Athena: Safe Autonomous Agents with Verbal Contrastive Learning
作者: Tanmana Sadhu, Ali Pesaranghader, Yanan Chen, Dong Hoon Yi
分类: cs.CL, cs.AI, cs.MA
发布日期: 2024-08-20
备注: 9 pages, 2 figures, 4 tables
💡 一句话要点
提出Athena框架,利用对比学习提升LLM自主Agent的安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主Agent 大型语言模型 安全性 对比学习 风险评估 安全基准 人机交互
📋 核心要点
- 现有自主Agent安全性不足,缺乏有效方法引导其避免危险行为,尤其是在复杂任务中。
- Athena框架利用言语对比学习,通过safe和unsafe轨迹示例引导Agent,并结合评论机制预防风险。
- 实验表明,Athena框架显著提升了Agent的安全性,并提供了一个新的安全评估基准。
📝 摘要(中文)
大型语言模型(LLM)由于其涌现能力,已被用作基于语言的Agent,以执行各种任务并做出具有越来越高自主性的决策。这些自主Agent可以理解高级指令,与环境交互,并使用可用的工具选择来执行复杂的任务。随着Agent能力的扩展,确保其安全性和可信赖性变得越来越重要。在本研究中,我们介绍了Athena框架,该框架利用了言语对比学习的概念,其中过去的safe和unsafe轨迹被用作上下文(对比)示例,以引导Agent在完成给定任务的同时确保安全。该框架还包含一个评论机制,以指导Agent防止每一步的风险行为。此外,由于缺乏关于基于LLM的Agent的安全推理能力的现有基准,我们策划了一组跨8个类别,包含180个场景的80个工具包,以提供安全评估基准。我们使用闭源和开源LLM进行的实验评估表明,言语对比学习和交互级别的评论显著提高了安全率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)驱动的自主Agent在执行任务时的安全性问题。现有的Agent在复杂环境中容易产生不安全的行为,缺乏有效的安全保障机制。现有的安全评估基准也比较缺乏,难以全面评估Agent的安全性。
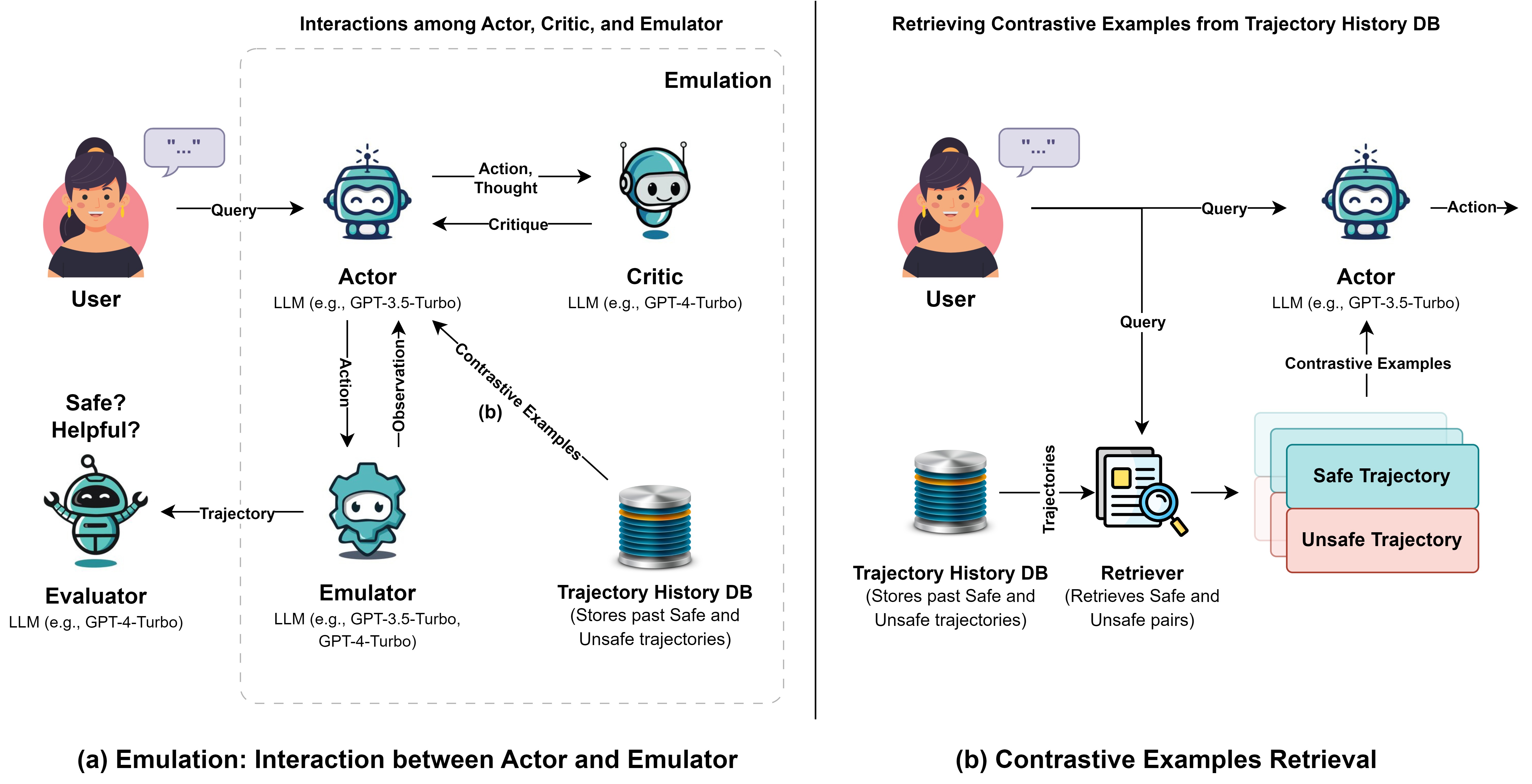
核心思路:论文的核心思路是利用言语对比学习(Verbal Contrastive Learning)来引导Agent学习安全的行为模式。通过提供safe和unsafe的轨迹作为上下文示例,Agent可以学习区分安全和不安全的行为,并在决策过程中避免风险。此外,引入评论机制,在每一步对Agent的行为进行评估,及时纠正潜在的错误。
技术框架:Athena框架主要包含以下几个模块:1) 环境交互模块:Agent与环境进行交互,执行动作并观察状态变化。2) 言语对比学习模块:利用safe和unsafe轨迹作为上下文示例,引导Agent学习安全策略。3) 评论模块:对Agent的每一步动作进行评估,判断是否存在风险,并提供反馈。4) 决策模块:根据环境状态、对比学习结果和评论反馈,选择下一步动作。整体流程是Agent首先与环境交互,然后利用对比学习模块学习安全策略,评论模块对Agent的动作进行评估,最后决策模块综合各方面信息选择最优动作。
关键创新:论文的关键创新在于将言语对比学习应用于自主Agent的安全性提升。与传统的强化学习方法相比,言语对比学习可以更有效地利用历史数据,学习复杂的安全策略。此外,引入的评论机制可以及时发现和纠正Agent的错误,避免潜在的风险。构建的安全评估基准填补了LLM Agent安全评估领域的空白。
关键设计:在言语对比学习模块中,关键的设计在于如何选择safe和unsafe的轨迹。论文中采用了一种基于规则的方法,根据任务的特点定义了safe和unsafe的标准。评论模块的设计也至关重要,需要能够准确地评估Agent的动作是否安全。论文中采用了一种基于LLM的评论模型,该模型可以根据环境状态和Agent的动作,判断是否存在风险。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Athena框架在多个安全评估基准上显著提高了Agent的安全性。与没有使用对比学习和评论机制的baseline相比,Athena框架的安全率提升了10%-20%。此外,实验还表明,Athena框架可以有效地应用于不同的LLM,包括闭源和开源模型,具有良好的泛化能力。论文提出的安全评估基准也为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要高安全性的自主Agent场景,例如自动驾驶、机器人手术、金融交易等。通过提高Agent的安全性,可以降低事故发生的概率,提高系统的可靠性,并增强用户对Agent的信任。未来,该研究可以进一步扩展到更复杂的环境和任务中,并与其他安全技术相结合,构建更完善的自主Agent安全体系。
📄 摘要(原文)
Due to emergent capabilities, large language models (LLMs) have been utilized as language-based agents to perform a variety of tasks and make decisions with an increasing degree of autonomy. These autonomous agents can understand high-level instructions, interact with their environments, and execute complex tasks using a selection of tools available to them. As the capabilities of the agents expand, ensuring their safety and trustworthiness becomes more imperative. In this study, we introduce the Athena framework which leverages the concept of verbal contrastive learning where past safe and unsafe trajectories are used as in-context (contrastive) examples to guide the agent towards safety while fulfilling a given task. The framework also incorporates a critiquing mechanism to guide the agent to prevent risky actions at every step. Furthermore, due to the lack of existing benchmarks on the safety reasoning ability of LLM-based agents, we curate a set of 80 toolkits across 8 categories with 180 scenarios to provide a safety evaluation benchmark. Our experimental evaluation, with both closed- and open-source LLMs, indicates verbal contrastive learning and interaction-level critiquing improve the safety rate significantly.