Can LLM be a Good Path Planner based on Prompt Engineering? Mitigating the Hallucination for Path Planning
作者: Hourui Deng, Hongjie Zhang, Jie Ou, Chaosheng Feng
分类: cs.CL
发布日期: 2024-08-23 (更新: 2025-05-07)
备注: Accepted by ICIC 2025
💡 一句话要点
提出S2RCQL模型,缓解LLM在路径规划中的空间幻觉与上下文不一致问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 路径规划 空间推理 幻觉缓解 Q学习 课程学习 具身智能
📋 核心要点
- LLM在路径规划中面临空间幻觉和上下文不一致幻觉的挑战,导致长期规划能力不足。
- 提出S2RCQL模型,通过空间到关系转换增强LLM的顺序思维,并利用Q学习缓解上下文不一致问题。
- 实验结果表明,S2RCQL在成功率和最优率方面相比先进的提示工程方法提升了23%-40%。
📝 摘要(中文)
大型语言模型(LLM)中的空间推理是具身智能的基础。然而,即使在简单的迷宫环境中,LLM在长期路径规划中仍然面临挑战,这主要受到空间幻觉和长期推理引起的上下文不一致幻觉的影响。为了解决这个问题,本研究提出了一种创新的模型,即空间到关系转换和课程Q学习(S2RCQL)。为了解决LLM的空间幻觉问题,我们提出了空间到关系的方法,该方法将空间提示转换为实体关系和代表实体关系链的路径。这种方法充分挖掘了LLM在顺序思维方面的潜力。因此,我们设计了一种基于Q学习的路径规划算法,以减轻上下文不一致幻觉,从而增强LLM的推理能力。通过使用状态-动作的Q值作为提示的辅助信息,我们纠正了LLM的幻觉,从而引导LLM学习最优路径。最后,我们提出了一种基于LLM的反向课程学习技术,以进一步减轻上下文不一致幻觉。LLM可以通过降低任务难度并利用它们来解决更复杂的任务,从而快速积累成功的经验。我们基于百度的自研LLM:文心大模型4.0进行了全面的实验。结果表明,与先进的提示工程相比,我们的S2RCQL在成功率和最优率方面都提高了23%--40%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在路径规划任务中存在的空间幻觉和上下文不一致性问题。现有的LLM在处理长期路径规划时,容易产生错误的路径信息,导致规划失败,尤其是在复杂的迷宫环境中。这些幻觉源于LLM对空间关系的理解不足以及长期推理过程中信息的丢失或扭曲。
核心思路:论文的核心思路是将空间信息转换为关系信息,利用LLM在关系推理方面的优势,并结合Q学习来纠正LLM的幻觉。通过将空间提示转化为实体关系和路径,增强LLM的顺序思维能力。同时,利用Q学习的状态-动作值作为辅助信息,引导LLM学习最优路径,并采用反向课程学习策略,逐步提升LLM的规划能力。
技术框架:S2RCQL模型主要包含三个核心模块:1) 空间到关系转换模块:将空间提示转换为实体关系和路径,构建关系图;2) Q学习路径规划模块:利用Q学习算法,根据关系图选择最优动作,并利用Q值作为提示信息,纠正LLM的幻觉;3) 反向课程学习模块:通过逐步增加任务难度,引导LLM学习更复杂的路径规划任务。
关键创新:论文的关键创新在于提出了空间到关系转换的方法,将空间信息转化为LLM更擅长处理的关系信息,从而有效缓解了空间幻觉问题。此外,结合Q学习和反向课程学习,进一步提升了LLM的路径规划能力。与传统的提示工程方法相比,S2RCQL能够更有效地利用LLM的推理能力,并纠正其幻觉。
关键设计:在空间到关系转换模块中,需要定义合适的实体关系表示方法,例如使用节点表示位置,边表示相邻关系。在Q学习模块中,需要设计合适的奖励函数,例如到达目标位置获得正奖励,碰撞或超出边界获得负奖励。反向课程学习模块需要设计合适的任务难度递增策略,例如逐步增加迷宫的复杂度和路径长度。
🖼️ 关键图片
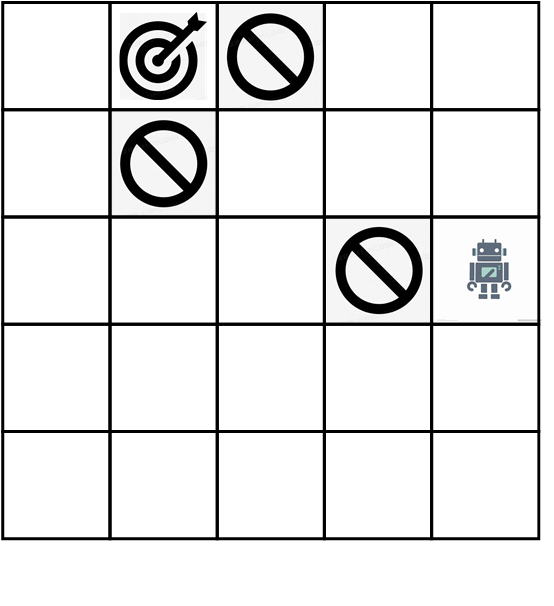
📊 实验亮点
实验结果表明,S2RCQL模型在文心大模型4.0上进行了验证,与先进的提示工程方法相比,在路径规划的成功率和最优率方面分别提升了23%和40%。这表明S2RCQL能够有效缓解LLM在路径规划中的幻觉问题,并显著提升其规划性能。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、智能交通等领域。通过提升LLM在路径规划方面的能力,可以使机器人更好地理解和执行复杂的导航任务,提高游戏AI的智能化水平,并优化智能交通系统的路径规划策略,从而提高效率和安全性。
📄 摘要(原文)
Spatial reasoning in Large Language Models (LLMs) is the foundation for embodied intelligence. However, even in simple maze environments, LLMs still encounter challenges in long-term path-planning, primarily influenced by their spatial hallucination and context inconsistency hallucination by long-term reasoning. To address this challenge, this study proposes an innovative model, Spatial-to-Relational Transformation and Curriculum Q-Learning (S2RCQL). To address the spatial hallucination of LLMs, we propose the Spatial-to-Relational approach, which transforms spatial prompts into entity relations and paths representing entity relation chains. This approach fully taps the potential of LLMs in terms of sequential thinking. As a result, we design a path-planning algorithm based on Q-learning to mitigate the context inconsistency hallucination, which enhances the reasoning ability of LLMs. Using the Q-value of state-action as auxiliary information for prompts, we correct the hallucinations of LLMs, thereby guiding LLMs to learn the optimal path. Finally, we propose a reverse curriculum learning technique based on LLMs to further mitigate the context inconsistency hallucination. LLMs can rapidly accumulate successful experiences by reducing task difficulty and leveraging them to tackle more complex tasks. We performed comprehensive experiments based on Baidu's self-developed LLM: ERNIE-Bot 4.0. The results showed that our S2RCQL achieved a 23%--40% improvement in both success and optimality rates compared with advanced prompt engineering.