SarcasmBench: Towards Evaluating Large Language Models on Sarcasm Understanding
作者: Yazhou Zhang, Chunwang Zou, Zheng Lian, Prayag Tiwari, Jing Qin
分类: cs.CL, cs.AI
发布日期: 2024-08-21 (更新: 2024-08-24)
💡 一句话要点
提出SarcasmBench以解决大语言模型在讽刺理解中的不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 讽刺理解 大语言模型 自然语言处理 情感分析 模型评估 提示方法 机器学习
📋 核心要点
- 现有的LLMs在讽刺理解方面表现不佳,无法有效捕捉讽刺所蕴含的复杂情感和意图。
- 论文通过选择多种最先进的LLMs和PLMs,采用不同的提示方法进行全面评估,以探讨LLMs在讽刺理解中的能力。
- 实验结果表明,GPT-4在各种提示方法中表现最佳,且少量示例提示法优于其他方法,显示出讽刺检测的独特性。
📝 摘要(中文)
在大型语言模型(LLMs)时代,虽然“系统I”任务如情感分析和文本分类等已被认为成功解决,但讽刺作为一种微妙的语言现象,常通过夸张和比喻等修辞手法传达真实情感和意图,涉及更高层次的抽象。针对LLMs在讽刺理解上的不足,本文选择了11个最先进的LLMs和8个预训练语言模型(PLMs),通过不同的提示方法在六个广泛使用的基准数据集上进行全面评估。结果显示,当前LLMs在讽刺检测上表现不及监督学习的PLMs基准,尤其是GPT-4在各种提示方法中表现优异,平均提升14.0%。
🔬 方法详解
问题定义:本文旨在解决当前大型语言模型在讽刺理解方面的不足,现有方法未能有效捕捉讽刺的复杂性和抽象性。
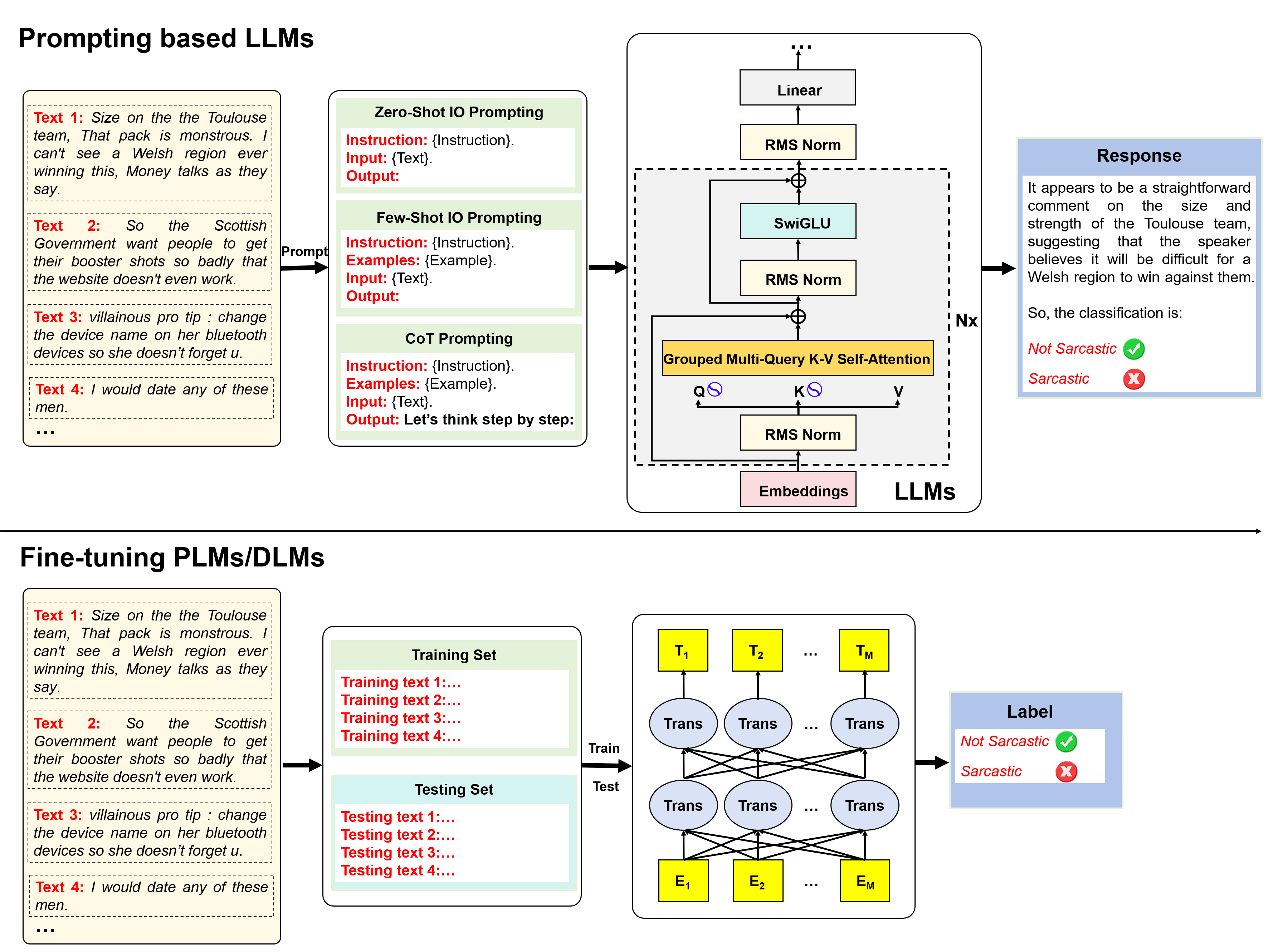
核心思路:通过对11个最先进的LLMs和8个PLMs进行评估,采用零样本、少样本和思维链提示方法,探讨不同提示方式对讽刺理解的影响。
技术框架:整体架构包括数据集选择、模型评估、提示方法设计和结果分析,主要模块涵盖数据预处理、模型推理和性能评估。
关键创新:提出SarcasmBench作为评估LLMs在讽刺理解能力的新基准,强调了讽刺检测的复杂性与现有逻辑推理方法的不同。
关键设计:在实验中,采用了多种提示方法,特别是少样本提示法,显示出其在讽刺检测中的有效性,且对比基线的选择也经过精心设计。
🖼️ 关键图片


📊 实验亮点
实验结果显示,当前LLMs在六个讽刺基准测试中表现不及监督学习的PLMs,尤其是GPT-4在各种提示方法中表现优异,平均提升14.0%。少样本输入/输出提示法在讽刺检测中效果最佳,超越了零样本和思维链提示法。
🎯 应用场景
该研究的潜在应用领域包括社交媒体分析、情感分析和人机交互等,能够帮助改善机器对人类语言中微妙情感的理解,提升用户体验和交互质量。未来,随着LLMs的不断发展,讽刺理解的研究将对自然语言处理领域产生深远影响。
📄 摘要(原文)
In the era of large language models (LLMs), the task of ``System I''~-~the fast, unconscious, and intuitive tasks, e.g., sentiment analysis, text classification, etc., have been argued to be successfully solved. However, sarcasm, as a subtle linguistic phenomenon, often employs rhetorical devices like hyperbole and figuration to convey true sentiments and intentions, involving a higher level of abstraction than sentiment analysis. There is growing concern that the argument about LLMs' success may not be fully tenable when considering sarcasm understanding. To address this question, we select eleven SOTA LLMs and eight SOTA pre-trained language models (PLMs) and present comprehensive evaluations on six widely used benchmark datasets through different prompting approaches, i.e., zero-shot input/output (IO) prompting, few-shot IO prompting, chain of thought (CoT) prompting. Our results highlight three key findings: (1) current LLMs underperform supervised PLMs based sarcasm detection baselines across six sarcasm benchmarks. This suggests that significant efforts are still required to improve LLMs' understanding of human sarcasm. (2) GPT-4 consistently and significantly outperforms other LLMs across various prompting methods, with an average improvement of 14.0\%$\uparrow$. Claude 3 and ChatGPT demonstrate the next best performance after GPT-4. (3) Few-shot IO prompting method outperforms the other two methods: zero-shot IO and few-shot CoT. The reason is that sarcasm detection, being a holistic, intuitive, and non-rational cognitive process, is argued not to adhere to step-by-step logical reasoning, making CoT less effective in understanding sarcasm compared to its effectiveness in mathematical reasoning tasks.