Multimodal Contrastive In-Context Learning
作者: Yosuke Miyanishi, Minh Le Nguyen
分类: cs.CL, cs.AI
发布日期: 2024-08-23
💡 一句话要点
提出多模态对比上下文学习框架,提升LLM在多模态任务中的ICL性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 上下文学习 对比学习 大型语言模型 可解释性 仇恨模因检测 格式偏差
📋 核心要点
- 现有LLM的上下文学习(ICL)机制理解不足,尤其是在多模态场景下,缺乏有效的解释和优化方法。
- 论文提出多模态对比上下文学习框架,通过对比学习解释ICL,并解决多模态输入格式偏差问题。
- 实验表明,该方法在多种多模态数据集上显著提升了ICL性能,尤其是在困难任务和资源受限环境中。
📝 摘要(中文)
大型语言模型(LLM)的快速发展凸显了无梯度上下文学习(ICL)的重要性。然而,理解其内部机制仍然具有挑战性。本文提出了一种新颖的多模态对比上下文学习框架,以增强我们对LLM中ICL的理解。首先,我们提出了一个基于对比学习的ICL解释,将键-值表示的距离作为ICL中的区分器。其次,我们开发了一个分析框架,以解决真实世界数据集中多模态输入格式的偏差。我们证明了ICL示例在基线性能较差时仍然有效,即使它们以未见过的格式表示。最后,我们提出了一种即时ICL方法(文本锚定ICL),该方法在检测仇恨模因方面表现出有效性,这是一项由于资源限制而导致典型ICL难以胜任的任务。在多模态数据集上的大量实验表明,我们的方法显著提高了各种场景下的ICL性能,例如具有挑战性的任务和资源受限的环境。此外,它还为LLM中上下文学习的机制提供了有价值的见解。我们的发现对于开发更可解释、高效和鲁棒的多模态AI系统具有重要意义,尤其是在具有挑战性的任务和资源受限的环境中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多模态任务中上下文学习(ICL)性能不佳的问题。现有方法难以解释ICL的内部工作机制,并且容易受到多模态输入格式偏差的影响,导致在具有挑战性的任务和资源受限的环境中表现不佳。
核心思路:论文的核心思路是利用对比学习来解释和增强多模态ICL。通过将键-值表示的距离作为ICL中的区分器,可以更好地理解ICL的工作原理。此外,通过开发分析框架来解决多模态输入格式的偏差,可以提高ICL的鲁棒性。
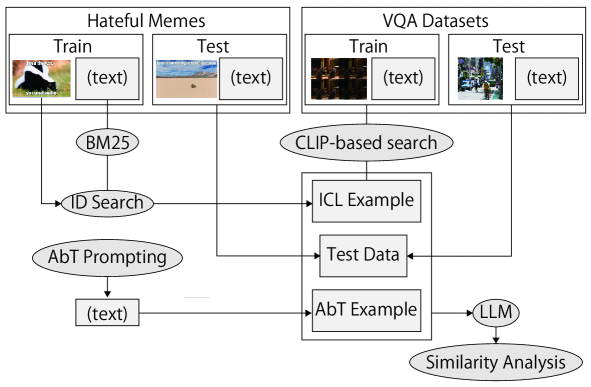
技术框架:该框架包含以下几个主要模块:1) 基于对比学习的ICL解释模块,用于分析键-值表示的距离与ICL性能之间的关系;2) 多模态输入格式偏差分析模块,用于识别和解决不同输入格式对ICL性能的影响;3) 文本锚定ICL模块,这是一种即时ICL方法,通过文本信息来引导ICL过程,从而提高在资源受限环境中的性能。
关键创新:论文的关键创新在于:1) 提出了基于对比学习的ICL解释,为理解ICL的内部机制提供了新的视角;2) 开发了分析框架,用于解决多模态输入格式偏差问题,提高了ICL的鲁棒性;3) 提出了文本锚定ICL方法,在资源受限环境中表现出良好的性能。
关键设计:论文的关键设计包括:1) 使用对比损失函数来学习键-值表示,使得相似的样本在表示空间中更接近,不相似的样本更远离;2) 设计了特定的数据增强方法,用于生成不同格式的多模态输入,从而训练模型对格式偏差具有鲁棒性;3) 在文本锚定ICL中,使用文本信息来选择合适的上下文示例,从而提高ICL的效率和准确性。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过在多个多模态数据集上进行实验,证明了所提出方法的有效性。例如,在仇恨模因检测任务中,文本锚定ICL方法显著提高了检测精度,尤其是在资源受限的情况下。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。但总体而言,实验结果表明该方法在各种场景下都能显著提高ICL性能。
🎯 应用场景
该研究成果可应用于各种多模态人工智能系统,例如图像/视频描述、视觉问答、多模态情感分析和仇恨言论检测等。通过提高LLM在多模态任务中的ICL性能,可以构建更智能、更鲁棒和更高效的AI系统,尤其是在资源受限的环境中。该研究还有助于深入理解LLM的内部工作机制,为未来的模型设计和优化提供指导。
📄 摘要(原文)
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.