Toward the Evaluation of Large Language Models Considering Score Variance across Instruction Templates
作者: Yusuke Sakai, Adam Nohejl, Jiangnan Hang, Hidetaka Kamigaito, Taro Watanabe
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-22
备注: 19 pages, 7 figures
💡 一句话要点
提出考虑指令模板方差的LLM评估方法,解决NLU性能评估不公平问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 自然语言理解 指令模板 夏普比率 跨语言数据集
📋 核心要点
- 现有LLM的NLU评估忽略了不同提示模板导致的分数差异,造成评估结果不公平,且不适用于指令调优。
- 论文提出使用包含多个指令模板的数据集,并采用夏普比率作为评估指标,以衡量NLU性能并考虑模板间方差。
- 通过对英日LLM的分析,验证了模板方差对LLM公平评估的显著影响,突显了新评估方法的重要性。
📝 摘要(中文)
大型语言模型(LLM)的自然语言理解(NLU)性能已经在各种任务和数据集上进行了评估。然而,现有的评估方法没有考虑到由于提示差异导致的分数方差,这导致了NLU性能的不公平评估和比较。此外,为特定提示设计的评估不适用于指令调优,指令调优旨在在任何提示下都能表现良好。因此,有必要找到一种公平衡量NLU性能的方法,同时考虑到不同指令模板之间的分数方差。在本研究中,我们提供了英语和日语的跨语言数据集,用于评估LLM的NLU性能,其中包括多个指令模板,以便对每个任务进行公平评估,以及用于约束输出格式的正则表达式。此外,我们提出了夏普比率作为一种评估指标,该指标考虑了模板之间的分数方差。对英语和日语LLM的综合分析表明,模板之间的高方差对LLM的公平评估有显著影响。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)的自然语言理解(NLU)性能评估方法,主要问题在于忽略了不同指令模板(instruction templates)对评估结果的影响。不同的prompt方式会导致模型在同一任务上的表现产生差异,这种差异使得对LLM的NLU性能评估变得不公平,无法准确反映模型的真实能力。此外,针对特定prompt设计的评估方法不适用于指令调优,因为指令调优的目标是让模型能够泛化到各种不同的prompt上。
核心思路:论文的核心思路是构建一个包含多个指令模板的数据集,并使用一种能够考虑模板间分数方差的评估指标,从而实现对LLM NLU性能的公平评估。通过引入多个指令模板,可以更全面地评估模型在不同prompt下的表现,从而减少评估结果的偏差。同时,使用夏普比率(Sharpe Ratio)作为评估指标,可以同时考虑模型的平均性能和性能的稳定性,从而更准确地反映模型的NLU能力。
技术框架:该研究的技术框架主要包括以下几个部分:1)构建跨语言数据集:创建包含英语和日语两种语言的数据集,用于评估LLM的NLU性能。该数据集包含多个指令模板,每个任务都有不同的prompt方式。2)约束输出格式:使用正则表达式来约束模型的输出格式,确保评估结果的准确性。3)使用夏普比率进行评估:采用夏普比率作为评估指标,该指标考虑了模板之间的分数方差,可以更公平地评估LLM的NLU性能。4)实验分析:对英语和日语LLM进行综合分析,评估模板方差对LLM公平评估的影响。
关键创新:该论文的关键创新在于:1)提出了一个考虑指令模板方差的LLM NLU性能评估方法。2)构建了一个包含多个指令模板的跨语言数据集,用于评估LLM的NLU性能。3)采用了夏普比率作为评估指标,该指标可以同时考虑模型的平均性能和性能的稳定性。
关键设计:数据集包含多个指令模板,每个模板都以不同的方式prompt模型完成相同的任务。使用正则表达式来约束模型的输出格式,确保输出结果符合预期。夏普比率的计算公式为:(平均分数 - 无信息基线的平均分数) / 分数标准差。通过减去无信息基线的平均分数,可以消除任务难度对评估结果的影响。分数标准差反映了模型在不同模板下的性能稳定性,标准差越小,说明模型的性能越稳定。
🖼️ 关键图片

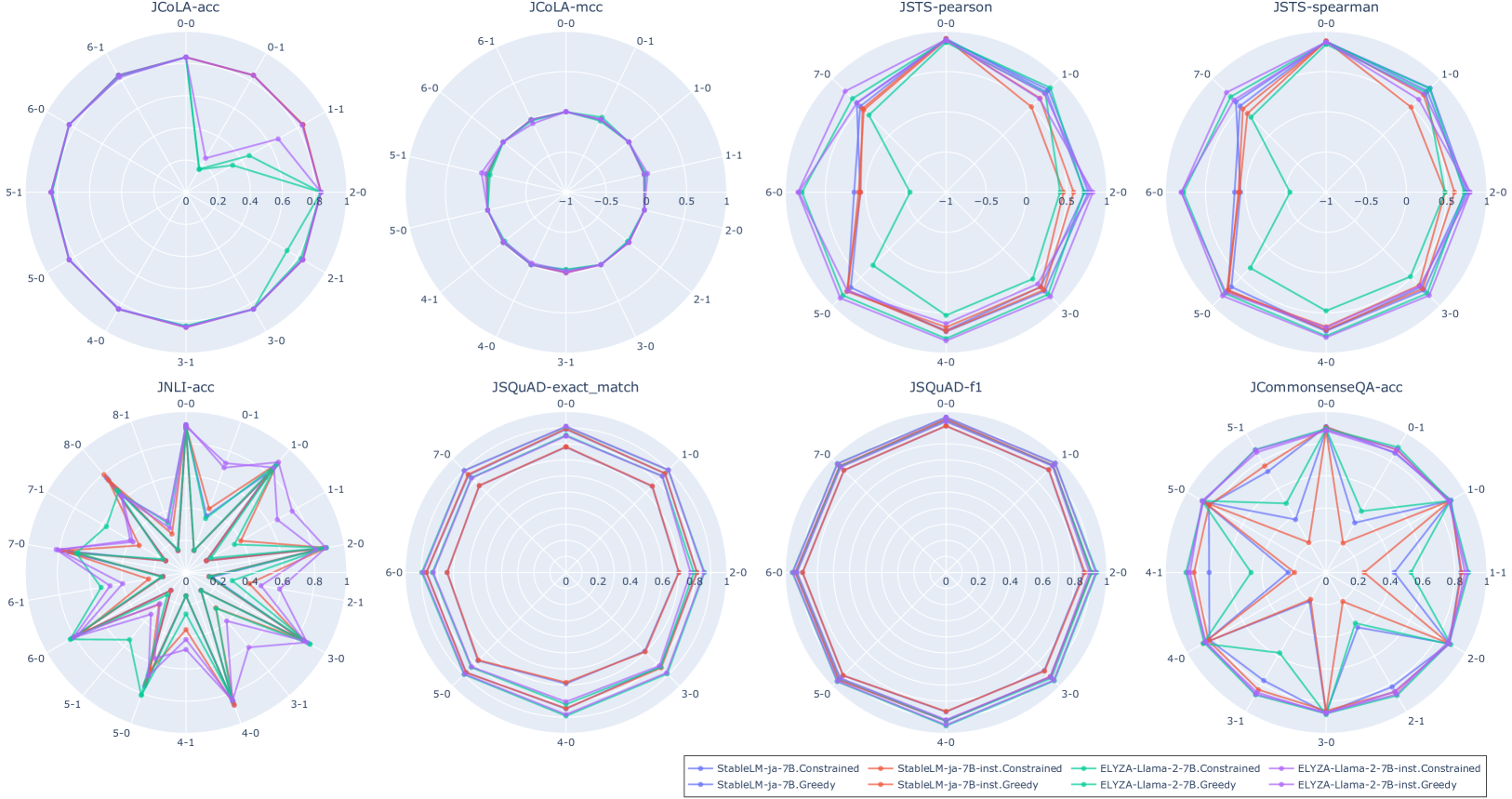
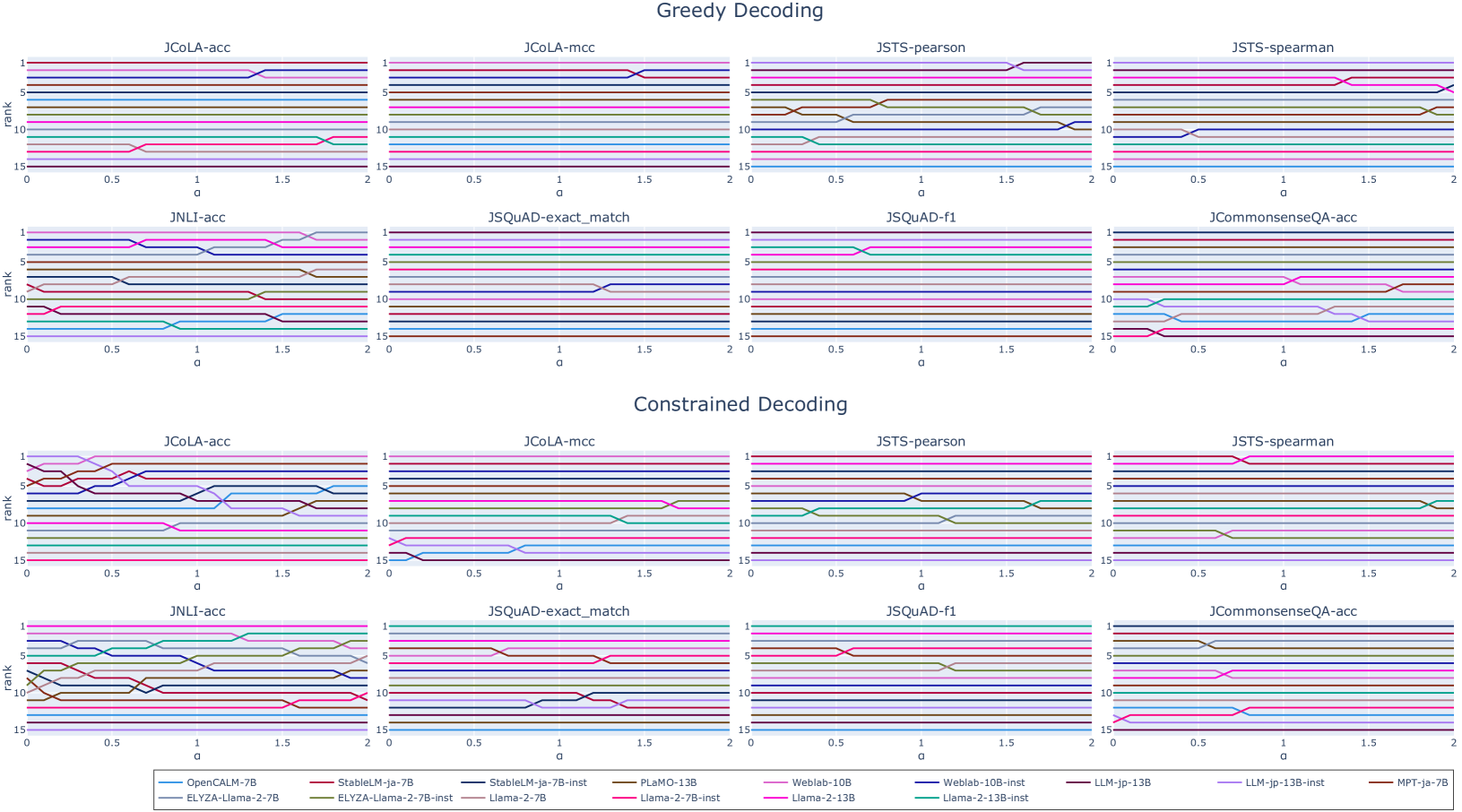
📊 实验亮点
论文通过对英日LLM的实验分析,验证了指令模板方差对评估结果的显著影响。使用夏普比率作为评估指标,能够更公平地衡量LLM的NLU性能。实验结果表明,考虑模板方差的评估方法能够更准确地反映模型的真实能力。
🎯 应用场景
该研究成果可应用于LLM的公平评估与选择,指导指令调优过程,提升模型在各种prompt下的泛化能力。同时,构建的数据集和评估方法可促进跨语言NLU研究,推动LLM在多语言环境下的应用。
📄 摘要(原文)
The natural language understanding (NLU) performance of large language models (LLMs) has been evaluated across various tasks and datasets. The existing evaluation methods, however, do not take into account the variance in scores due to differences in prompts, which leads to unfair evaluation and comparison of NLU performance. Moreover, evaluation designed for specific prompts is inappropriate for instruction tuning, which aims to perform well with any prompt. It is therefore necessary to find a way to measure NLU performance in a fair manner, considering score variance between different instruction templates. In this study, we provide English and Japanese cross-lingual datasets for evaluating the NLU performance of LLMs, which include multiple instruction templates for fair evaluation of each task, along with regular expressions to constrain the output format. Furthermore, we propose the Sharpe score as an evaluation metric that takes into account the variance in scores between templates. Comprehensive analysis of English and Japanese LLMs reveals that the high variance among templates has a significant impact on the fair evaluation of LLMs.