CodeRefine: A Pipeline for Enhancing LLM-Generated Code Implementations of Research Papers
作者: Ekaterina Trofimova, Emil Sataev, Abhijit Singh Jowhari
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-23
💡 一句话要点
CodeRefine:利用LLM增强研究论文代码实现的自动化流程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 知识图谱 检索增强生成 研究论文 自动化 代码实现
📋 核心要点
- 现有方法难以将研究论文中的理论方法转化为可直接运行的代码,阻碍了科研成果的快速应用。
- CodeRefine通过提取论文关键信息,构建知识图谱,并结合检索增强生成,实现代码的自动生成与优化。
- 实验表明,CodeRefine能够有效提升代码实现的准确性,加速前沿算法在实际场景中的应用。
📝 摘要(中文)
本文提出了一种名为CodeRefine的新框架,该框架利用大型语言模型(LLM)自动将研究论文的方法论转化为可执行的代码。我们的多步骤方法首先从论文中提取和总结关键文本块,分析它们的代码相关性,并使用预定义的本体创建知识图。然后,从这种结构化表示中生成代码,并通过提出的回顾性检索增强生成方法进行增强。CodeRefine解决了连接理论研究和实际实现的挑战,提供了一种比LLM零样本提示更准确的替代方案。在各种科学论文上的评估表明,CodeRefine能够改进论文中的代码实现,从而可能加速前沿算法在实际应用中的采用。
🔬 方法详解
问题定义:现有方法,特别是直接使用LLM进行零样本提示,在将研究论文中的方法转化为可执行代码时,准确性和可靠性不足。这使得研究成果难以快速复现和应用,阻碍了科研进展的转化。现有方法难以理解论文深层含义,无法有效提取关键信息,导致生成的代码质量不高。
核心思路:CodeRefine的核心思路是将代码生成过程分解为多个步骤,包括信息提取、知识图谱构建、代码生成和检索增强优化。通过结构化地处理论文信息,并利用检索增强生成技术,提高代码生成的准确性和可靠性。这种方法模拟了人类专家阅读论文并编写代码的过程,从而更好地理解论文的意图并生成高质量的代码。
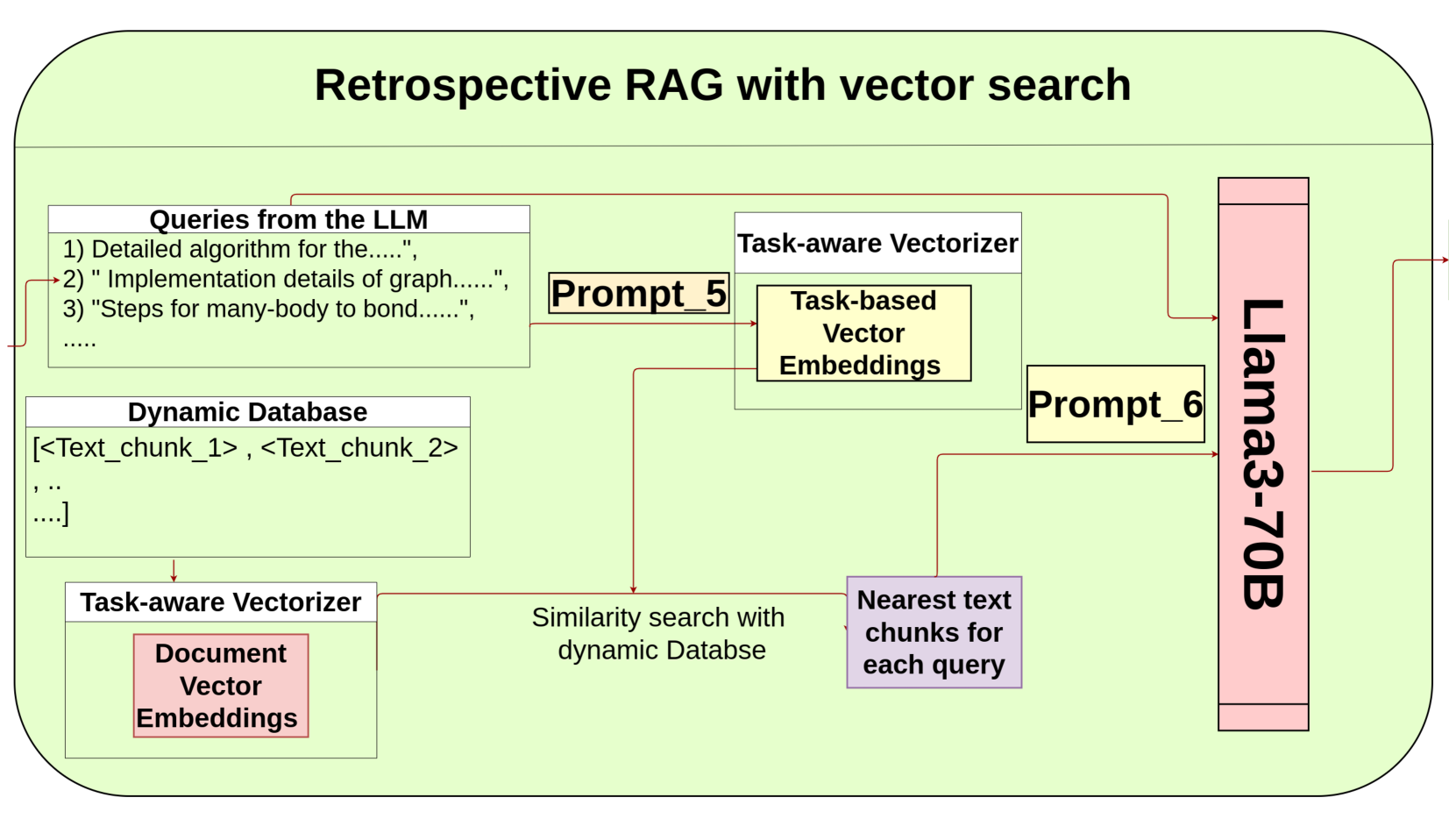
技术框架:CodeRefine包含以下主要模块:1) 文本提取与总结:从论文中提取关键文本块,并进行总结。2) 代码相关性分析:分析文本块与代码实现的相关性。3) 知识图谱构建:使用预定义的本体构建知识图谱,表示论文中的方法。4) 代码生成:从知识图谱生成初始代码。5) 回顾性检索增强生成:通过检索相关代码片段,并结合生成模型,优化代码实现。
关键创新:CodeRefine的关键创新在于其多步骤的代码生成流程和回顾性检索增强生成方法。与传统的零样本提示相比,CodeRefine能够更准确地理解论文的方法,并生成更可靠的代码。回顾性检索增强生成方法通过利用已有的代码资源,进一步提高了代码生成的质量。
关键设计:CodeRefine的关键设计包括:1) 预定义的本体:用于构建知识图谱,表示论文中的方法。2) 回顾性检索增强生成模型:用于优化代码实现,该模型可能包含特定的损失函数,用于衡量生成代码与目标代码之间的差异。3) 文本块提取策略:用于从论文中提取关键信息,可能涉及特定的文本分割算法和关键词提取方法。具体参数设置和网络结构未知。
🖼️ 关键图片


📊 实验亮点
论文通过在多个科学论文上的实验评估了CodeRefine的性能。实验结果表明,CodeRefine能够显著提高代码实现的准确性,并优于传统的零样本提示方法。具体的性能数据和提升幅度未知,但摘要强调了CodeRefine在改进代码实现方面的能力。
🎯 应用场景
CodeRefine可应用于科研领域,加速研究成果的转化和应用。它可以帮助研究人员快速实现论文中的算法,并进行验证和改进。此外,CodeRefine还可以用于教育领域,帮助学生更好地理解和学习科研论文。该工具的自动化特性可以降低代码实现的门槛,促进科研成果的普及。
📄 摘要(原文)
This paper presents CodeRefine, a novel framework for automatically transforming research paper methodologies into functional code using Large Language Models (LLMs). Our multi-step approach first extracts and summarizes key text chunks from papers, analyzes their code relevance, and creates a knowledge graph using a predefined ontology. Code is then generated from this structured representation and enhanced through a proposed retrospective retrieval-augmented generation approach. CodeRefine addresses the challenge of bridging theoretical research and practical implementation, offering a more accurate alternative to LLM zero-shot prompting. Evaluations on diverse scientific papers demonstrate CodeRefine's ability to improve code implementation from the paper, potentially accelerating the adoption of cutting-edge algorithms in real-world applications.