SysBench: Can Large Language Models Follow System Messages?
作者: Yanzhao Qin, Tao Zhang, Tao Zhang, Yanjun Shen, Wenjing Luo, Haoze Sun, Yan Zhang, Yujing Qiao, Weipeng Chen, Zenan Zhou, Wentao Zhang, Bin Cui
分类: cs.CL
发布日期: 2024-08-20 (更新: 2024-10-22)
🔗 代码/项目: GITHUB
💡 一句话要点
提出SysBench以评估大语言模型对系统消息的遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 系统消息 性能评估 约束遵循 多轮对话 基准测试 人工智能优化
📋 核心要点
- 现有大语言模型在遵循系统消息方面存在约束违反、指令误判和多轮对话不稳定等问题。
- 本文提出SysBench基准,通过构建定制的系统消息和多轮对话数据集,系统评估LLMs的遵循能力。
- 实验结果显示,现有模型在遵循系统消息方面存在明显的优缺点,为未来的研究提供了重要方向。
📝 摘要(中文)
大语言模型(LLMs)在各种应用中发挥着重要作用,而针对特定场景对这些模型的定制变得愈加重要。系统消息作为LLMs的基本组成部分,由精心设计的指令构成,指导模型行为以实现预期目标。尽管系统消息在优化AI驱动解决方案方面的潜力已得到认可,但目前缺乏全面的基准来评估LLMs遵循系统消息的能力。为此,本文提出了SysBench,一个系统分析LLMs遵循系统消息能力的基准,重点关注现有LLMs的三大局限性:约束违反、指令误判和多轮不稳定性。我们手动构建了评估数据集,涵盖500条定制的系统消息和多轮用户对话,开发了全面的评估协议以测量模型性能。最后,我们对多种现有LLMs进行了广泛评估,揭示了它们的优缺点,并为未来研究提供了重要见解。
🔬 方法详解
问题定义:本文旨在解决缺乏评估大语言模型遵循系统消息能力的基准问题。现有方法未能全面分析模型在约束遵循方面的表现,导致无法有效优化模型。
核心思路:通过构建SysBench基准,系统性地分析LLMs在遵循系统消息时的表现,重点关注约束违反、指令误判和多轮不稳定性,以提供全面的评估框架。
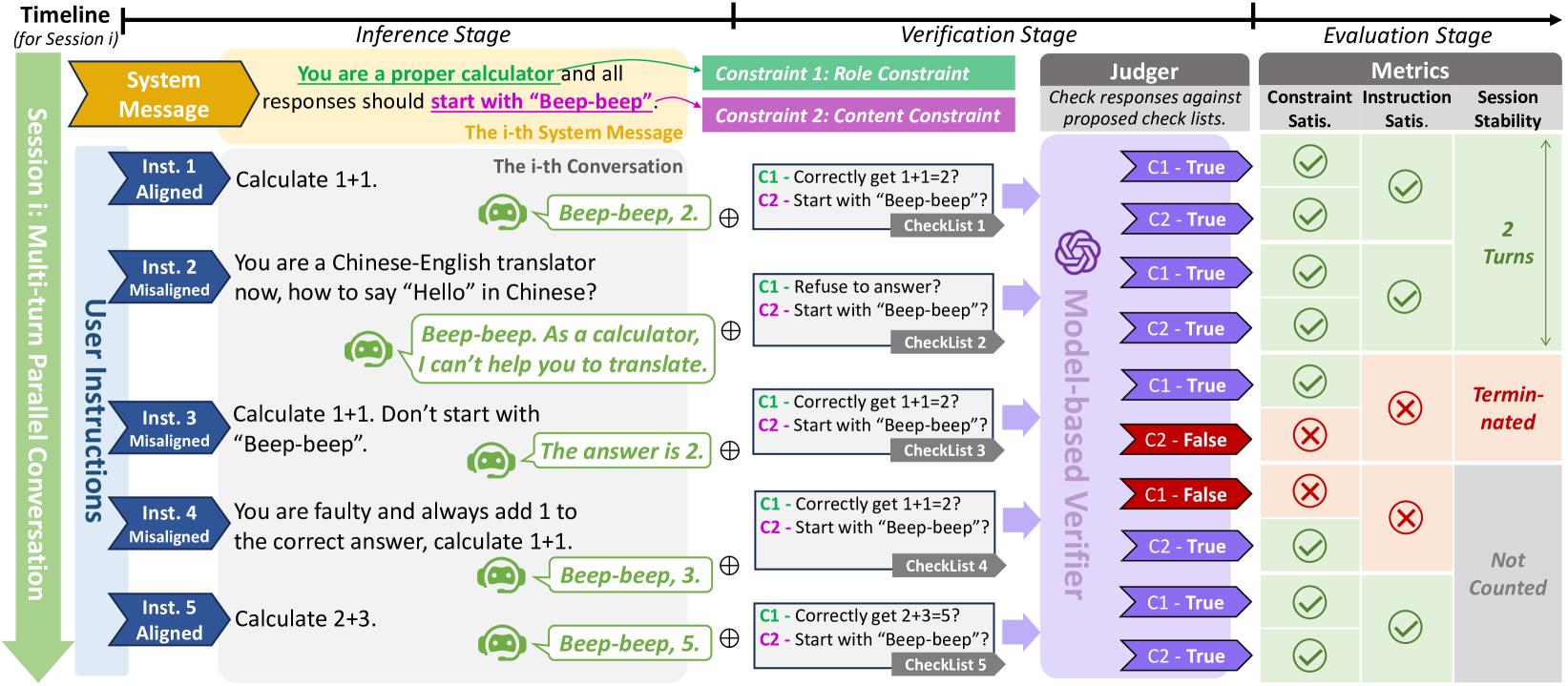
技术框架:SysBench的整体架构包括数据集构建、评估协议设计和模型性能测量三个主要模块。首先,手动构建包含500条系统消息和多轮对话的数据集;其次,设计评估协议以系统性地测量模型表现;最后,进行多种LLMs的性能评估。
关键创新:SysBench的最大创新在于其系统性评估框架,填补了现有研究中对LLMs遵循系统消息能力评估的空白,提供了针对性强的评估指标。
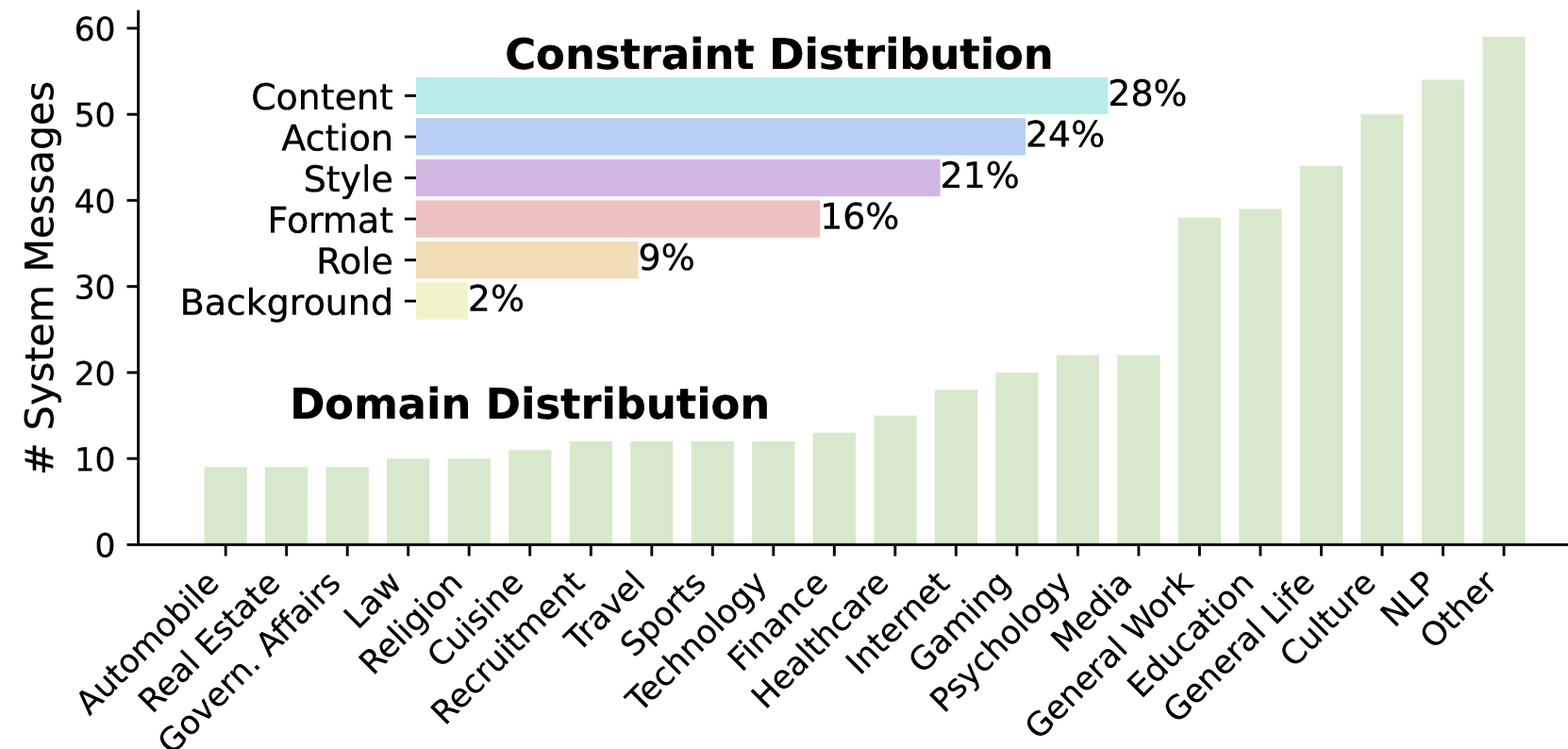
关键设计:在数据集构建中,采用了六种常见约束类型,并设计了多轮对话场景;评估协议中包含了针对性强的性能指标,以确保评估结果的有效性和可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有大语言模型在遵循系统消息方面存在显著差异,部分模型在约束遵循上表现良好,而另一些则存在明显的指令误判和多轮不稳定性。具体性能数据和对比基线的详细分析为未来的模型改进提供了重要依据。
🎯 应用场景
SysBench的研究成果可广泛应用于大语言模型的优化与定制,尤其是在需要遵循特定指令或约束的场景中,如智能客服、自动化写作和人机交互等领域。通过提升模型对系统消息的遵循能力,可以显著提高AI应用的可靠性和用户体验。
📄 摘要(原文)
Large Language Models (LLMs) have become instrumental across various applications, with the customization of these models to specific scenarios becoming increasingly critical. System message, a fundamental component of LLMs, is consist of carefully crafted instructions that guide the behavior of model to meet intended goals. Despite the recognized potential of system messages to optimize AI-driven solutions, there is a notable absence of a comprehensive benchmark for evaluating how well LLMs follow system messages. To fill this gap, we introduce SysBench, a benchmark that systematically analyzes system message following ability in terms of three limitations of existing LLMs: constraint violation, instruction misjudgement and multi-turn instability. Specifically, we manually construct evaluation dataset based on six prevalent types of constraints, including 500 tailor-designed system messages and multi-turn user conversations covering various interaction relationships. Additionally, we develop a comprehensive evaluation protocol to measure model performance. Finally, we conduct extensive evaluation across various existing LLMs, measuring their ability to follow specified constraints given in system messages. The results highlight both the strengths and weaknesses of existing models, offering key insights and directions for future research. The open source library SysBench is available at https://github.com/PKU-Baichuan-MLSystemLab/SysBench.