BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
作者: Guosheng Dong, Da Pan, Yiding Sun, Shusen Zhang, Zheng Liang, Xin Wu, Yanjun Shen, Fan Yang, Haoze Sun, Tianpeng Li, Mingan Lin, Jianhua Xu, Yufan Zhang, Xiaonan Nie, Lei Su, Bingning Wang, Wentao Zhang, Jiaxin Mao, Zenan Zhou, Weipeng Chen
分类: cs.CL, cs.AI
发布日期: 2024-08-27
备注: 19 pages, 6 figures
💡 一句话要点
BaichuanSEED:开源大规模数据处理流程,并验证其在7B LLM上的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据处理流程 开源 预训练 监督微调
📋 核心要点
- 现有LLM依赖于大规模数据集,但数据集构建细节通常是商业机密,阻碍了研究。
- 论文开源了数据处理流程,包括数据收集和重加权,用于预训练LLM。
- BaichuanSEED在3T tokens上预训练,无需特定下游任务优化,性能与商业模型相当。
📝 摘要(中文)
大型语言模型(LLM)的通用能力高度依赖于大规模预训练数据集的组成和选择,而这些数据集通常被各机构视为商业机密。为了缓解这个问题,本文开源了一个通用数据处理流程的细节,并通过引入一个具有竞争力的LLM基线来验证其有效性和潜力。具体来说,该数据处理流程包括广泛的数据收集以扩大规模,以及重新加权以提高质量。然后,使用该流程处理的3T tokens预训练了一个7B模型BaichuanSEED,没有任何刻意的下游任务相关优化,之后进行了一个简单但有效的监督微调阶段。BaichuanSEED在整个训练过程中表现出一致性和可预测性,并在综合基准测试中取得了与一些商业先进大型语言模型(如Qwen1.5和Llama3)相当的性能。本文还进行了一些启发式实验,以讨论进一步优化下游任务(如数学和编码)的潜力。
🔬 方法详解
问题定义:现有大型语言模型依赖于大规模预训练数据集,但这些数据集的构建细节通常被视为商业机密,这限制了学术界和小型研究机构在该领域的研究和发展。现有方法缺乏透明度,难以复现和改进,阻碍了LLM技术的普及和创新。
核心思路:论文的核心思路是开源一个通用的、可复用的数据处理流程,该流程包括大规模数据收集和数据质量重加权两个关键步骤。通过开源数据处理流程,降低了LLM研究的门槛,使得更多研究者可以参与到LLM的训练和优化中。
技术框架:该研究的技术框架主要包含两个阶段:数据处理阶段和模型训练阶段。数据处理阶段包括:1) 广泛的数据收集,旨在扩大数据集的规模;2) 数据重加权,旨在提高数据集的质量。模型训练阶段包括:1) 使用处理后的数据预训练一个7B参数的BaichuanSEED模型;2) 对预训练模型进行监督微调。
关键创新:该研究的关键创新在于开源了完整的数据处理流程,并验证了该流程在训练具有竞争力的LLM方面的有效性。与以往的研究相比,该研究更加注重数据处理的透明性和可复用性,而不是仅仅关注模型结构的创新。
关键设计:在数据处理阶段,论文可能采用了启发式规则或模型来对数据进行重加权,以提高数据质量。在模型训练阶段,BaichuanSEED模型采用了标准的Transformer架构,并使用了常见的优化算法和超参数设置。具体的重加权策略和超参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
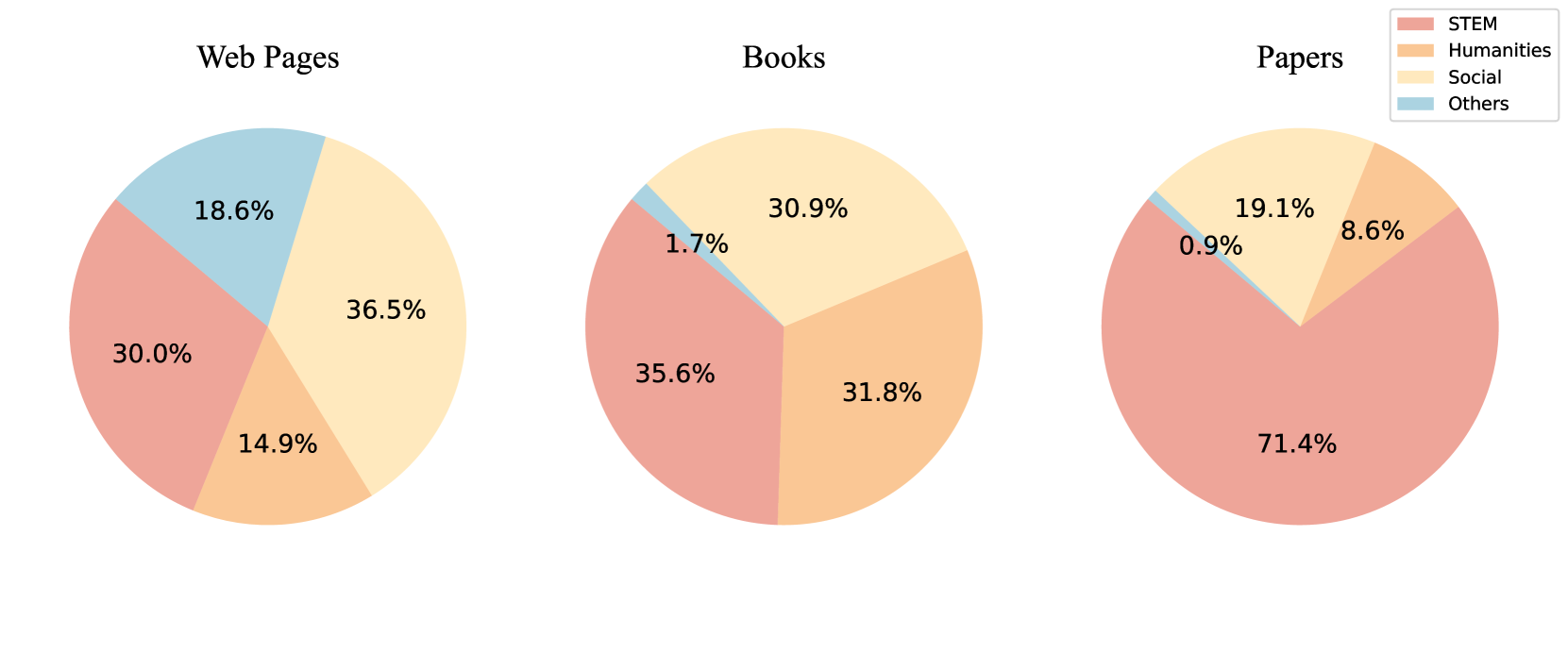


📊 实验亮点
BaichuanSEED在3T tokens上预训练后,无需针对特定下游任务进行优化,即可在综合基准测试中达到与Qwen1.5和Llama3等商业先进LLM相当的性能。这表明开源的数据处理流程具有很高的效率和有效性,能够为LLM的训练提供高质量的数据。
🎯 应用场景
该研究成果可应用于各种需要大规模语言模型的场景,例如智能客服、文本生成、机器翻译、代码生成等。通过开源的数据处理流程,可以降低LLM的应用门槛,促进LLM技术在各行各业的普及。此外,该研究还可以为LLM的进一步研究提供基础,例如数据质量评估、数据增强等。
📄 摘要(原文)
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.