Political Bias in LLMs: Unaligned Moral Values in Agent-centric Simulations
作者: Simon Münker
分类: cs.CL, cs.AI
发布日期: 2024-08-21 (更新: 2025-07-14)
备注: 14 pages, 2 tables
期刊: JLCL 2025, Band 38(2)
DOI: 10.21248/jlcl.38.2025.289
💡 一句话要点
利用Agent模拟评估LLM政治倾向:揭示道德价值观与人类认知的偏差
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 大型语言模型 政治倾向 道德基础理论 Agent模拟 社会科学 价值观对齐 上下文学习
📋 核心要点
- 现有语言模型在社会科学领域的应用面临挑战,尤其是在模拟人类政治倾向和道德价值观方面。
- 该研究通过构建具有不同政治角色的Agent,并使用道德基础理论问卷来评估LLM的政治倾向。
- 实验结果表明,LLM在模拟政治倾向时存在不一致性,与真实人类数据对齐效果较差,尤其是在保守派角色上。
📝 摘要(中文)
当前社会科学研究越来越多地利用先进的生成式语言模型来注释或生成内容。尽管这些模型在常见的语言任务上取得了领先的性能,但它们在新领域任务中的应用仍未得到充分探索。为了弥补这一差距,我们研究了个性化语言模型在道德基础理论问卷上与人类反应的对齐情况。我们将开源生成式语言模型适配到不同的政治角色,并反复调查这些模型,以生成合成数据集,其中模型-角色组合定义了我们的子群体。我们的分析表明,模型在多次重复中产生不一致的结果,导致较高的响应方差。此外,合成数据与心理学研究中相应的人类数据之间的对齐显示出微弱的相关性,特别是保守角色提示的模型未能与实际的保守人群对齐。这些结果表明,由于其对齐过程,语言模型难以通过上下文提示连贯地表示意识形态。因此,使用语言模型来模拟社会互动需要在上下文优化或参数操作方面进行可衡量的改进,以与心理和社会学刻板印象正确对齐。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在通用语言任务上表现出色,但在模拟人类社会行为,特别是政治倾向和道德价值观方面,存在不足。现有的方法难以保证LLM输出结果与特定政治立场人群的真实行为和价值观相符,这限制了LLM在社会科学研究中的应用。
核心思路:本研究的核心思路是通过构建具有不同政治角色(例如,自由派、保守派)的Agent,并使用道德基础理论问卷(Moral Foundation Theory Questionnaire)来评估LLM的政治倾向。通过对比LLM生成的合成数据与真实人类数据,分析LLM在模拟不同政治立场人群时的偏差。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择开源的生成式语言模型;2) 通过上下文提示(in-context prompting)将模型适配到不同的政治角色;3) 使用道德基础理论问卷对这些模型进行多次调查,生成合成数据集;4) 分析合成数据集的统计特性,并与真实人类数据进行对比,评估LLM的政治倾向偏差。
关键创新:该研究的关键创新在于:1) 将LLM应用于模拟人类政治倾向和社会行为,探索了LLM在新领域的应用;2) 通过构建具有不同政治角色的Agent,并使用道德基础理论问卷,系统地评估了LLM的政治倾向偏差;3) 揭示了LLM在模拟保守派人群时存在显著偏差,表明LLM的对齐过程可能存在问题。
关键设计:研究中使用了开源的生成式语言模型,并通过上下文提示来塑造模型的政治角色。道德基础理论问卷用于评估模型在五个道德维度上的倾向:关怀/伤害、公平/欺骗、忠诚/背叛、权威/颠覆和圣洁/堕落。通过多次重复实验,并计算响应方差,评估模型输出的一致性。使用相关性分析来评估合成数据与真实人类数据的对齐程度。
🖼️ 关键图片
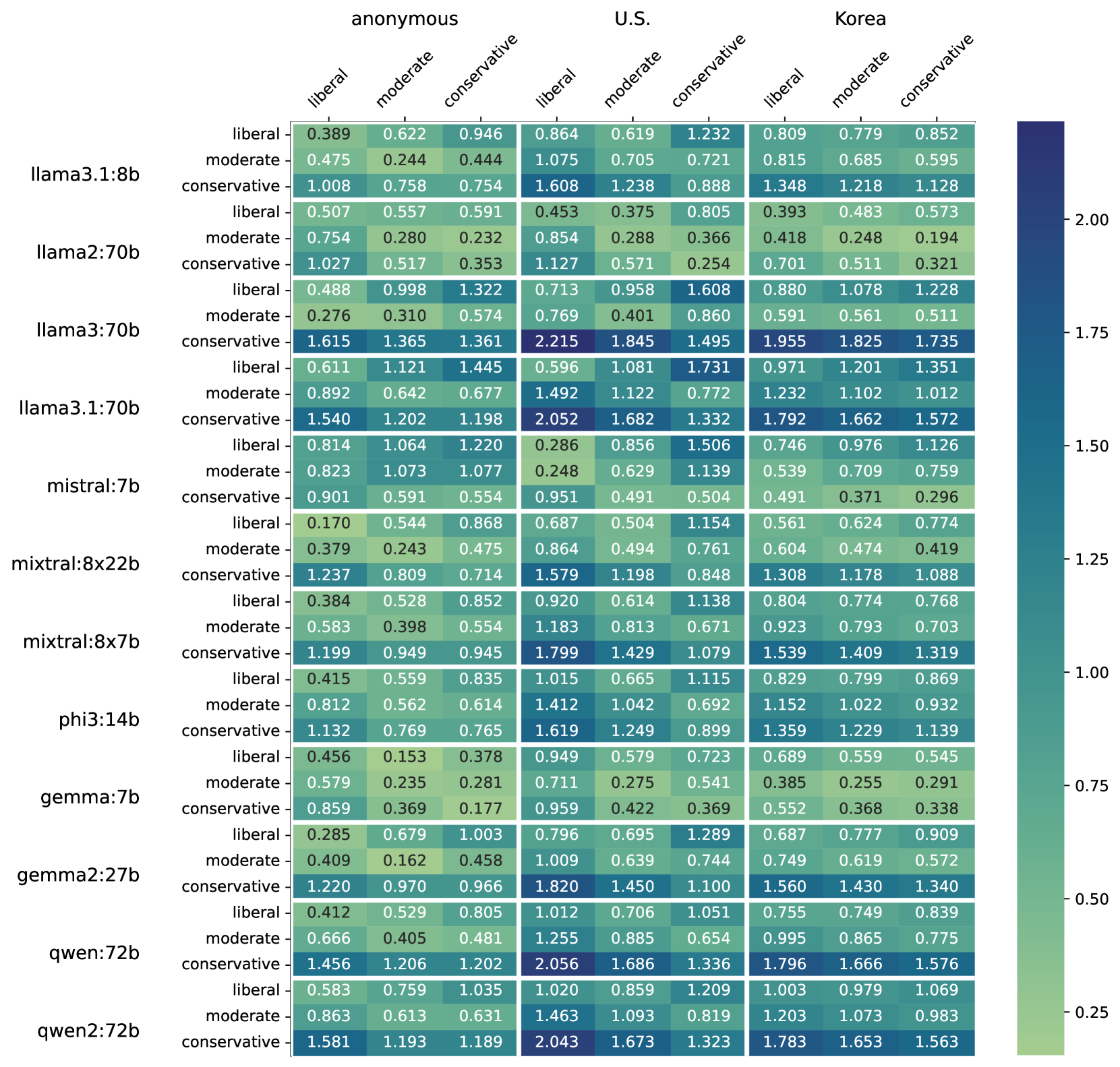
📊 实验亮点
实验结果表明,LLM在模拟政治倾向时存在显著的偏差,尤其是在保守派角色上。合成数据与真实人类数据的相关性较弱,表明LLM难以准确地捕捉不同政治立场人群的价值观。模型在多次重复实验中产生不一致的结果,导致较高的响应方差,表明LLM的输出不稳定。
🎯 应用场景
该研究的潜在应用领域包括社会科学研究、政治学分析、舆情监控和人机交互设计。通过更准确地模拟人类政治倾向,可以帮助研究人员更好地理解社会现象,预测政治事件,并设计更符合人类价值观的人工智能系统。未来的研究可以探索更有效的上下文优化方法,以提高LLM在模拟社会行为方面的准确性。
📄 摘要(原文)
Contemporary research in social sciences increasingly utilizes state-of-the-art generative language models to annotate or generate content. While these models achieve benchmark-leading performance on common language tasks, their application to novel out-of-domain tasks remains insufficiently explored. To address this gap, we investigate how personalized language models align with human responses on the Moral Foundation Theory Questionnaire. We adapt open-source generative language models to different political personas and repeatedly survey these models to generate synthetic data sets where model-persona combinations define our sub-populations. Our analysis reveals that models produce inconsistent results across multiple repetitions, yielding high response variance. Furthermore, the alignment between synthetic data and corresponding human data from psychological studies shows a weak correlation, with conservative persona-prompted models particularly failing to align with actual conservative populations. These results suggest that language models struggle to coherently represent ideologies through in-context prompting due to their alignment process. Thus, using language models to simulate social interactions requires measurable improvements in in-context optimization or parameter manipulation to align with psychological and sociological stereotypes properly.