Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
作者: Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu
分类: cs.CL
发布日期: 2024-08-28
备注: 20 pages
💡 一句话要点
提出指令感知上下文压缩方法,提升大语言模型效率与效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文压缩 指令感知 检索增强 知识检索
📋 核心要点
- 现有检索增强的大语言模型易受检索到的不相关上下文干扰,导致性能下降、延迟增加和成本上升。
- 提出指令感知上下文压缩方法,通过过滤掉信息量较少的内容,提升LLM的效率和效果。
- 实验表明,该方法在显著降低内存消耗和生成延迟的同时,保持了与使用完整上下文相当的性能水平。
📝 摘要(中文)
大型语言模型(LLM)因其在各种任务中的卓越表现而备受关注。然而,为了减轻幻觉问题,LLM通常采用检索增强管道,为其提供丰富的外部知识和上下文。然而,挑战来自于检索器检索到的不准确和粗粒度的上下文。向LLM提供不相关的上下文可能导致更差的响应、增加的推理延迟和更高的成本。本文介绍了一种名为指令感知上下文压缩的方法,该方法过滤掉信息量较少的内容,从而加速和增强LLM的使用。实验结果表明,指令感知上下文压缩显著降低了内存消耗,并最大限度地减少了生成延迟,同时保持了与使用完整上下文相当的性能水平。具体而言,我们在上下文相关成本方面实现了50%的降低,从而使推理内存使用量降低了5%,推理速度提高了2.2倍,而Rouge-1仅略微下降了0.047。这些发现表明,我们的方法在效率和性能之间取得了有效的平衡。
🔬 方法详解
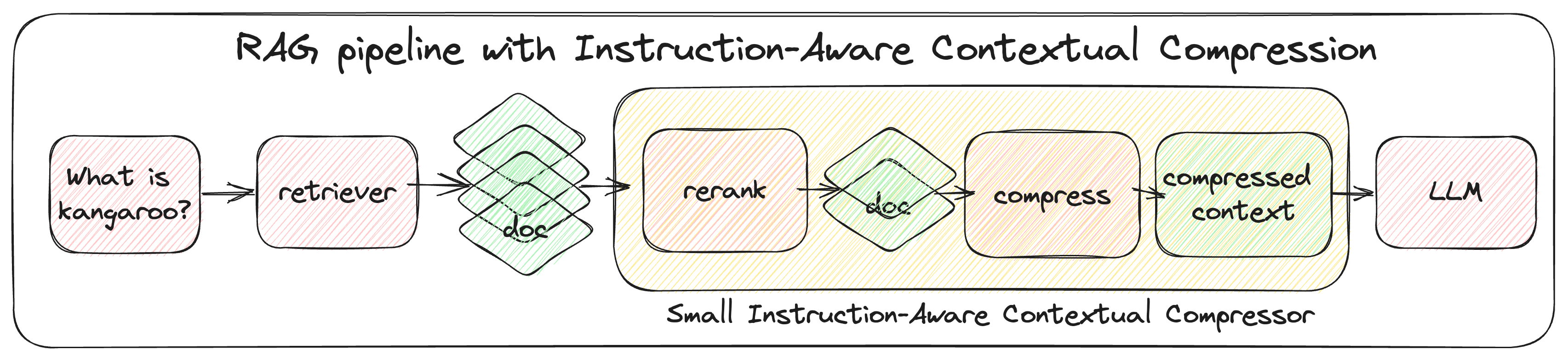
问题定义:现有的大语言模型在检索增强的场景下,容易受到检索到的噪声上下文的影响。这些噪声上下文不仅会增加计算成本和推理延迟,还可能降低模型的生成质量,甚至导致模型产生幻觉。因此,如何有效地过滤掉不相关的上下文信息,是提升大语言模型效率和效果的关键问题。
核心思路:论文的核心思路是利用指令信息来指导上下文压缩过程。通过分析指令,模型可以更好地理解用户的意图,从而更有针对性地选择和保留与指令相关的上下文信息,去除冗余和噪声信息。这种指令感知的压缩方法能够更有效地利用上下文,提升模型的性能。
技术框架:该方法主要包含以下几个阶段:1) 指令解析:分析用户输入的指令,提取关键信息,例如任务类型、目标实体等。2) 上下文检索:使用检索器从外部知识库中检索相关的上下文信息。3) 上下文压缩:利用指令解析的结果,对检索到的上下文进行压缩,过滤掉与指令无关或信息量较少的内容。4) LLM生成:将压缩后的上下文输入到大语言模型中,生成最终的输出。
关键创新:该方法最重要的技术创新点在于提出了指令感知的上下文压缩策略。与传统的上下文压缩方法不同,该方法充分利用了指令信息,使得上下文压缩过程更加智能化和高效。这种指令感知的压缩方法能够更好地保留与用户意图相关的上下文信息,从而提升模型的性能。
关键设计:具体的压缩策略可能包括以下几个方面:1) 基于指令的关键词提取:从指令中提取关键词,并根据关键词对上下文进行评分,保留评分较高的内容。2) 基于指令的语义相似度计算:计算上下文与指令之间的语义相似度,保留相似度较高的内容。3) 基于指令的上下文重排序:根据上下文与指令的相关性,对上下文进行重排序,将更重要的信息放在前面。
🖼️ 关键图片


📊 实验亮点
实验结果表明,指令感知上下文压缩方法在降低上下文相关成本方面实现了50%的降低,推理内存使用量降低了5%,推理速度提高了2.2倍,而Rouge-1指标仅略微下降了0.047。这些结果表明,该方法在效率和性能之间取得了良好的平衡,能够在显著提升推理速度的同时,保持较高的生成质量。
🎯 应用场景
该研究成果可广泛应用于各种需要检索增强的大语言模型应用场景,例如问答系统、对话系统、知识图谱推理等。通过减少上下文的冗余信息,可以显著降低计算成本和推理延迟,提升用户体验。未来,该方法还可以与其他上下文压缩技术相结合,进一步提升压缩效果和模型性能。
📄 摘要(原文)
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.