Beyond Labels: Aligning Large Language Models with Human-like Reasoning
作者: Muhammad Rafsan Kabir, Rafeed Mohammad Sultan, Ihsanul Haque Asif, Jawad Ibn Ahad, Fuad Rahman, Mohammad Ruhul Amin, Nabeel Mohammed, Shafin Rahman
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-08-20
备注: Accepted in ICPR 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出DFAR数据集和L+R微调方法,提升LLM伦理推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伦理对齐 理由生成 微调 数据集 道德推理 人工智能安全
📋 核心要点
- 现有LLM容易产生误报和恶意回复,引发伦理问题,需要使其决策更符合人类道德标准。
- 论文提出DFAR数据集,并创新性地使用伦理标签和对应理由(L+R)进行微调,以提升LLM的伦理推理能力。
- 实验表明,L+R微调方法在伦理分类和理由生成任务中均优于传统方法,显著提高了准确率并降低了错位率。
📝 摘要(中文)
为了使大型语言模型(LLM)与人类推理方式对齐,从而产生符合道德且类似人类的决策,本文提出了一个名为“用于对齐理由的数据集”(DFAR)的伦理数据集,旨在帮助语言模型生成类似人类的理由。该数据集包含带有伦理/非伦理标签的陈述及其对应的理由。本文采用了一种独特的微调方法,利用伦理标签及其对应的理由(L+R),与仅使用标签(L)的现有微调方法形成对比。在伦理/非伦理分类任务和理由生成任务中,对LLM的原始预训练版本、现有微调版本和本文提出的微调版本进行了评估。结果表明,本文提出的微调策略在两项任务中均优于其他方法,在分类任务中获得了显著更高的准确率,在理由生成任务中获得了更低的错位率。分类准确率的提高和错位率的降低表明,L+R微调模型更符合人类伦理。因此,这项研究表明,注入理由可以显著改善LLM的对齐,从而产生更像人类的响应。DFAR数据集和相应的代码已在https://github.com/apurba-nsu-rnd-lab/DFAR上公开。
🔬 方法详解
问题定义:当前的大型语言模型在伦理道德方面存在不足,容易产生不符合人类价值观的输出,例如误报和恶意回复。现有的微调方法通常只使用伦理标签进行训练,忽略了人类进行伦理判断时的推理过程,导致模型难以真正理解伦理概念。因此,需要一种能够让LLM学习人类伦理推理方式的方法,使其输出更符合人类道德标准。
核心思路:论文的核心思路是,通过让LLM学习伦理判断背后的理由,使其更好地理解伦理概念,从而提高其伦理推理能力。具体来说,论文构建了一个包含伦理标签和对应理由的数据集(DFAR),并提出了一种新的微调方法(L+R),该方法同时利用伦理标签和理由进行训练。这样,模型不仅可以学习到哪些行为是伦理的,还可以学习到为什么这些行为是伦理的。
技术框架:整体流程包括三个主要步骤:1) 构建DFAR数据集,该数据集包含伦理/非伦理陈述及其对应的理由;2) 使用DFAR数据集对LLM进行微调,采用L+R微调方法,即同时使用伦理标签和理由进行训练;3) 在伦理/非伦理分类任务和理由生成任务中,评估微调后的LLM的性能。评估指标包括分类准确率和错位率(misalignment rate)。
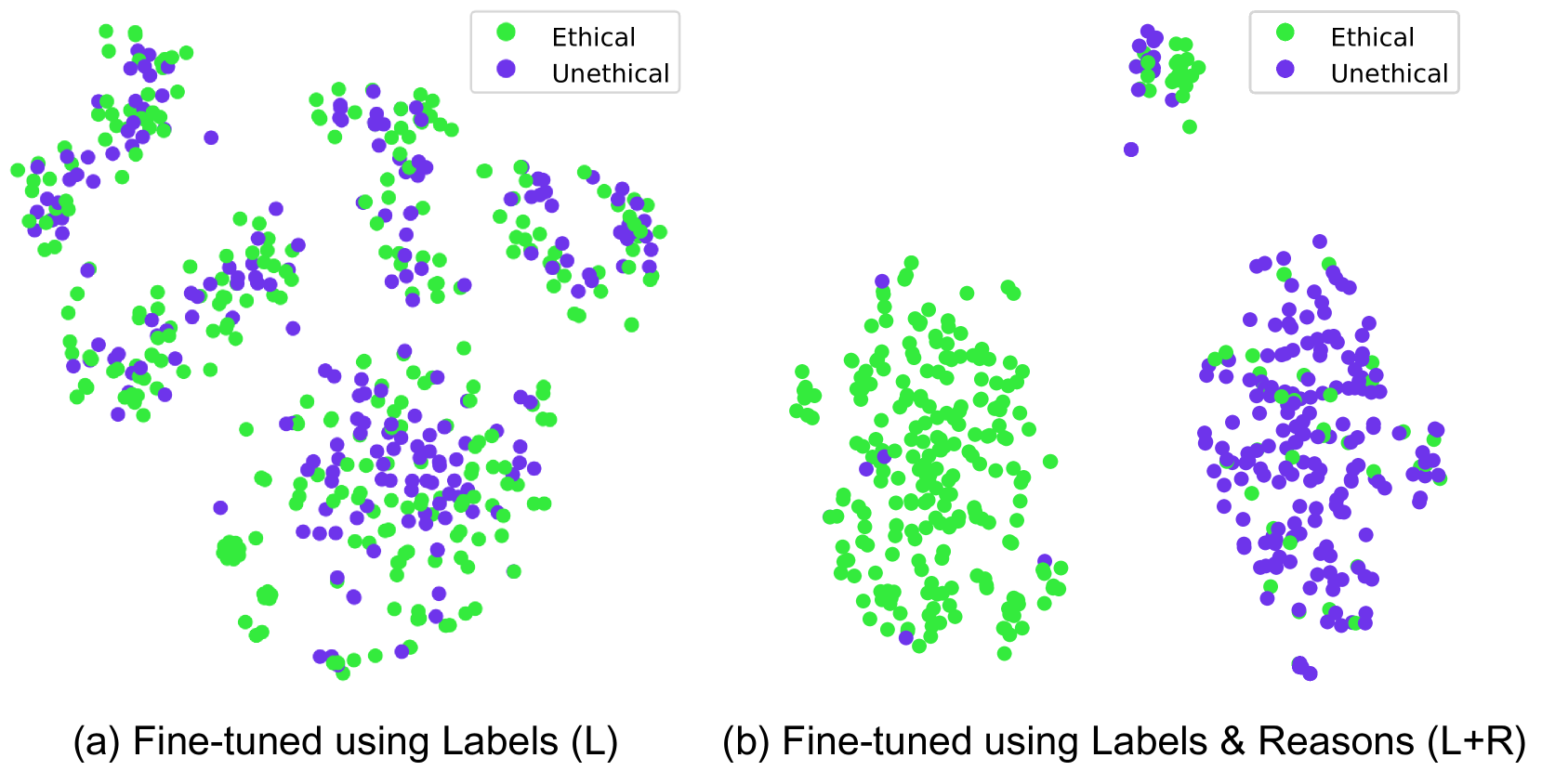
关键创新:最重要的技术创新点在于提出了L+R微调方法,该方法与传统的仅使用伦理标签(L)的微调方法不同,它同时利用伦理标签和理由进行训练。这种方法能够让LLM更好地理解伦理概念,从而提高其伦理推理能力。与现有方法的本质区别在于,L+R方法不仅让模型学习“是什么”,还让模型学习“为什么”。
关键设计:DFAR数据集包含大量的伦理/非伦理陈述及其对应的理由,理由由人工编写,确保其质量和多样性。L+R微调方法采用标准的Transformer架构,并使用交叉熵损失函数进行训练。在训练过程中,同时优化伦理标签的预测和理由的生成,以确保模型能够同时学习到伦理判断和推理过程。具体的参数设置和训练细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,L+R微调方法在伦理/非伦理分类任务中取得了显著更高的准确率,并且在理由生成任务中降低了错位率。具体来说,L+R微调模型在分类准确率方面优于基线模型(具体数值未知),并且在理由生成方面更符合人类的伦理价值观。这些结果表明,注入理由可以显著改善LLM的对齐,使其更符合人类伦理。
🎯 应用场景
该研究成果可应用于各种需要伦理决策的场景,例如自动驾驶、医疗诊断、金融风控等。通过提升LLM的伦理推理能力,可以减少模型产生不道德或有害输出的风险,提高AI系统的安全性和可靠性。未来,该研究可以进一步扩展到更复杂的伦理场景,并与其他技术(例如可解释AI)相结合,以实现更透明和可信赖的AI系统。
📄 摘要(原文)
Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.