SLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection
作者: Mengya Hu, Rui Xu, Deren Lei, Yaxi Li, Mingyu Wang, Emily Ching, Eslam Kamal, Alex Deng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-22
备注: preprint under review
💡 一句话要点
提出SLM与LLM结合框架,平衡幻觉检测的延迟、可解释性和一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 小型语言模型 幻觉检测 实时性 可解释性 提示工程 约束推理
📋 核心要点
- 大型语言模型在幻觉检测等实时应用中存在延迟问题,影响用户体验。
- 利用小型语言模型进行快速初步检测,再由大型语言模型进行约束推理和详细解释。
- 通过有效的提示工程,使大型语言模型生成的解释与小型语言模型的决策对齐,提升检测效果。
📝 摘要(中文)
大型语言模型(LLMs)功能强大,但在实时应用中面临延迟挑战,例如在线幻觉检测。为了克服这个问题,我们提出了一种新颖的框架,该框架利用小型语言模型(SLM)分类器进行初始检测,然后使用LLM作为受约束的推理器,为检测到的幻觉内容生成详细的解释。本研究通过引入有效的提示技术,使LLM生成的解释与SLM的决策保持一致,从而优化了实时可解释的幻觉检测。实证实验结果表明了其有效性,从而增强了整体用户体验。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在实时幻觉检测中存在的延迟问题。现有方法要么依赖于计算成本高昂的LLM,导致延迟过高;要么使用小型模型,但缺乏可解释性和一致性,难以保证检测质量。
核心思路:论文的核心思路是结合小型语言模型(SLM)和大型语言模型(LLM)的优势。SLM负责快速初步检测,LLM负责提供详细解释和进行约束推理,从而在延迟、可解释性和一致性之间取得平衡。这样既能保证实时性,又能提供高质量的检测结果。
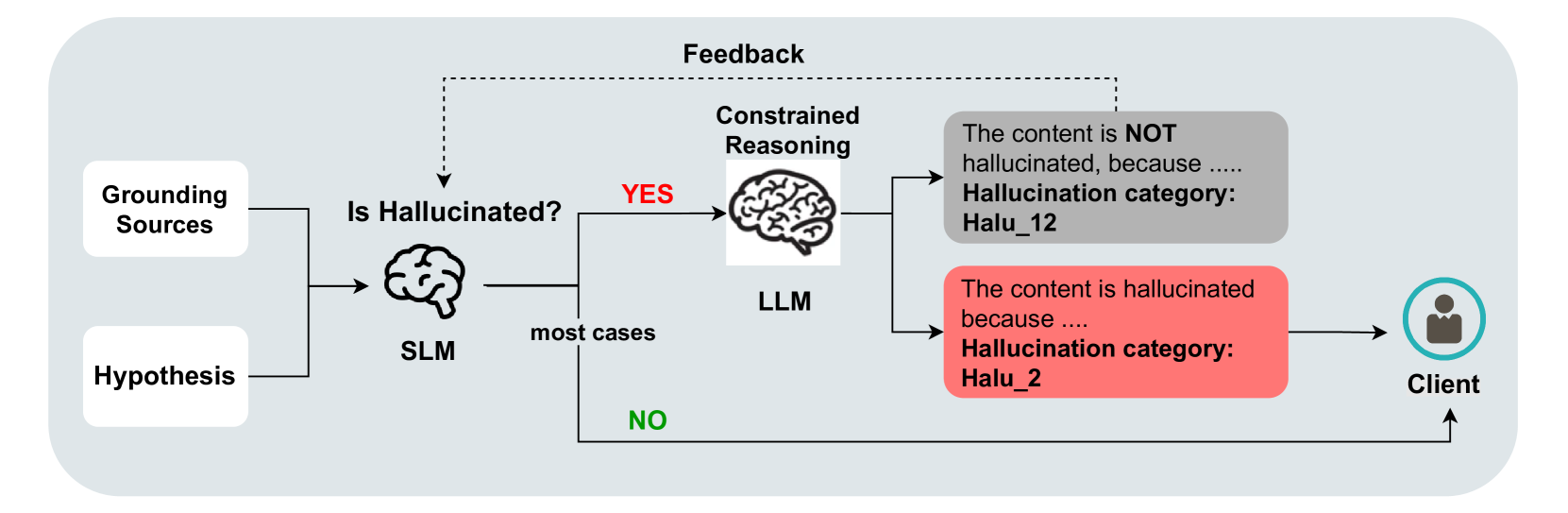
技术框架:该框架包含两个主要阶段:1) SLM分类器:使用小型语言模型对输入内容进行快速初步的幻觉检测,输出二元分类结果(是否为幻觉)。2) LLM约束推理器:对于SLM检测为幻觉的内容,使用大型语言模型生成详细的解释。通过特定的提示工程,引导LLM的解释与SLM的决策保持一致。整个流程旨在提供快速且可解释的幻觉检测结果。
关键创新:该方法最重要的创新点在于将SLM和LLM结合,利用SLM的快速性和LLM的推理能力,实现实时且可解释的幻觉检测。此外,通过有效的提示工程,约束LLM的输出,使其与SLM的决策保持一致,提高了整体检测的准确性和可靠性。
关键设计:论文的关键设计在于提示工程。具体来说,设计了特定的提示模板,引导LLM生成与SLM决策一致的解释。例如,提示可以包含SLM的分类结果,并要求LLM解释为什么该内容被认为是幻觉。此外,可能还涉及到对LLM输出的后处理,以确保其符合预期的格式和内容。
🖼️ 关键图片
📊 实验亮点
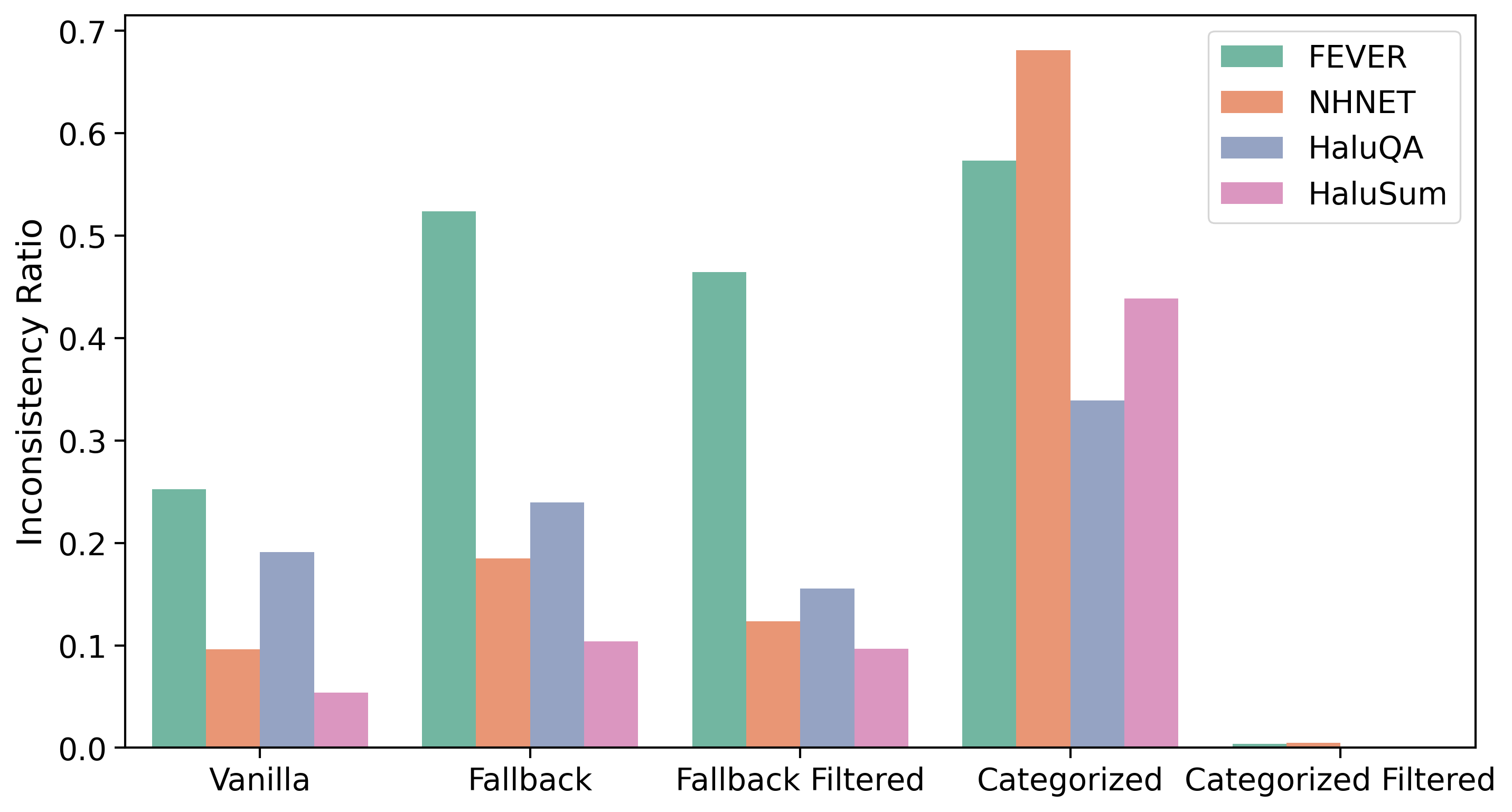
论文通过实验验证了所提出框架的有效性。实验结果表明,该框架在保持较低延迟的同时,能够提供高质量的幻觉检测结果,并且LLM生成的解释与SLM的决策具有较高的一致性。具体的性能数据(例如准确率、召回率、F1值、延迟等)未知,但摘要强调了其有效性。
🎯 应用场景
该研究成果可应用于各种需要实时幻觉检测的场景,例如在线对话系统、内容审核平台、智能客服等。通过快速检测和解释幻觉内容,可以提高用户体验,减少错误信息的传播,并提升系统的可靠性。未来,该方法还可以扩展到其他自然语言处理任务中,例如虚假新闻检测、情感分析等。
📄 摘要(原文)
Large language models (LLMs) are highly capable but face latency challenges in real-time applications, such as conducting online hallucination detection. To overcome this issue, we propose a novel framework that leverages a small language model (SLM) classifier for initial detection, followed by a LLM as constrained reasoner to generate detailed explanations for detected hallucinated content. This study optimizes the real-time interpretable hallucination detection by introducing effective prompting techniques that align LLM-generated explanations with SLM decisions. Empirical experiment results demonstrate its effectiveness, thereby enhancing the overall user experience.