Training-Free Activation Sparsity in Large Language Models
作者: James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
分类: cs.CL, cs.AI
发布日期: 2024-08-26 (更新: 2025-02-25)
备注: Rev. 2: ICLR 2025 Acceptance (Spotlight)
💡 一句话要点
提出TEAL:一种免训练的大语言模型激活稀疏化方法,提升推理速度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 激活稀疏化 免训练 推理加速 模型压缩
📋 核心要点
- 现有激活稀疏化方法或依赖特定模型结构,或需要大量预训练,限制了其通用性和易用性。
- TEAL通过简单地对隐藏层激活值进行幅度裁剪,实现免训练的激活稀疏化,无需额外训练开销。
- 实验表明,TEAL在多种LLM上实现了显著的稀疏化比例,同时保持了性能,并加速了推理过程。
📝 摘要(中文)
激活稀疏性通过减少前向传播期间矩阵乘法所需的计算和内存移动,能够显著提升大型语言模型(LLM)的推理速度。然而,现有方法存在局限性,阻碍了其广泛应用。一些方法专为基于ReLU的旧模型设计,而另一些方法则需要在数千亿token上进行大量的持续预训练。本文介绍了一种简单的免训练方法TEAL,它将基于幅度的激活稀疏性应用于整个模型的隐藏状态。TEAL在Llama-2、Llama-3和Mistral系列(规模从7B到70B)上实现了40-50%的模型范围稀疏性,且性能下降极小。我们改进了现有的稀疏内核,并在40%和50%模型范围稀疏性下,实现了高达1.53倍和1.8倍的实际解码加速。TEAL与权重量化兼容,从而能够进一步提高效率。
🔬 方法详解
问题定义:现有的大型语言模型激活稀疏化方法存在局限性。一些方法依赖于特定的激活函数(如ReLU),无法应用于所有模型。另一些方法需要大量的持续预训练,成本高昂且耗时。因此,需要一种通用的、免训练的激活稀疏化方法,以降低LLM的推理成本。
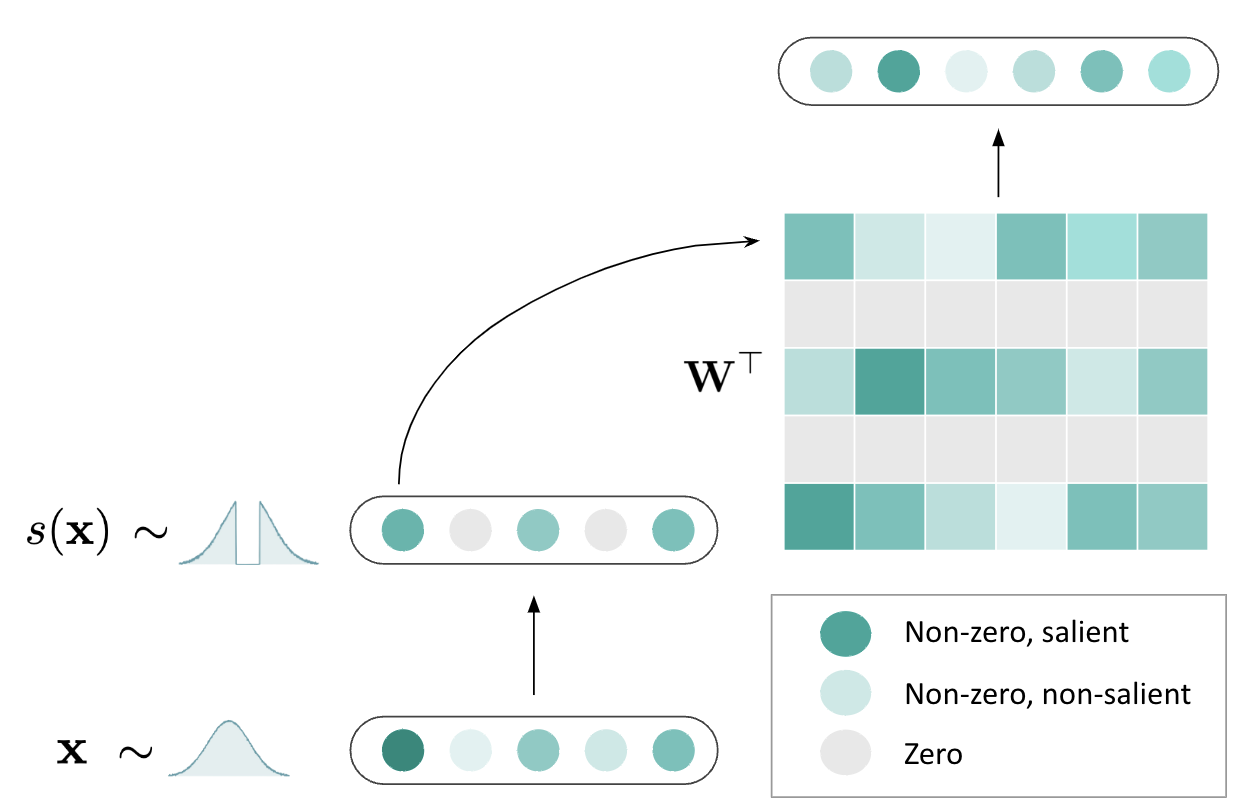
核心思路:TEAL的核心思路是基于激活值的幅度进行稀疏化。具体来说,对于每个隐藏层的激活值,只保留幅度最大的部分,其余部分置零。这种方法简单有效,无需额外的训练或模型修改,即可实现激活稀疏化。
技术框架:TEAL方法直接应用于LLM的每个隐藏层。在前向传播过程中,对于每个隐藏层的激活值,计算其幅度,并根据预设的稀疏度阈值,将幅度较小的激活值置零。整个过程无需修改模型结构或训练流程,可以方便地集成到现有的LLM推理框架中。
关键创新:TEAL的关键创新在于其免训练的特性。与需要大量预训练的稀疏化方法不同,TEAL可以直接应用于预训练好的LLM,无需额外的训练开销。此外,TEAL方法简单通用,可以应用于各种不同的LLM架构和激活函数。
关键设计:TEAL的关键设计在于稀疏度阈值的选择。稀疏度阈值决定了激活值的稀疏程度,需要根据具体的模型和任务进行调整。论文中可能采用了启发式方法或实验搜索来确定最佳的稀疏度阈值。此外,TEAL还兼容权重量化,可以进一步提高效率。
🖼️ 关键图片


📊 实验亮点
TEAL在Llama-2、Llama-3和Mistral等多个LLM上实现了40-50%的模型范围稀疏性,且性能下降极小。在40%和50%稀疏度下,解码速度分别提升了1.53倍和1.8倍。TEAL还与权重量化兼容,可以进一步提升效率。
🎯 应用场景
TEAL可广泛应用于各种需要加速LLM推理的场景,如移动设备上的本地部署、低延迟的在线服务以及资源受限的环境。通过降低计算和内存需求,TEAL使得LLM能够更高效地运行,从而扩展了LLM的应用范围。
📄 摘要(原文)
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$\times$ and 1.8$\times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.