Bias in LLMs as Annotators: The Effect of Party Cues on Labelling Decision by Large Language Models
作者: Sebastian Vallejo Vera, Hunter Driggers
分类: cs.CL, cs.LG
发布日期: 2024-08-28
💡 一句话要点
研究表明:大型语言模型作为标注者会受到政治倾向信息的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治偏见 标注任务 政党线索 公平性 可靠性 自然语言处理
📋 核心要点
- 现有研究表明人类标注者存在偏见,而大型语言模型在标注任务中是否也存在类似偏见是待研究的核心问题。
- 该研究的核心思想是探究LLMs是否会利用政治信息(如政党线索)来判断政治声明的极性,从而揭示其潜在的偏见。
- 实验结果表明,LLMs在判断政治声明时会受到政党线索的影响,甚至在面对中间派政党时也会表现出显著的偏见。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)作为标注者时是否存在与人类相似的偏见。通过复现Ennser-Jedenastik和Meyer(2018)的实验,我们发现LLMs会利用政治信息,特别是政党线索,来判断政治声明。LLMs不仅会根据政党线索来判断声明是正面、负面还是中性,还会反映其训练数据中人类产生的偏见。与人类只在面对极端政党的声明时才表现出偏见不同,LLMs即使在面对中左和中右政党的声明时也表现出显著的偏见。结论部分讨论了这些发现的意义。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在作为标注者时,是否会受到政治倾向信息的影响,从而产生偏见。现有方法缺乏对LLMs在政治立场判断上偏见的系统性评估,而人类标注者已知的偏见可能会在LLMs中被放大或以新的形式展现。
核心思路:论文的核心思路是复现并扩展一项针对人类标注者的实验,该实验考察了政党线索对政治声明极性判断的影响。通过将LLMs作为标注者,并分析其对不同政党声明的判断结果,来评估LLMs是否存在政治偏见。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集政治声明数据,并标注其所属政党;2) 使用LLMs对这些声明进行极性标注(正面、负面、中性);3) 分析LLMs的标注结果,考察其是否受到政党线索的影响;4) 将LLMs的标注结果与人类标注者的结果进行比较,分析LLMs偏见的特点。
关键创新:该研究的关键创新在于将LLMs作为标注者,并系统性地评估其在政治立场判断上的偏见。与以往研究主要关注LLMs在生成文本时的偏见不同,该研究关注LLMs在理解和判断文本时的偏见,这对于确保LLMs在下游任务中的公平性和可靠性至关重要。
关键设计:研究的关键设计包括:1) 精心选择政治声明数据,确保其涵盖不同政党和不同政治立场;2) 使用明确的提示语(prompt)引导LLMs进行极性标注,避免歧义;3) 采用统计方法分析LLMs的标注结果,量化其偏见程度;4) 将LLMs的标注结果与人类标注者的结果进行对比,揭示LLMs偏见的独特性。
🖼️ 关键图片
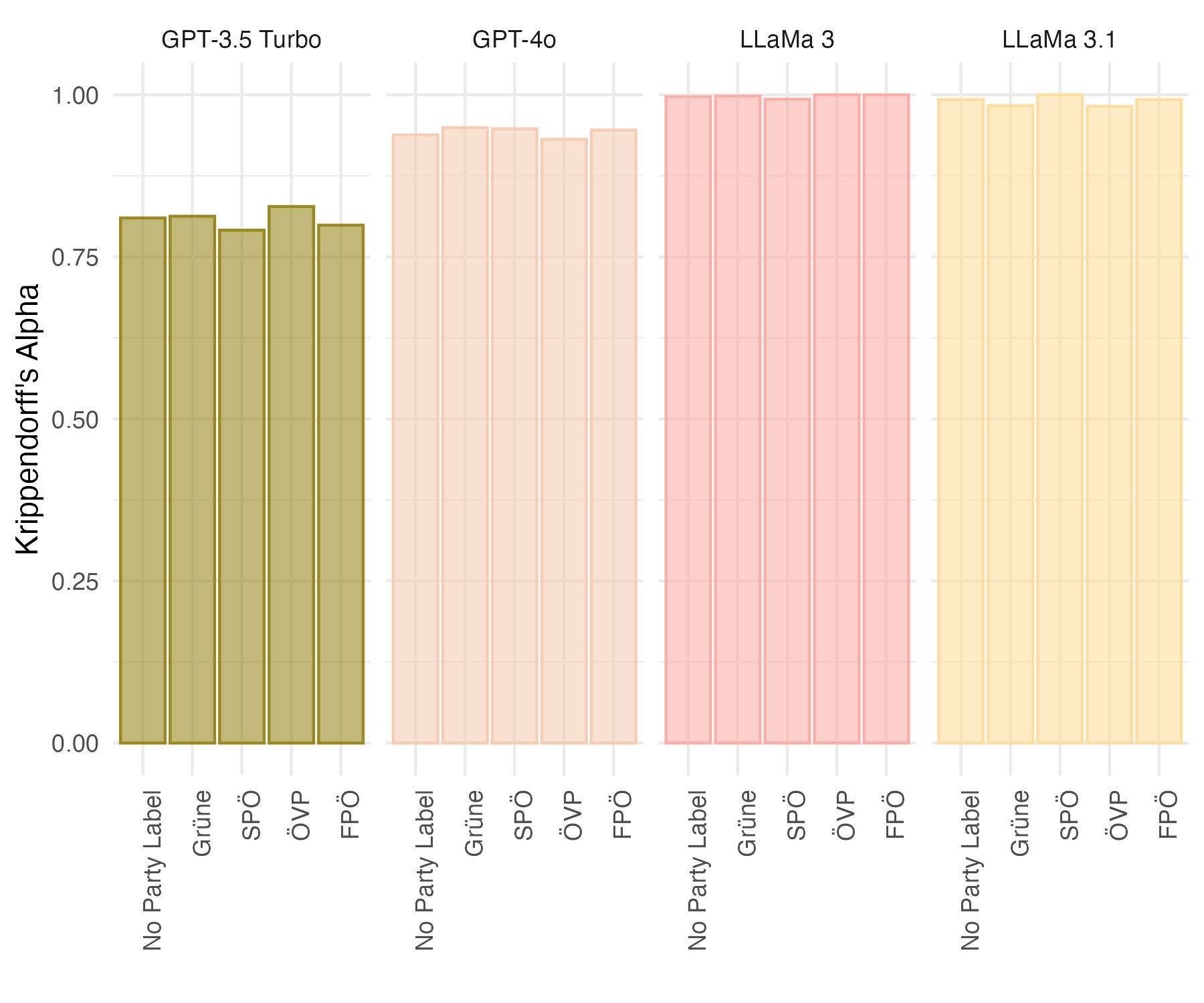
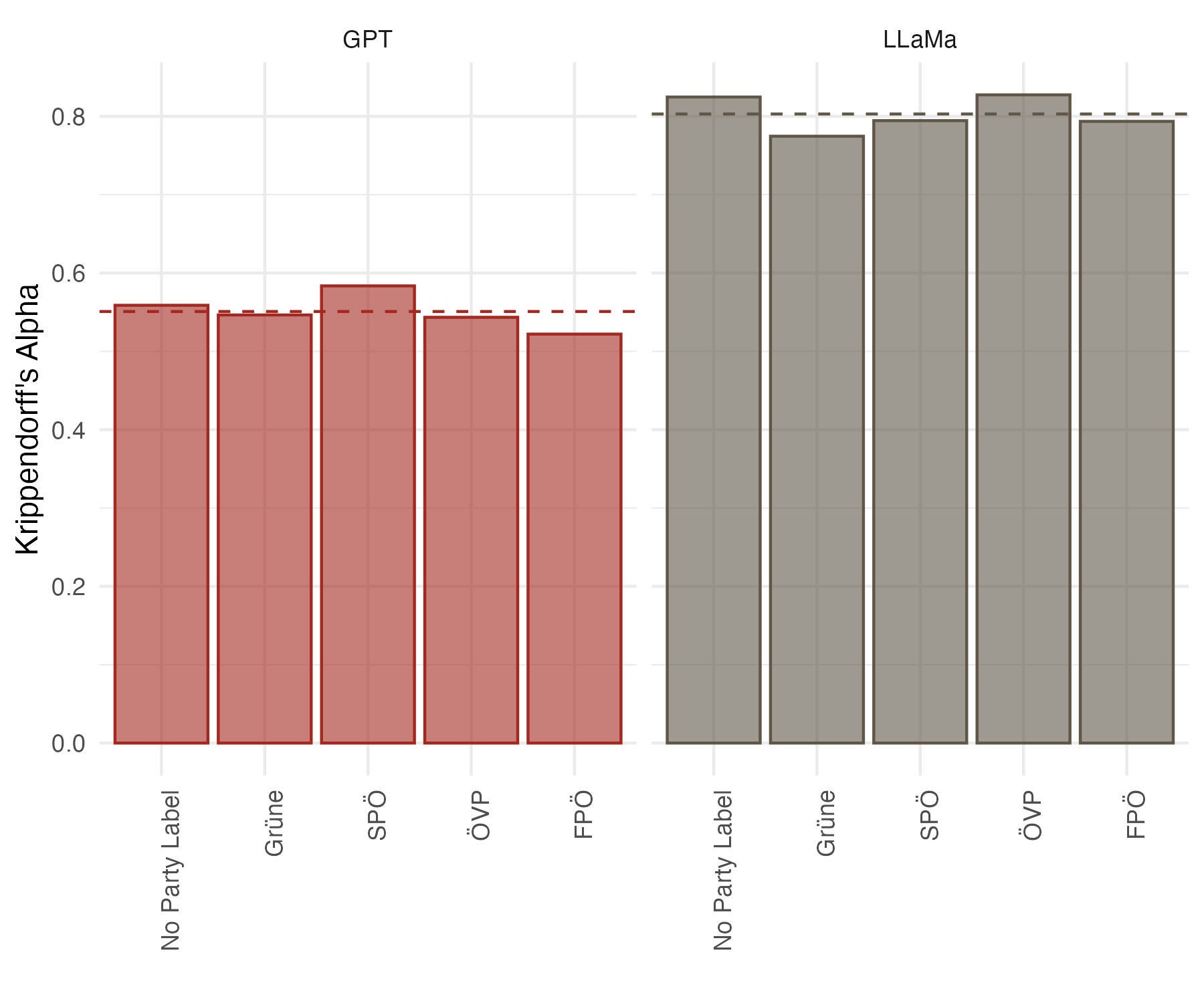
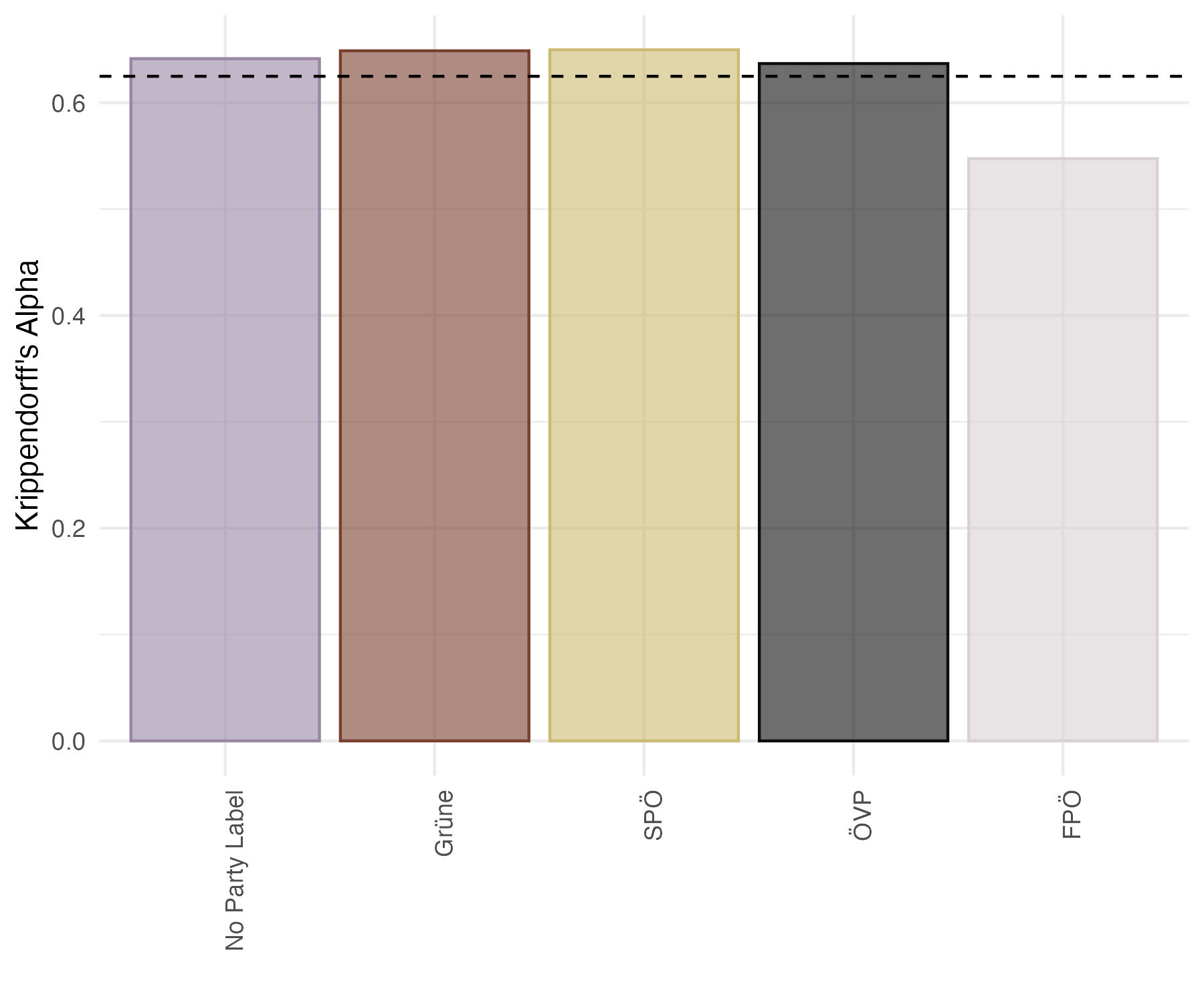
📊 实验亮点
实验结果表明,LLMs在判断政治声明时会受到政党线索的影响,即使是来自中间派政党的声明也会受到影响。与人类相比,LLMs的偏见更加普遍。这表明LLMs不仅会学习训练数据中的偏见,还可能放大这些偏见。该研究量化了LLMs的政治偏见程度,并揭示了其与人类偏见的差异。
🎯 应用场景
该研究的潜在应用领域包括:提高LLMs在政治相关任务中的公平性和可靠性,例如政治新闻分析、舆情监控等。研究结果可以帮助开发者设计更有效的去偏见方法,减少LLMs在政治领域的误导性信息传播。此外,该研究也为评估其他类型LLMs偏见提供了参考。
📄 摘要(原文)
Human coders are biased. We test similar biases in Large Language Models (LLMs) as annotators. By replicating an experiment run by Ennser-Jedenastik and Meyer (2018), we find evidence that LLMs use political information, and specifically party cues, to judge political statements. Not only do LLMs use relevant information to contextualize whether a statement is positive, negative, or neutral based on the party cue, they also reflect the biases of the human-generated data upon which they have been trained. We also find that unlike humans, who are only biased when faced with statements from extreme parties, LLMs exhibit significant bias even when prompted with statements from center-left and center-right parties. The implications of our findings are discussed in the conclusion.