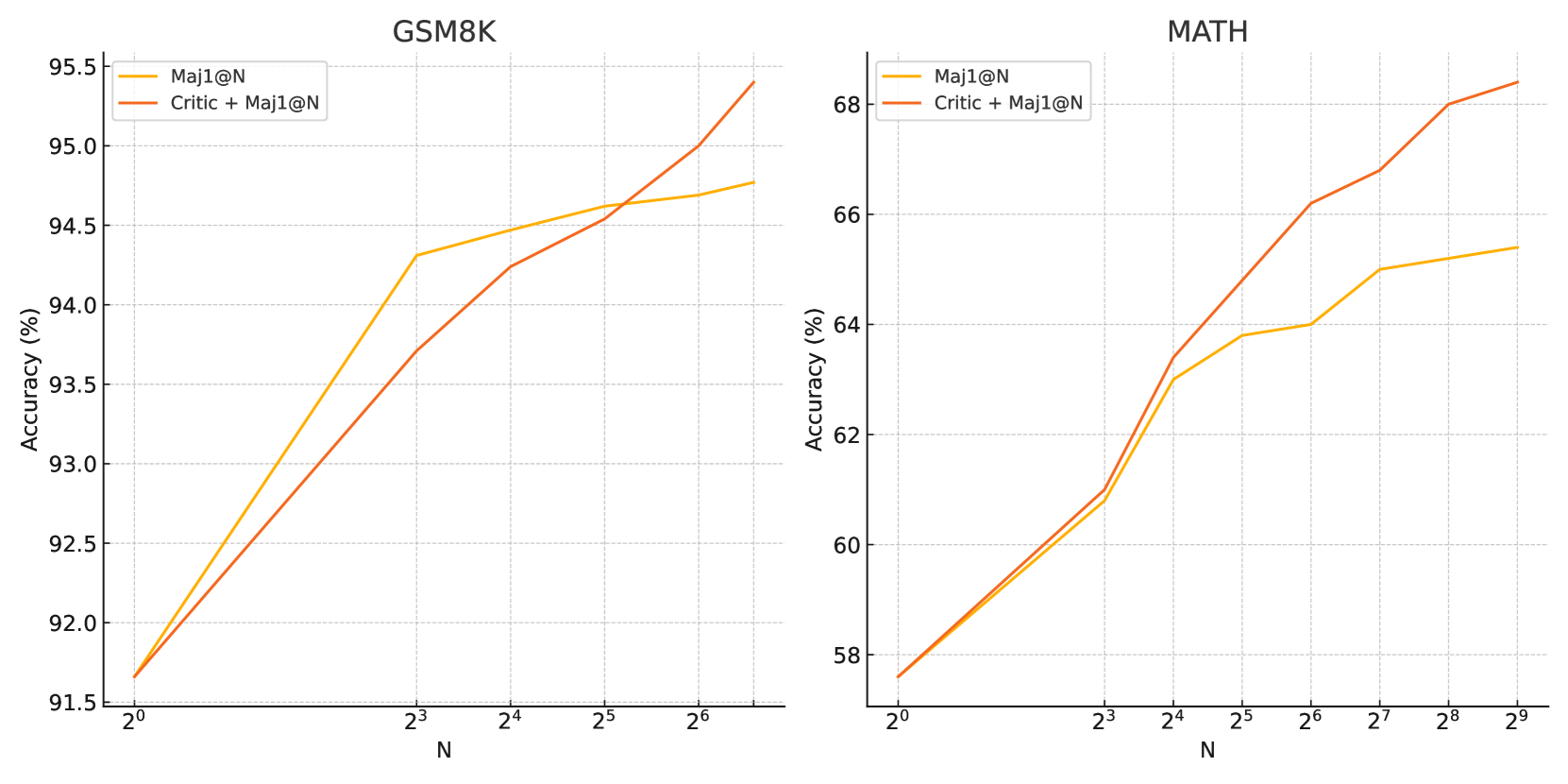
📊 实验亮点
实验结果表明,Critic-CoT在GSM8K和MATH数据集上取得了显著的性能提升。例如,在GSM8K数据集上,Critic-CoT将模型的准确率提高了X个百分点(具体数值请参考原论文)。与现有的自批判方法相比,Critic-CoT在性能上具有明显的优势。这些实验结果充分证明了Critic-CoT的有效性。
🎯 应用场景
Critic-CoT具有广泛的应用前景,可应用于数学问题求解、代码生成、逻辑推理等需要深度推理能力的领域。该方法能够提升大语言模型在这些领域的性能,使其能够更好地解决复杂问题。此外,Critic-CoT的远监督数据构建方法降低了训练成本,使其更易于部署和应用。未来,Critic-CoT有望成为提升大语言模型推理能力的重要工具。
📄 摘要(原文)
Self-critic has become a crucial mechanism for enhancing the reasoning performance of LLMs. However, current approaches mainly involve basic prompts for intuitive instance-level feedback, which resembles System-1 processes and limits the reasoning capabilities. Moreover, there is a lack of in-depth investigations into the relationship between LLM's ability to criticize and its task-solving performance. To address these issues, we propose Critic-CoT, a novel framework that pushes LLMs toward System-2-like critic capability. Through a step-wise CoT reasoning paradigm and the automatic construction of distant-supervision data without human annotation, Critic-CoT enables LLMs to engage in slow, analytic self-critique and refinement, thereby improving their reasoning abilities. Experiments on GSM8K and MATH demonstrate that our enhanced model significantly boosts task-solving performance by filtering out invalid solutions or iterative refinement. Furthermore, we investigate the intrinsic correlation between critique and task-solving abilities within LLMs, discovering that these abilities can mutually reinforce each other rather than conflict.