Preference Consistency Matters: Enhancing Preference Learning in Language Models with Automated Self-Curation of Training Corpora
作者: JoonHo Lee, JuYoun Son, Juree Seok, Wooseok Jang, Yeong-Dae Kwon
分类: cs.CL, cs.AI
发布日期: 2024-08-23 (更新: 2025-01-31)
备注: Accepted to NAACL 2025 main conference
💡 一句话要点
提出自校正方法,通过自动筛选一致性标注提升语言模型偏好学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好学习 数据校正 自监督学习 语言模型 指令跟随 标注一致性 代理模型
📋 核心要点
- 偏好学习数据集中的标注不一致性是提升语言模型性能的瓶颈,源于标注者差异和偏好多维性。
- 论文提出一种自校正方法,利用代理模型自动检测和选择一致性标注,从而优化训练数据。
- 实验表明,该方法在指令跟随任务中显著提升了性能,最高可达33%,且无需人工干预。
📝 摘要(中文)
训练语料库中不一致的标注,尤其是在偏好学习数据集中,对开发先进的语言模型提出了挑战。这些不一致性通常源于标注者之间的差异以及偏好固有的多维性质。为了解决这些问题,我们提出了一种自校正方法,该方法通过利用直接在数据集上训练的代理模型来预处理标注数据集。我们的方法通过自动检测和选择一致的标注来增强偏好学习。我们通过广泛的指令跟随任务验证了所提出的方法,证明了在各种学习算法和代理能力下,性能提高了高达33%。这项工作提供了一种直接且可靠的解决方案来解决偏好不一致问题,而无需依赖启发式方法,是朝着开发更先进的偏好学习方法迈出的第一步。
🔬 方法详解
问题定义:现有偏好学习方法受限于训练数据中存在的标注不一致问题。不同标注者对相同输入的偏好可能存在差异,导致模型学习到的偏好不稳定,泛化能力下降。现有方法通常依赖人工规则或启发式方法来处理这些不一致性,效率低且效果有限。
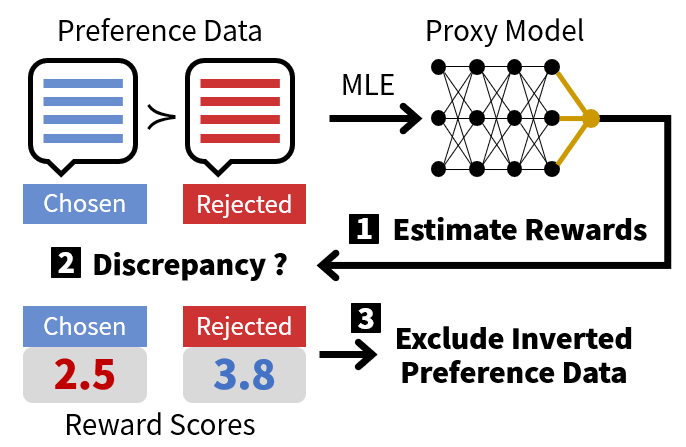
核心思路:论文的核心思路是利用模型自身的能力来识别和筛选高质量的、一致性高的标注数据。通过训练一个代理模型来预测标注的质量,并基于预测结果自动选择用于训练的样本,从而提高训练数据的质量和一致性。
技术框架:整体框架包含以下几个主要阶段:1) 初始训练:使用原始标注数据训练一个代理模型,该模型用于预测标注的一致性或质量。2) 一致性评估:使用训练好的代理模型对原始标注数据进行评估,为每个标注样本打分,表示其一致性或质量。3) 数据筛选:基于代理模型的评分,选择一致性或质量较高的标注样本,构建新的训练数据集。4) 模型训练:使用筛选后的高质量数据集训练最终的偏好学习模型。
关键创新:该方法的核心创新在于利用代理模型进行自动数据校正,无需人工干预或启发式规则。通过模型自身学习到的知识来评估和筛选数据,能够更有效地识别和去除不一致的标注,从而提高训练数据的质量。与传统方法相比,该方法更加自动化、高效且可扩展。
关键设计:代理模型的选择和训练是关键。论文中使用了多种代理模型,并比较了它们的效果。此外,数据筛选的阈值也是一个重要的参数,需要根据具体数据集进行调整。损失函数的设计也需要考虑如何更好地反映标注的一致性或质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用自校正方法后,模型在指令跟随任务中的性能显著提升,最高可达33%。该方法在不同的学习算法和代理模型下均表现出良好的效果,证明了其鲁棒性和通用性。此外,实验还表明,该方法能够有效地识别和去除不一致的标注,从而提高训练数据的质量。
🎯 应用场景
该研究成果可广泛应用于各种需要偏好学习的场景,例如对话系统、推荐系统、文本生成等。通过提高训练数据的质量,可以显著提升模型的性能和用户体验。此外,该方法还可以应用于其他类型的数据集,例如图像标注、语音识别等,具有广泛的应用前景。
📄 摘要(原文)
Inconsistent annotations in training corpora, particularly within preference learning datasets, pose challenges in developing advanced language models. These inconsistencies often arise from variability among annotators and inherent multi-dimensional nature of the preferences. To address these issues, we introduce a self-curation method that preprocesses annotated datasets by leveraging proxy models trained directly on them. Our method enhances preference learning by automatically detecting and selecting consistent annotations. We validate the proposed approach through extensive instruction-following tasks, demonstrating performance improvements of up to 33\% across various learning algorithms and proxy capabilities. This work offers a straightforward and reliable solution to address preference inconsistencies without relying on heuristics, serving as an initial step toward the development of more advanced preference learning methodologies. Code is available at https://github.com/Self-Curation/ .